My unedited org-noter notes from the classic book “Fluent Python – Clear, Concise, and Effective Programming” by Luciano Ramalho.
The notes for this are messy, sorry about that. There are some chapters I could not get time to finish so they are left as TODOs for now.
Outline and Notes
Each chapter’s summary page is really useful. We should always start with the summary if we were to review these topics in the future, having already read them at least once before.
The things that are useful and I want to create a habit for, I write a coment with the word: “TO_HABIT” so that we can search it easily.
Part I. Data Structures
Chapter 1. The Python Data Model
Seeing python as a “framework”
This gives us some use cases / purpose for implementing special methods to interface w python as a “framework”
the special methods are dunder methods
We implement special methods when we want our objects to support and interact with fundamental language constructs such as: • Collections • Attribute access • Iteration (including asynchronous iteration using async for) • Operator overloading • Function and method invocation • String representation and formatting • Asynchronous programming using await • Object creation and destruction • Managed contexts using the with or async with statements
What’s New in This Chapter
A Pythonic Card Deck
this is a demonstrative example on how we can adapt to the “interface” for the “framework” that is python.
Class Composition and how Delegation pattern in the data model helps
our getitem delegates to the [] operator of self._cards, our deck automatically supports slicing. Here’s
- The use of base classes allows OOP benefits for us such as being able to delegate functionality.
- Delegation is different from forwarding
- this python example is closer to the concept of “forwarding” actually
| |
How Special Methods Are Used
- NOTE: built-ins that are variable sized under the hood have an
ob_sizeattribute that holds the size of that collection. This makes it faster to calllen(my_object)since it’s not really a function call, the interpreter just reads off the pointer.
- Emulating Numeric Types
- it’s all about implementing the number-class related dunder methods, then anything can behave like a number
- String Representation
__repr__
- repr is different from string in the sense that it’s supposed to be a visual representation of the creation of that object. Therefore, it should be unambiguous, and if possible, match source code necessary to recreate the represented object
- repr is not really for display purposes, that’s what
strbuiltin is for - implement the special function
reprfirst thenstr
- String Representation
- Boolean Value of a Custom Type
default: forward to bool() elif len()
By default, instances of user-defined classes are considered truthy, unless either bool or len is implemented. Basically, bool(x) calls x._bool_() and uses the result. If bool is not implemented, Python tries to invoke x._len_(), and if that returns zero, bool returns False. Otherwise bool returns True.
- Collection API
The collections api is new, and it unifies the 3 following interfaces: • Iterable to support for, unpacking, and other forms of iteration • Sized to support the
lenbuilt-in function • Container to support theinoperatorThere’s no need to inherit from these ABCs specifically, as long as the dunder methods are implemented then it’s considered as satisfying the ABC
Specialisations of Collection
Three very important specializations of Collection are: • Sequence, formalizing the interface of built-ins like list and str • Mapping, implemented by dict, collections.defaultdict, etc. • Set, the interface of the set and frozenset built-in types
I want to use the vocabulary here when describing what primitives I want to use.
python dicts are “ordered” in the sense that the insertion order is preserved
- there’s nothing else we can do about the ordering property (e.g. manipulating[rearranging] the order and such)
Overview of Special Methods
- there’s a bunch, the latest ones are more on the async support side, they will be covered throughout the book
Why len Is Not a Method
“Practicality beats purity”.
- there’s no method call for
len(x)when x is a CPython built-in because it’s a direct read of a C-struct - for custom objects, we can implement the dunder method
__len__ - it kinda looks like a functional style (since len is a fn) in a OOP-styled language. To reconcile this, we can think of
absandlenas unary functions!
Chapter Summary
Further Reading
Python’s DataModel can be seen as a MetaObject Protocol
Metaobjects The Art of the Metaobject Protocol (AMOP) is my favorite computer book title. But I mention it because the term metaobject protocol is useful to think about the Python Data Model and similar features in other languages. The metaobject part refers to the objects that are the building blocks of the language itself. In this context, protocol is a synonym of interface. So a metaobject protocol is a fancy synonym for object model: an API for core language constructs.
Chapter 2. An Array of Sequences
What’s New in This Chapter
Overview of Built-in Sequences
- two factors to group sequences by:
- by container (heterogeneous) / flat (homogeneous) sequences
- Container sequences: can be heterogeneous
- holds references (“pointers”)
- Flat sequences: are homogeneous
- holds values
- Container sequences: can be heterogeneous
- by mutability / immutability
- by container (heterogeneous) / flat (homogeneous) sequences
- things like generators can be seen in the context of sequences themselves “To fill up sequences of any type”
Mem Representation for Python Objects: have a header (with metadata) and value
example of meta fields (using float as a reference):
- refcount
- type
- value
Every Python object in memory has a header with metadata. The simplest Python object, a float, has a value field and two metadata fields: • ob_refcnt: the object’s reference count • ob_type: a pointer to the object’s type • ob_fval: a C double holding the value of the float On a 64-bit Python build, each of those fields takes 8 bytes. That’s why an array of floats is much more compact than a tuple of floats: the array is a single object holding the raw values of the floats, while the tuple consists of several objects—the tuple itself and each float object contained in it.
List Comprehensions and Generator Expressions
List Comprehensions and Readability
- a loop has generic purpose, but a listcomp’s purpose is always singular: to build a list
- we should stick to this purpose and not introduce abuse mechanisms like adding in side-effects from listcomp evaluations
- List comprehensions build lists from sequences or any other iterable type by filtering and transforming items.
Scope: listcomps have a local scope, use walrus operator to expand the scope to its outer frame
``Local Scope Within Comprehensions and Generator Expressions''
if that name is modified using global or nonlocal, then the scope is accordingly set
defines the scope of the target of := as the enclos‐ ing function, unless there is a global or nonlocal declaration for that target.
- Listcomps Versus map and filter
Cartesian Products
This is the part where we have more than one iterable within the listcomp
- Generator Expressions
Tuples Are Not Just Immutable Lists
The immutable list part is definitely one of the main features.
It should also be seen as a nameless record.
Tuples as Records
- some examples of tuple unpacking:
- the loop constructs automatically support unpacking, we can assign vars even for each iteration of the loop
- the
%formatting operator will also unpack values within the tuple when doing string formats
- some examples of tuple unpacking:
Tuples as Immutable Lists
2 benefits:
- clarity: the length of tuple is fixed thanks to its immutability
- performance: memory use is a little better, also allows for some optimisations
Warning: the immutability is w.r.t references contained within the tuple, not values
So tuples containing mutable items can be a source of bugs Also, unhashable tuple => can’t be inserted as a dict key or set
Tuple’s Performance Efficiency Reasons
Tuples are more efficient because:
- bytecode: tuple has simpler bytecode required: Python compiler generates bytecode for a tuple constant in one operation; but for a list literal, the generated bytecode pushes each element as a separate constant to the data stack, and then builds the list.
- constructor:
tuple construction from existing doesn’t need any copying, it’s the same reference:
- the list constructor returns a copy of a given list if its
list(l) - tuple constructor returns a reference to the same
tif we dotuple(t)(because they’re immutable anyway so why not same reference)
- the list constructor returns a copy of a given list if its
- amortisation: tuple, since fixed size, doesn’t need to account for future size changes by amortising that operation
- no extra layer of indirection The references to the items in a tuple are stored in an array in the tuple struct,while a list holds a pointer to an array of references stored elsewhere. The indirection is necessary because when a list grows beyond the space currently allocated, Python needs to reallocate the array of references to make room. The extra indirection makes CPU caches less effective.
- Comparing Tuple and List Methods
Unpacking Sequences and Iterables
- safer extraction of elements from sequences
- works with any iterable object as the datasource, including iterators.
- for the iterable case, as long as the iterable yields exactly one item per variable in the receiving end (or
*is used to do a glob capture)
- for the iterable case, as long as the iterable yields exactly one item per variable in the receiving end (or
Parallel assignment
This is the multi-name assignments that we do, and how involves sequence unpacking
most visible form of unpacking is parallel assignment; that is, assigning items from an iterable to a tuple of variables, as you can see in this example: >>> lax_coordinates = (33.9425, -118.408056) >>> latitude, longitude = lax_coordinates # unpacking >>> latitude
Using * to Grab Excess Items
- classic case is the use of the grabbing part for varargs
- context of parallel assignment, the
*prefix can be applied to exactly one variable, but it can appear in any position
Unpacking with * in Function Calls and Sequence Literals
- the use of the unpacking operator is context-dependent, so in the context of function calls and the creation of sequences, they can be used multiple times. In the context of parallel asisgnment, it’s a singular use (else there’s going to be ambiguity on how to partition values in the sequence)
- Nested Unpacking
GOTCHA: single-item tuple syntax may have silent bugs if used improperly
Both of these could be written with tuples, but don’t forget the syntax quirk that single-item tuples must be written with a trailing comma. So the first target would be (record,) and the second ((field,),). In both cases you get a silent bug if you forget a comma.
Pattern Matching with Sequences
Pattern matching is an example of declarative programming: the code describes “what” you want to match, instead of “how” to match it. The shape of the code follows the shape of the data, as Table 2-2 illustrates.
- here’s the OG writeup for structural pattern matching. Some points from it:
- Therefore, an important exception is that patterns don’t match iterators. Also, to prevent a common mistake, sequence patterns don’t match strings.
- the matching primitives allow us to use guards on the match conditions (see here)
- there’s support for defining sub-patterns like so:
1case (Point(x1, y1), Point(x2, y2) as p2): ...
- here’s a more comprehensive tutorial PEP 636 - Structural Pattern Matching
Pattern-matching is declarative
Pattern matching is an example of declarative programming: the code describes “what” you want to match, instead of “how” to match it. The shape of the code fol‐ lows the shape of the data, as Table 2-2 illustrates.
python’s
matchgoes beyond just being aswitchstatement because it supports destructuring similar to elixir- random thought: this features is really useful if we were to write out a toy interpreter for some source code. Here’s lis.py
On the surface, match/case may look like the switch/case statement from the C lan‐ guage—but that’s only half the story.4 One key improvement of match over switch is destructuring—a more advanced form of unpacking. Destructuring is a new word in the Python vocabulary, but it is commonly used in the documentation of languages that support pattern matching—like Scala and Elixir. As a first example of destructuring, Example 2-10 shows part of Example 2-8 rewrit‐ ten with match/case.
class-patterns gift us the ability to do runtime type checks
1case [str(name), _, _, (float(lat), float(lon))]:the constructor-like syntax is not a constructor, it’s a runtime check
the names (
name,lat,lon) are binded here and are available for referencing thereafter within the codeblockthis is really interesting, it’s in the context of patterns that the syntax does runtime type checking and the code does
The expressions str(name) and float(lat) look like constructor calls, which we’d use to convert name and lat to str and float. But in the context of a pattern, that syntax performs a runtime type check: the preceding pattern will match a four-item sequence in which item 0 must be a str, and item 3 must be a pair of floats. Additionally, the str in item 0 will be bound to the name variable, and the floats in item 3 will be bound to lat and lon, respectively. So, although str(name) borrows the syntax of a constructor call, the semantics are completely different in the context of a pattern. Using arbitrary classes in patterns is covered in “Pattern Matching Class Instances” on page 192.
Pattern Matching Sequences in an Interpreter
it’s interesting how the python 2 code was described as “a fan of pattern matching” because it matches on the first element and then the tree of control flow paths does their job, so it’s really like a switch
this switch-like pattern-matching style is something abstract even more so than in it’s concrete programming language implementation that we have been discussing so far
the catch-all is used for error-handling purposes here. In general there should always be a fallthrough case instead of going for no-ops which will end up being more silent
Slicing
Why Slices and Ranges Exclude the Last Item
this refers to the fact that one end of the range is closed (inclusive) and the other is open (exclusive).
- easy to calculate lengths
- easy to split / partition without creating overlaps
Slice Objects
- useful to know this because it lets you assign names to slices, like spreadsheets allow the naming of cell-ranges
Multidimensional Slicing and Ellipsis
This is more useful in the context of numpy lib, the book doens’t include examples here for the python stdlib
- built-ins are single dim, except for memoryview Except for memoryview, the built-in sequence types in Python are one-dimensional, so they support only one index or slice, and not a tuple of them.
- Multiple indexes or slices get passed in as tuples
a[i,j]is evaluated asa.__getitem__((i,j))e.g. numpy multi-dim array accesses ellipsisclass is a singleton, the sole object beingElipsis- a similar case is
boolclass andTrue,False
- a similar case is
- so in numpy, if x is a four-dimensional array,
x[i, ...]is a shortcut forx[i, :, :, :,]
Assigning to Slices
Applies to mutable sequences.
Gotcha: when LHS of assignment is slice, the RHS must be iterable
In the example below, we’re trying to graft some sequence to another. With that intent, we can only graft an iterable onto another sequence, not a single element. Hence, the requirement that the RHS must be iterable.
1 2 3 4 5 6 7 8 9 10 11 12l = list(range(10)) try: # so this is wrong: l[2:5] = 100 except: print("this will throw an error, we aren't passing in an iterable for the grafting.") finally: # and this is right l[2:5] = [100] print(l)
Using + and * with Sequences
- both
+and-create new objects without modding their operands
Building Lists of Lists
Gotcha: Pitfall of references to mutable objects – using
a * nwhere a contains sequence of mutable items can be problematicActually applies to other mutable sequences as well, in this case it’s just a list that we’re using
Just be careful what the contained element’s properties are like.
1 2 3 4 5 6 7 8 9 10 11my_mutable_elem = ['apple', 'banana'] print(f"my mutable elem ref: {id(my_mutable_elem)}") list_of_lists = [ my_mutable_elem ] * 2 print(f"This creates 2 repeats \n{list_of_lists}") print(f"(first ref, second ref) = {[id(elem) for elem in list_of_lists]}") list_of_lists[0][0] = 'strawberry' print(f"This mods all 2 repeated refs \n{list_of_lists}") print(f"(first ref, second ref) = {[id(elem) for elem in list_of_lists]}")Here’s the same gotcha using tic-tac-toe as an example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20good_board = [['_'] * 3 for i in range(3)] bad_board = [['_'] * 3] * 3 print(f"BEFORE, the boards look like this:\n\ \tGOOD Board:\n\ \t{ [row for row in good_board] }\n\ \tBAD Board:\n\ \t{ [row for row in bad_board] }\n") # now we make a mark on the boards: good_board[1][2] = 'X' bad_board[1][2] = 'X' print(f"AFTER, the boards look like this:\n\ \tGOOD Board:\n\ \t{ [row for row in good_board] }\n\ \tBAD Board:\n\ \t{ [row for row in bad_board] }\n")
Augmented Assignment with Sequences
This refers to the in-place versions of the sequence operators. in ==, there are 2 cases:
Case A: Identity of
achanges- the dunder method
__iadd__was not available for use - so
a + bhad to be evaluated and stored as a new id - and that id was then referenced by
aas part of the new assignment
- the dunder method
Case B: Identity of
adoes not change- this would mean that
ais actually mutated in-place - it would have used the dunder method
__iadd__
- this would mean that
In other words, the identity of the object bound to a may or may not change, depending on the availability of
__iadd__.In general, for mutable sequences, it is a good bet that
__iadd__is implemented and that += happensdoing += for repeated concats of immutable sequences is inefficient
however, str contacts have been optimised in CPython, it’s alright to do that in CPython. Extra space would have been allocated to amortise the new space allocations.
A += Assignment Puzzler
Learnings!
I take three lessons from this:
• Avoid putting mutable items in tuples.
• Augmented assignment is not an atomic operation—we just saw it throwing an exception after doing part of its job.
• Inspecting Python bytecode is not too difficult, and can be helpful to see what is going on under the hood.
Example
it’s a peculiarity in the += operator!
Learnings:
I take three lessons from this:
• Avoid putting mutable items in tuples.
• Augmented assignment is not an atomic operation—we just saw it throwing an exception after doing part of its job.
• Inspecting Python bytecode is not too difficult, and can be helpful to see what is going on under the hood.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17t = (1,2, [30, 40]) print(t) try: t[2] += [50, 60] except: print("LMAO complaints") finally: print(t) try: t[2].extend([90, 100]) except: print("this won't error out though") finally: print(t)
list.sort Versus the sorted Built-In
in-place functions should return
Noneas a conventionThere’s a drawback to this: we can’t cascade calls to this method
- python’s sorting uses timsort!
Managing Ordered Sequences with bisect (extra ref from textbook)
When a List Is Not the Answer
Arrays: best for containing numbers
- an array of float values does not hold full-fledged float instances, but only the packed bytes representing their machine values—similar to an array of double in the C language.
- examples:
- typecode b => byte => 8 bits over signed and unsigned regions ==> [-128, 127] range of representation
- for special cases of numeric arrays for bin data (e.g. raster images),
bytesandbytearraytypes are more appropriate!
Memory Views
Examples
id vs context
The learning from this is that the
memoryviewobjects and the memory that they provide a view of are two different regions of memory. id vs context.So here, m2, m3 and all have different id references, but the memory region that they give a view of is all the same.
That’s why we can mutate using one memory view and every other view also reflects that change.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32from array import array # just some bytes, the sequence is buffer-protocol-adherent octets = array("B", range(6)) print(octets) # builds a new memoryview from the array m1 = memoryview(octets) print(m1) # exporting of a memory view to a list, this creates a new list (a copy!) print(m1.tolist()) # builds a new memoryview, with 2 rows and 3 columns m2 = m1.cast('B', [2,3]) print(m2) print(m2.tolist()) m3 = m1.cast('B', [3,2]) print(m3) print(m3.tolist()) # overwrite byte m2[1,1] = 22 # overwrite byte m3[1,1] = 33 print(f"original memory has been changed: \n\t{octets} ") print(f"m1 has been changed:\n\t { m1.tolist() }") print(f"m2 has been changed:\n\t { m2.tolist() }") print(f"m3 has been changed:\n\t {m3.tolist()}")
corruption
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35from array import array from sys import byteorder print(byteorder) numbers = array('h', [-2,-1,0,1,2]) memv = memoryview(numbers) print(len(memv)) print(memv[0]) # cast the half as a byte, so the resultant sequence will have double the elements: memv_oct = memv.cast('B') # the numbers are stored in little endian format print(memv_oct.tolist()) # so -2 as a 2-byte signed short will be (little endian binary) 0xfe 0xff (254, 255) # so we get: # -2: 0xfe 0xff (254, 255) # -1: 0xff 0xff (255, 255) # 0: 0x00 0x00 (0, 0) # 1: 0x01 0x00 (1, 0) # 2: 0x02 0x00 (2, 0) # asisgns the value of 4 to byte-offset 5 memv_oct[5] = 4 print( numbers ) # so this change is to the 2nd byte of the third element of numbers # byte index 5 is the high byte (since it's little endian so bytes are low -> high) # so the 3rd element is now [0, 0x0400] # = a + (b*256) = 0 + (4 * 256) is 1024 in decimal # NOTE: Note the change to numbers: a 4 in the most significant byte of a 2-byte unsigned # integer is 1024.
Extra: “Parsing binary records with struct”
Some takeaways:
- Proprietary binary records in the real world are brittle and can be corrupted easily. examples:
- string parsing: paddings, null terminated, size limits?
- endianness problem: what byteorder was used for representing integers and floats (CPU-architecture-dependent)?
- always explore pre-built solutions first instead of building yourself:
- for data exchange,
picklemodule works great, but have to ensure python versions align since the default binary formats may be different. Reading a pickle also may run arbitrary code.
- for data exchange,
- if the binary exchange uses multiple programming languages, standardise the serialisation. Serial forms:
- multi-platform binary serialisation formats:
- JSON
- Proprietary binary records in the real world are brittle and can be corrupted easily. examples:
bot assisted concept mapping
Here’s a bot-assisted concept map between unix
mmapandmemoryviews:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64Memory mapping a file is a powerful technique that allows access to file data as if it were in memory, and the concepts connect naturally between the Unix world (via `mmap` system calls) and Python (via the `mmap` module and `memoryview` objects). **Unix World: mmap** - **Definition:** The Unix `mmap` system call maps files or devices into a process's address space, enabling file I/O by reading and writing memory. This is efficient for large files because data is loaded on demand, and multiple processes can share the same mapped region[1]. - **Usage:** After opening a file, `mmap` associates a region of virtual memory with the file. Reading and writing to this memory behaves as if you were reading and writing to the file itself. The system manages when data is actually read from or written to disk, often using demand paging[1]. - **Types:** Both file-backed (mapping a file) and anonymous (not backed by a file, similar to dynamic allocation) mappings are supported. Shared mappings allow interprocess communication, while private mappings isolate changes to one process[1]. **Python World: mmap Module** - **Definition:** Python’s `mmap` module provides a high-level interface to memory-mapped files, closely mirroring the Unix `mmap` functionality. You must provide a file descriptor (from `fileno()` or `os.open()`) and specify the mapping size and access mode[2][3]. - **Usage:** Memory-mapped file objects behave like both file objects and mutable byte arrays, allowing random access and slicing. You can read and write data by indexing or slicing, and you can seek through the file as if it were a standard file object[2][3]. - **Access Modes:** You can specify read-only, write-through (changes go directly to the file), or copy-on-write (changes are local)[4][5]. **Python World: memoryview** - **Definition:** The `memoryview` object provides a safe way to access the internal data of an object that supports the buffer protocol, such as `bytes`, `bytearray`, or a memory-mapped file object[6]. - **Usage:** With a `memoryview`, you can manipulate large data structures without copying them, which is especially useful for memory-mapped files. It allows you to pass a view of the data to functions or slice it efficiently, avoiding unnecessary memory duplication[6]. - **Connection to mmap:** When you create a memory-mapped file in Python, you can use `memoryview` to work with the data as a buffer, enabling efficient manipulation and sharing of large data sets. **Linking the Concepts** - **Memory Mapping:** Both Unix `mmap` and Python’s `mmap` module allow you to treat file data as if it were in memory, enabling efficient random access and sharing between processes[1][2][3]. - **Efficient Data Access:** Using `memoryview` in Python is analogous to working directly with the mapped memory region in Unix, as both avoid copying large chunks of data and allow efficient manipulation of file contents[6]. - **Interprocess Communication:** In Unix, shared memory mappings (`MAP_SHARED`) allow processes to communicate by reading and writing the same memory region. In Python, you can achieve similar effects by sharing a memory-mapped file object between processes[1][2]. - **Performance:** Both approaches leverage the operating system’s memory management to reduce I/O overhead and enable fast, random access to file data. **Summary Table** | Concept | Unix (`mmap`) | Python (`mmap` module) | Python (`memoryview`) | |------------------------|------------------------------|-----------------------------------|-------------------------------| | Purpose | Map files to memory | Map files to memory | View memory as buffer | | Access Method | System call | Module/object | Object | | Sharing | Shared/private mappings | Shared via file object | View of existing buffer | | Efficiency | Demand paging, no copy | Demand paging, no copy | No copy, efficient slicing | | Use Case | IPC, efficient file I/O | Efficient file I/O, IPC | Efficient data manipulation | By understanding these connections, you can leverage memory mapping for efficient file handling and data sharing across both Unix and Python environments. [1] https://en.wikipedia.org/wiki/Mmap [2] https://docs.python.org/3/library/mmap.html [3] https://github.com/python/cpython/blob/master/Doc/library/mmap.rst [4] https://pymotw.com/3/mmap/ [5] https://realpython.com/python-mmap/ [6] https://smart-spatial.com/data%20science/2017/09/22/MemoryView/ [7] https://stackoverflow.com/questions/63553692/how-to-use-memory-mapped-file-in-python-linux/63554607 [8] https://pymotw.com/3/mmap/index.html [9] https://unix.stackexchange.com/questions/712651/does-mmap-allow-creating-a-mapping-that-is-much-larger-than-the-amount-of-physic [10] https://deepaksood619.github.io/computer-science/operating-system/memory-mapping-mmap/ [11] https://www.cmi.ac.in/~madhavan/courses/prog2-2012/docs/python-3.2.1-docs-html/library/mmap.html [12] https://www.blopig.com/blog/2024/08/memory-mapped-files-for-efficient-data-processing/ [13] https://stackoverflow.com/questions/4991533/sharing-memory-between-processes-through-the-use-of-mmap/4991631 [14] https://documentation.help/Python-2.4/module-mmap.html [15] https://docs.python.org/3.4/library/mmap.html?highlight=mmap [16] https://www.ibm.com/docs/en/zos/2.4.0?topic=functions-mmap-map-pages-memory [17] https://man7.org/linux/man-pages/man2/mmap.2.html [18] https://programmingappliedai.substack.com/p/what-is-mmap-in-linux-and-how-it [19] https://w3.cs.jmu.edu/kirkpams/OpenCSF/Books/csf/html/MMap.html [20] https://www.ibm.com/docs/ssw_ibm_i_74/apis/mmap.htm [21] https://www.unix.com/man-page/linux/3/mmap/ [22] https://stackoverflow.com/questions/47437481/python-can-i-get-a-memoryview-or-a-bytearray-mapping-to-a-mmap [23] https://docs.vultr.com/python/built-in/memoryview [24] https://pymotw.com/2/mmap/ [25] https://www.youtube.com/watch?v=ky1n6luzL3Y
“casting” in memoryview vs Elixir ecto “casting”
The mental models are different.
“casting” with memoryview is about interpreting memory as a different type, not about automatic type conversion or validation as in Elixir changesets. The term is used more loosely in Python, while in Elixir, it is a formal, declarative operation for data preparation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37The use of the term **"cast"** in the context of Python `memoryview` is not the same as in Elixir changesets, even though both involve types or transformations. **Python `memoryview` and Casting** - **Casting in Python `memoryview`:** When people refer to "casting" with `memoryview`, they usually mean taking a slice of a memoryview or viewing the underlying buffer as a different type (sometimes using modules like `ctypes` or `numpy` to achieve type reinterpretation). However, the built-in `memoryview` object itself does not perform type conversion; it provides a view into the memory buffer of an object that supports the buffer protocol, such as `bytes`, `bytearray`, or a NumPy array[5][6][1]. - **Type Safety:** The `memoryview` object allows you to manipulate the data as if it were a sequence of bytes or another type (if the underlying buffer supports it), but it does not automatically convert the data to a different type. If you want to reinterpret the data as a different type (e.g., casting bytes to an integer array), you typically use additional libraries or manual conversion, not `memoryview` itself[5][1]. - **No Implicit Type Conversion:** The `memoryview` simply provides a window into the existing data, preserving the memory layout and avoiding data copying[6][8]. Any "casting" is more about how you interpret the bytes, not a formal declaration or transformation of types. **Elixir Changesets and Casting** - **Casting in Elixir Changesets:** In Elixir's Ecto changesets, "casting" refers to the explicit declaration of how data (often from a web form or external source) should be converted or validated into a specific type before being inserted into a database. This is a declarative process that ensures data integrity and type safety. - **Type Conversion:** Casting in Elixir changesets involves actual type conversion (e.g., from a string to an integer or date), and is a core part of the data validation and preparation process. **Comparison Table** | Context | Meaning of "Cast" | Type Conversion | Purpose | |------------------------|------------------------------------------|-----------------|--------------------------------| | Python `memoryview` | Viewing/reinterpreting memory as a type | No (manual only)| Efficient data access/manipulation | | Elixir changesets | Declaring/validating/converting types | Yes | Data validation, preparation | **Summary** In Python, "casting" with `memoryview` is about interpreting memory as a different type, not about automatic type conversion or validation as in Elixir changesets. The term is used more loosely in Python, while in Elixir, it is a formal, declarative operation for data preparation[5][6][1]. [1] https://cython.readthedocs.io/en/latest/src/userguide/memoryviews.html [2] https://stackoverflow.com/questions/71028367/how-to-make-a-custom-python-class-to-support-memoryview-conversion [3] https://stackoverflow.com/questions/48136122/how-do-i-cast-a-slice-of-memoryview-into-c-string-unsigned-char [4] https://docs.python.org/3/library/stdtypes.html [5] https://blog.finxter.com/converting-python-bytes-to-memoryview/ [6] https://realpython.com/ref/builtin-functions/memoryview/ [7] https://www.stratascratch.com/blog/understanding-data-types-in-python-with-examples/ [8] https://docs.python.org/3/c-api/memoryview.html
NumPy
python’s Global Interpreter Lock (GIL) and how releasing it unlocks better parallelisation
it’s a mutex that protects access to python objects and therefore prevents multiple native threads from executing Python bytecode simultaneously within the same process.
It was intended to be a simplification mechanism to make memory handling simpler but that also means having this mutex limits parallelism.
Typical workarounds:
multi-processing, separate processes, each with their own GIL
offload CPU-intensive work to C-extensions or libs that release the GIL
here’s a bot-written outline on it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50The **Global Interpreter Lock (GIL)** is a core mechanism in CPython, the reference implementation of Python, that ensures only one thread executes Python bytecode at a time, even on multi-core processors[2][4][5]. Here’s a detailed overview: ## **What Is the GIL?** - **Definition:** The GIL is a mutex (mutual exclusion lock) that protects access to Python objects, preventing multiple native threads from executing Python bytecode simultaneously within the same process[2][4][7]. - **Purpose:** It exists primarily to simplify CPython’s memory management, especially reference counting, which is not thread-safe by default. Without the GIL, concurrent access to Python objects could lead to race conditions and memory corruption[5][7]. ## **How Does the GIL Work?** - **Single Thread Execution:** Only one thread holds the GIL at any moment, meaning only one thread can execute Python code at a time, even if you have multiple threads running[2][4][6]. - **Thread Switching:** The interpreter periodically releases the GIL, allowing other threads to acquire it and execute Python code. This switching happens frequently, but it means that CPU-bound multithreaded Python programs do not benefit from multiple cores for parallel execution of Python code[2][4]. - **Non-Python Code:** Operations that do not require the Python interpreter (such as I/O or some C extensions like NumPy) can release the GIL, allowing other threads to run Python code or the process to use multiple cores for those operations[2][4]. ## **Why Does the GIL Exist?** - **Memory Management:** Simplifies reference counting and garbage collection by ensuring thread safety for Python objects[5][7]. - **C Extensions:** Makes it easier to write and use C extensions by providing a stable, single-threaded environment for their execution[1][3][7]. - **Implementation Simplicity:** Using a single lock is easier to implement and maintain than fine-grained locking for all Python objects[1][7]. ## **Implications of the GIL** - **Limited Parallelism:** The GIL prevents true parallel execution of Python code in multi-threaded programs, making it a bottleneck for CPU-bound tasks[2][4][5]. - **Workarounds:** For parallelism, Python developers often use multiprocessing (which uses separate processes, each with its own GIL) or offload CPU-intensive work to C extensions or libraries that release the GIL[1][4]. - **Performance Impact:** The GIL can degrade performance in multi-threaded, CPU-bound applications. However, for I/O-bound or single-threaded programs, its impact is minimal[2][4][6]. ## **Future of the GIL** - **Potential Removal:** The Python Steering Council has indicated support for PEP 703, which proposes making a version of CPython without the GIL. This could enable true multi-threaded parallelism in Python in the future[3]. - **Challenges:** Removing the GIL is complex due to backward compatibility and the reliance of many extensions on its guarantees[3][2]. ## **Summary Table** | Feature | Description | |------------------------|-----------------------------------------------------------------------------| | Purpose | Protect Python objects, simplify memory management, enable C extensions | | Execution Model | Only one thread executes Python bytecode at a time | | Impact on Parallelism | Limits CPU-bound parallelism in multi-threaded Python code | | Workarounds | Multiprocessing, C extensions, I/O-bound operations | | Future | Potential removal via PEP 703, but challenges remain | The GIL is a key part of Python’s design, balancing simplicity and safety with some limitations for parallel execution[2][4][5]. [1] https://en.wikipedia.org/wiki/Global_interpreter_lock [2] https://wiki.python.org/moin/GlobalInterpreterLock [3] https://developer.vonage.com/en/blog/removing-pythons-gil-its-happening [4] https://realpython.com/python-gil/ [5] https://dev.to/adityabhuyan/understanding-pythons-global-interpreter-lock-gil-and-its-impact-on-concurrency-2da6 [6] https://realpython.com/videos/global-interpreter-lock-overview/ [7] https://dev.to/ohdylan/understanding-pythons-global-interpreter-lock-gil-mechanism-benefits-and-limitations-4aha [8] https://www.pubnub.com/blog/understanding-pythons-global-interpreter-lock/NumPy and SciPy are formidable libraries, and are the foundation of other awesome tools such as the Pandas—which implements efficient array types that can hold non‐ numeric data and provides import/export functions for many different formats, like .csv, .xls, SQL dumps, HDF5, etc.—and scikit-learn, currently the most widely used Machine Learning toolset. Most NumPy and SciPy functions are implemented in C or C++, and can leverage all CPU cores because they release Python’s GIL (Global Interpreter Lock). The Dask project supports parallelizing NumPy, Pandas, and scikit-learn processing across clusters of machines. These packages deserve entire books about them.
Deques and Other Queues
issues with list methods
although we can use
listas a stack / queue (by using.append()or.pop()). However, inserting and removing from the head of the list (the 0-idx end) is costly because the entire list must be shifted in memory => this is why just re-purposing lists is not a good idea.
Characteristics:
- when bounded, every mutation will adhere to the deque capacity for sure.
- hidden cost is that removing items from the middle of a deque is not fast
- append and popleft are atomic, so can be used for multi-threaded applications without needing locks:w
alternative queues in stdlib
- asyncio provides async-programming focused queues
Chapter Summary
Further Reading
- “numpy is all about vectorisation” oprations on array elements without explicit loops
More on Flat vs Container Sequences
``Flat Versus Container Sequences''
Chapter 3. Dictionaries and Sets
What’s New in This Chapter
Extra: Internals of sets and dicts internalsextra
This info is found in the fluentpython website. It considers the strengths and limitations of container types (dict, set) and how it’s linked to the use of hash tables.
Running performance tests
the trial example of needle in haystack has beautiful ways of writing it
1 2 3 4found = 0 for n in needles: if n in haystack: found += 1when using sets, because it’s directly related to set theory, we can use a one-liner to count the needles that occur in the haystack by doing an intersection:
1found = len(needles & haystack)This intersection approach is the fastest from the test that the textbook runs.
the worst times are if we use the
list datastructurefor the haystackIf your program does any kind of I/O, the lookup time for keys in dicts or sets is negligible, regardless of the dict or set size (as long as it fits in RAM).
Hashes & Equality
the usual uniform random distribution assumption as the goal to reach for hashing functions, just described in a different way: to be effective as hash table indexes, hash codes should scatter around the index space as much as possible. This means that, ideally, objects that are similar but not equal should have hash codes that differ widely.
- here’s the oficial docs on the hash function
A hashcode for an object usually has less info than the object that the hashcode is for.
- 64-bit CPython hashcodes is a 64-bit number => \(2^{64}\) possible values
- consider an ascii string of 10 characters (and that there are 100 possible values in ascii) => \(100^{10}\) which is bigger than the possible values for the hashcode.
By the way it’s actually salted, there’s some nuances on how the salt is derived but it should be such that each shell has a particular salt.
The modern hash function is the siphash implementation
Hash Implementation
- each row in the table is traditionally a “bucket”. In the case of sets, it’s just a single item that the bucket will hold
- For 64-bit CPython,
- It’s a 64-bit hash code that points to a 64 bit pointer to the element value
- so the table doesn’t need to keep track of indices, offsets work fine since they are fixed-width.
- Also it keeps 1/3 extra space that gets doubled when encroached so there’s some amortisation happening there also.
Hash Table Algo for sets
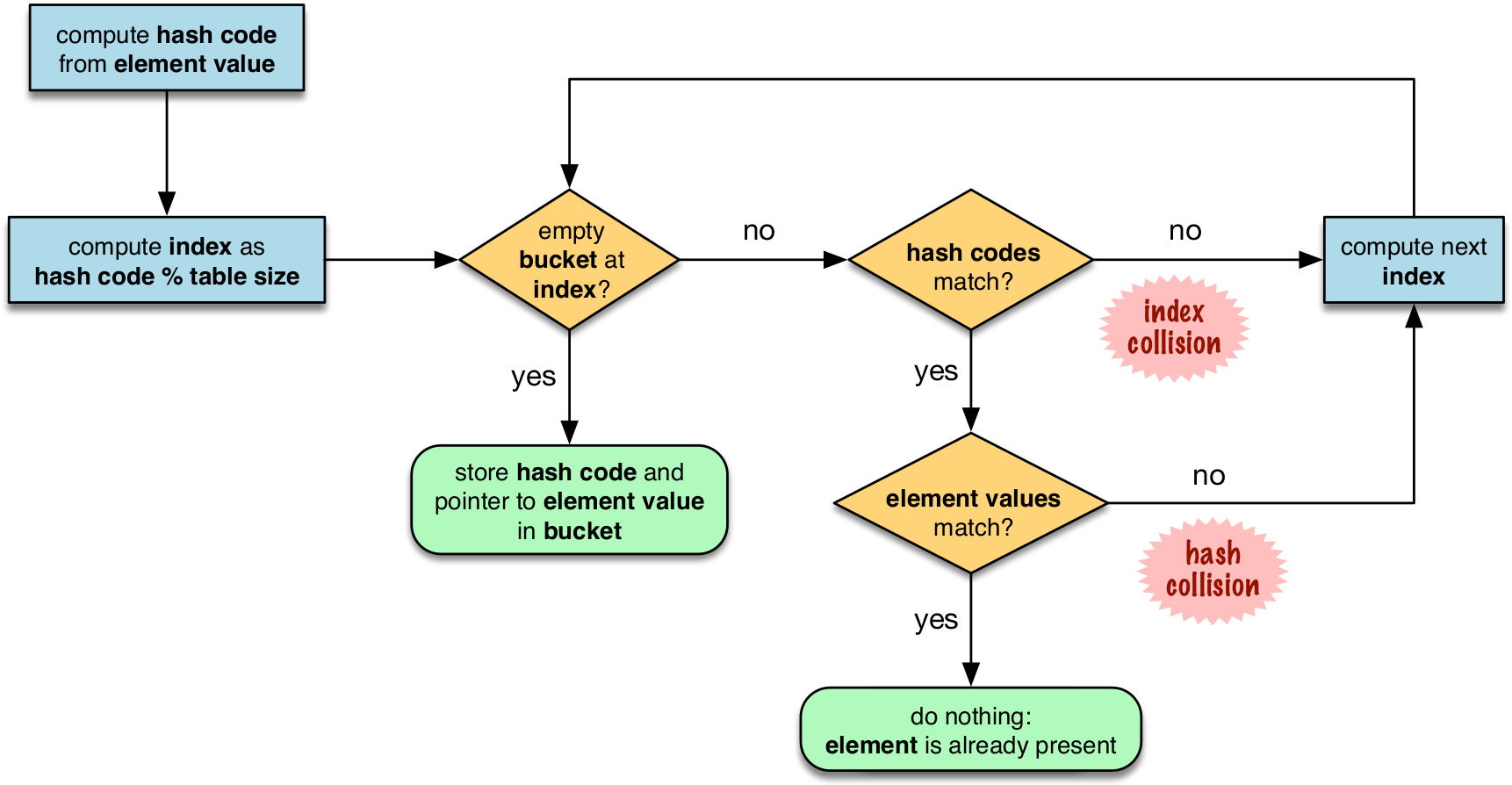
in the flowchart, notice that the first step includes the modulo operation, this is the reason why the insertion order is not preserved since the output of running the modulo on the hashvalues will not be in order, it will spread about.
on hash collisions, the probing can be done in various ways. CPython uses linear probing but also mitigates the harms of using linear probing: Incrementing the index after a collision is called linear probing. This can lead to clusters of occupied buckets, which can degrade the hash table performance, so CPython counts the number of linear probes and after a certain threshold, applies a pseudo random number generator to obtain a different index from other bits of the hash code. This optimization is particularly important in large sets.
the last step is to actually do an equality check on the value. this is why for something to be hashable, two dunder functions must be implemented:
__hash__and__eq__
Hash table usage for dicts
Dictionary implementation benefits from 2 memory optimisations. Here’s a summary of it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27Here’s a summary of the **two major memory optimizations** for modern Python dictionaries, as described in the referenced Fluent Python article: 1. **Key-Sharing Dictionaries (PEP 412)** - Introduced in Python 3.3, this optimization allows multiple dictionaries that share the same set of keys (such as instance `__dict__` for objects of the same class) to share a single "keys table." - Only the values are stored separately for each dictionary; the mapping from keys to indices is shared. - This greatly reduces memory usage for objects of the same type, especially when many objects have the same attributes[1]. 2. **Compact Dictionaries** - Modern Python dictionaries use a split-table design, separating the storage of keys and values from the hash table itself. - The hash table stores indices into a compact array of keys and values, rather than storing the full key-value pairs directly in the hash table. - This reduces memory overhead, improves cache locality, and keeps insertion order predictable and efficient[1]. **In summary:** - **Key-sharing dictionaries** save memory by sharing the key structure among similar dicts. - **Compact dicts** store keys and values in separate, dense arrays, minimizing wasted space and improving performance. [1] https://www.fluentpython.com/extra/internals-of-sets-and-dicts/ [2] https://www.geeksforgeeks.org/python/minimizing-dictionary-memory-usage-in-python/ [3] https://python.plainenglish.io/optimizing-python-dictionaries-a-comprehensive-guide-f9b04063467a [4] https://stackoverflow.com/questions/10264874/python-reducing-memory-usage-of-dictionary [5] https://labex.io/tutorials/python-how-to-understand-python-dict-memory-scaling-450842 [6] https://www.youtube.com/watch?v=aJpk5miPaA8 [7] https://www.reddit.com/r/pythontips/comments/149qlts/some_quick_and_useful_python_memory_optimization/ [8] https://www.tutorialspoint.com/How-to-optimize-Python-dictionary-access-code [9] https://labex.io/tutorials/python-how-to-understand-python-dictionary-sizing-435511 [10] https://www.joeltok.com/posts/2021-06-memory-dataframes-vs-json-like/ [11] https://www.linkedin.com/advice/0/what-strategies-can-you-use-optimize-python-dictionaries-fqcufOriginal implementation
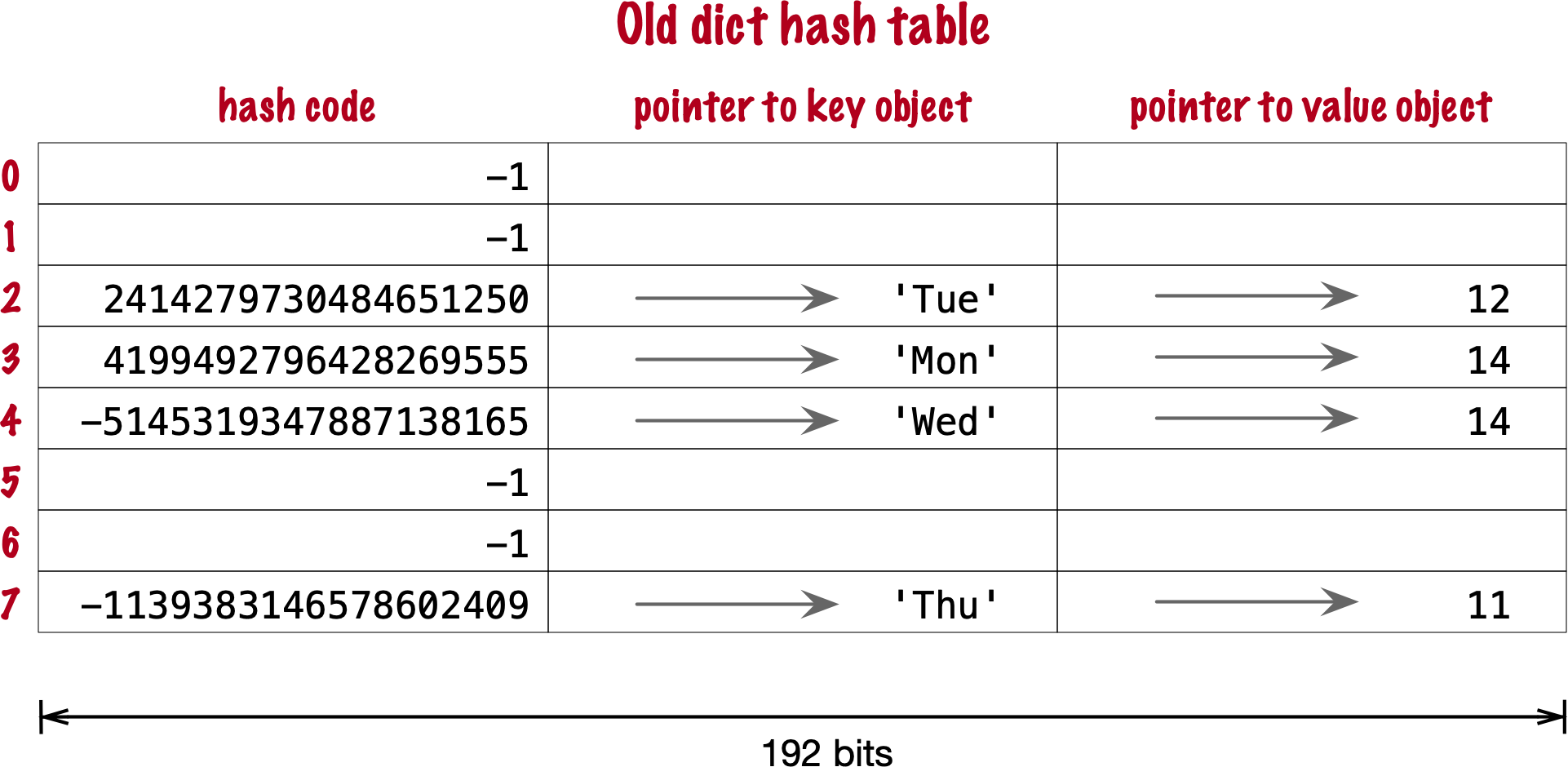
- there’s 3 fields to keep, 64 bits each
- first two fields play the same role as they do in the implementation of sets. To find a key, Python computes the hash code of the key, derives an index from the key, then probes the hash table to find a bucket with a matching hash code and a matching key object. The third field provides the main feature of a dict: mapping a key to an arbitrary value
Optimisation 1: Compact implementation

- there’s an indices table extra that has a smaller width (hence compact)
- Raymond Hettinger observed that significant savings could be made if the hash code and pointers to key and value were held in an entries array with no empty rows, and the actual hash table were a sparse array with much smaller buckets holding indexes into the entries array
Optimisation 2: Key-Sharing Dictionary ⭐️
 The combined-table layout is still the default when you create a dict using literal syntax or call
The combined-table layout is still the default when you create a dict using literal syntax or call dict(). A split-table dictionary is created to fill the__dict__special attribute of an instance, when it is the first instance of a class. The keys table is then cached in the class object. This leverages the fact that most Object Oriented Python code assigns all instance attributes in the__init__method. That first instance (and all instances after it) will hold only its own value array. If an instance gets a new attribute not found in the shared keys table, then this instance’s__dict__is converted to combined-table form. However, if this instance is the only one in its class, the__dict__is converted back to split-table, since it is assumed that further instances will have the same set of attributes and key sharing will be useful.
Practical Consequences
of how
setswork- need to implement the
__hash__and__eq__functions - efficient membership testing, the possible overheads is the small number of probing the might need to be done to find a matching element or an empty bucket
- Memory overhead:
- an array of pointers is the most compact, sets have significant memory overhead. hash table adds a hash code per entry, and at least ⅓ of empty buckets to minimize collisions
- Insertion order is somewhat preserved but it’s not reliable.
- Adding elements to a set may change the order of other elements. That’s because, as the hash table is filled, Python may need to recreate it to keep at least ⅓ of the buckets empty. When this happens, elements are reinserted and different collisions may occur.
- need to implement the
of how
dictswork- need to implement both the dunder methods
__hash__and__eq__ - key search almost as fast as element searches in sets
- Item ordering preserved in the entries table
- To save memory, avoid creating instance attributes outside of the init method. If all instance attributes are created in init, the dict of your instances will use the split-table layout, sharing the same indices and key entries array stored with the class.
- need to implement both the dunder methods
Modern dict Syntax
- dict Comprehensions
Unpacking Mappings
- we can use the unpacking operator
**when keys aer all strings - if there’s any duplicates in the keys then the later entries will overwrite the earlier ones
- we can use the unpacking operator
Merging Mappings with | (the union operator)
- there’s an inplace merge
|=and there’s a normal merge that creates a new mapping| - it’s supposed to look like the union operator and you’re doing an union on two mappings
- there’s an inplace merge
Syntax & Structure: Pattern Matching with Mappings cool
this will work with anything that is a subclass or virtual subclass of Mapping
we can use the usual tools for this:
can use partial matching
1 2 3 4 5 6 7 8 9 10 11data = {"a": 1, "b": 2, "c": 3} match data: case {"a": 1}: print("Matched 'a' only") case {"a": 1, "b": 2}: print("Matched 'a' and 'b'") case _: print("No match") # in this case, the order of the cases matter, the first match is evaluatedcan capture keys using the
**restsyntax1 2 3match data: case {"a": 1, **rest}: print(f"Matched 'a', rest: {rest}")can be arbitrarily deeply nested
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21data = { "user": { "id": 42, "profile": { "name": "Alice", "address": {"city": "Wonderland"} } } } match data: case { "user": { "profile": { "address": {"city": city_name} } } }: print(f"City is {city_name}") case _: print("No match")
Keys in the pattern must be literals (not variables), but values can be any valid pattern, including captures, literals, or even further nested patterns
Pattern matching works with any mapping type (not just dict), as long as it implements the mapping protocol
- Guards (if clauses) can be used to add extra conditions to a match.
More on virtual sub-classes (and how it’s similar to mixins)
should be used when we can’t control the class (e.g. it’s an external module) but we want to adapt it
allows the indication that a class conforms to the interface of another – to adapt to multiple interfaces
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80A **virtual subclass** in Python refers to a class that is recognized as a subclass of an abstract base class (ABC) without actually inheriting from it in the traditional sense. This mechanism is provided by the `abc` module and is achieved by *registering* a class as a virtual subclass of an ABC using the `register()` method[4][5][8]. ### Core Mental Model - **Traditional subclassing**: A class (the subclass) inherits from another (the superclass), forming a direct relationship. Methods and attributes are inherited, and `issubclass()` and `isinstance()` reflect this relationship[3]. - **Virtual subclassing**: A class is *declared* to be a subclass of an ABC at runtime, without modifying its inheritance tree or MRO (Method Resolution Order). This is done by calling `ABC.register(SomeClass)`. After registration, `issubclass(SomeClass, ABC)` and `isinstance(instance, ABC)` will return `True`, but `SomeClass` does not actually inherit from `ABC`[4][5][8]. ### Why Use Virtual Subclasses? - **Third-party integration**: If you want to treat classes from external libraries as conforming to your interface (ABC), but you cannot or do not want to modify their source code to inherit from your ABC, you can register them as virtual subclasses[1][8]. - **Interface compliance**: Virtual subclassing is a way to declare that a class “conforms to” an interface, even if it doesn’t inherit from it, as long as it implements the required methods (i.e., it follows the protocol)[2][5]. - **Decoupling**: It allows you to decouple interface definition (the ABC) from implementation, enabling more flexible and extensible designs. ### Example Suppose you have an ABC and an external class: ```python from abc import ABC class Car(ABC): def drive(self): pass class Tesla: def drive(self): print("Driving in Tesla") ``` You want to use `isinstance(obj, Car)` to check if an object can be driven, but `Tesla` does not inherit from `Car`. You can register it: ```python Car.register(Tesla) print(issubclass(Tesla, Car)) # True print(isinstance(Tesla(), Car)) # True ``` Now, `Tesla` is a *virtual subclass* of `Car`, even though it doesn't inherit from it[4][5][8]. ### Key Properties - **No inheritance**: Virtual subclasses do not inherit methods or properties from the ABC. Registration only affects `issubclass()` and `isinstance()` checks[4][8]. - **No MRO change**: The ABC does not appear in the virtual subclass’s MRO, so `super()` calls and method resolution are unaffected[4]. - **Runtime declaration**: Registration can be done at runtime, providing flexibility for dynamic systems[4][5]. ### Relationship to Other Python Typing Models | Model | Relationship Mechanism | Example Use Case | |-----------------------|-------------------------------|---------------------------------------------------| | Duck typing | Implements required interface | Any object with `drive()` method can be used | | Virtual subclass | Registered with ABC | External class made compatible with ABC interface | | Classical inheritance | Inherits from superclass | Subclass extends or customizes base functionality | Virtual subclassing sits between **duck typing** (no explicit relationship, just interface compliance) and **classical inheritance** (explicit parent-child relationship), allowing you to *declare* interface compliance without direct inheritance[1][6]. ### Reference Implementation The mechanism is built into the `abc.ABCMeta` metaclass, which provides the `register()` method for this purpose[4][5]. > "You can also register unrelated concrete classes (even built-in classes) and unrelated ABCs as 'virtual subclasses' – these and their descendants will be considered subclasses of the registering ABC by the built-in function, but the registering ABC won’t show up in their MRO nor will method implementations defined by the registering ABC be callable..."[4] ### Practical Implications - **Type checks**: Enables more expressive and flexible type checks in frameworks and libraries. - **Backward compatibility**: Allows legacy or third-party classes to be integrated into new type hierarchies without code changes. - **Protocol enforcement**: Encourages protocol-oriented design in a language that is otherwise dynamically typed. In summary, a **virtual subclass** in Python is a class that, through explicit registration, is treated as a subclass of an abstract base class for type-checking purposes, without requiring direct inheritance or MRO modification[4][5][8]. This is a powerful tool for interface-oriented design and decoupled architectures. [1] https://stackoverflow.com/questions/51666120/whats-the-usage-of-a-virtual-subclass [2] https://www.reddit.com/r/learnpython/comments/9fgdib/virtual_subclasses/ [3] https://realpython.com/ref/glossary/subclass/ [4] https://docs.python.org/3/library/abc.html [5] https://www.demo2s.com/python/python-virtual-subclasses.html [6] https://stackoverflow.com/questions/51666120/whats-the-usage-of-a-virtual-subclass/51666808 [7] https://en.wikipedia.org/wiki/Virtual_class [8] https://kavianam.ir/Virtual-Subclass-in-Python [9] https://stackoverflow.com/questions/57602862/what-is-indirect-and-virtual-subclass [10] https://hynek.me/articles/python-subclassing-redux/- a virtual subclass should be seen more like a mixin rather than multiple inheritance
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54**Virtual subclassing** in Python is *not* the canonical or idiomatic mechanism for achieving "multiple extends" (i.e., multiple inheritance) or adapting to multiple interfaces in the way you might do in statically-typed languages like Java or C#. Instead, Python supports **multiple inheritance** natively and directly through its class definition syntax, and this is the primary mechanism for a class to inherit from multiple parents and thus "implement multiple interfaces"[1][5][6]. ### Multiple Inheritance: The Pythonic Way Python allows a class to inherit from any number of parent classes simply by listing them in the class definition: ```python class MyClass(InterfaceA, InterfaceB, SomeBase): pass ``` This means `MyClass` will inherit all methods and attributes from `InterfaceA`, `InterfaceB`, and `SomeBase`, and will be considered a subclass of each for purposes of `issubclass()` and `isinstance()` checks[1][5][6]. This is the direct and idiomatic way to "extend" multiple interfaces or base classes in Python, and is how you would typically express that a class conforms to multiple protocols or contracts. ### Virtual Subclassing: Purpose and Limitations **Virtual subclassing** via `ABC.register(SomeClass)` is a mechanism for declaring that a class should be *recognized* as a subclass of an abstract base class (ABC) for the purposes of type checking, without actually inheriting from it. This is especially useful when you want to adapt a class (often from a third-party library) to an interface you control, but cannot or do not want to modify its source code[7]. - **Virtual subclassing does not provide code sharing**: The registered class does not inherit any methods or properties from the ABC; it is only recognized as a subclass for `issubclass()` and `isinstance()` checks. - **No method resolution order (MRO) change**: The ABC does not appear in the registered class's MRO, so method resolution and `super()` calls are unaffected. - **No attribute/method adaptation**: If the registered class does not implement the required methods, you get runtime errors. ### Adapting to Multiple Interfaces If you want a class to *adapt* to multiple interfaces: - **If you control the class**: Use multiple inheritance directly. This is idiomatic and gives you both interface conformance and code sharing[1][5][6]. - **If you do not control the class**: Use virtual subclassing to declare interface conformance, but be aware this is only for type checks and does not provide actual method implementations[7]. ### Mixin Pattern A related idiom is the **mixin**: a class designed to be used as a base class that provides additional methods, typically without defining its own state. Mixins are commonly used in Python to modularly add functionality via multiple inheritance, and are a way to "compose" behaviors without the pitfalls of deep inheritance hierarchies[6]. ### Summary Table | Mechanism | Code Sharing | Interface Conformance | Idiomatic Use | |---------------------|-------------|----------------------|----------------------| | Multiple Inheritance| Yes | Yes | Implementing multiple interfaces, mixins | | Virtual Subclassing | No | Yes (type checks) | Adapting foreign classes to your ABCs | **In summary:** Python's primary and idiomatic way to "extend" multiple interfaces is through direct multiple inheritance. **Virtual subclassing** is a supplementary mechanism for adapting existing classes to an interface for type checks, but it does not provide code sharing or actual interface adaptation[1][5][6][7]. [1] https://www.digitalocean.com/community/tutorials/understanding-class-inheritance-in-python-3 [2] https://stackoverflow.com/questions/66849568/issubclass-and-multiple-inheritance [3] https://stackoverflow.com/questions/27545888/is-multiple-inheritance-from-the-same-base-class-via-different-parent-classes-re [4] https://softwareengineering.stackexchange.com/questions/291061/is-there-a-better-pattern-than-multiple-inheritance-here [5] https://dataplatform.cloud.ibm.com/docs/content/wsd/nodes/scripting_guide/clementine/jython/clementine/python_inheritance.html?audience=wdp&context=dph&context=analytics&context=analytics&context=analytics&context=analytics&context=analytics&context=analytics&context=cpdaas [6] https://openstax.org/books/introduction-python-programming/pages/13-5-multiple-inheritance-and-mixin-classes [7] https://hynek.me/articles/python-subclassing-redux/ [8] https://docs.python.org/3/tutorial/classes.html [9] https://realpython.com/inheritance-composition-python/ [10] https://www.geeksforgeeks.org/python/multiple-inheritance-in-python/
Standard API of Mapping Types
The recommendation is to wrap a dict by composition instead of subclassing the Collection, Mapping, MutableMapping ABCs.
Note that because everything ultimately relies on the hastable, the keys must be hashable (doesn’t matter if the value is hashable)
What Is Hashable
- ✅ User Defined Types:
for user defined types, the hashcode is the
id()of the object and the__eq__method from theobjectparent class compares the object ids.
gotcha: there’s a salt applied to hashing
And the salt differs across python processes.
The hash code of an object may be different depending on the version of Python, the machine architecture, and because of a salt added to the hash computation for secu‐ rity reasons.3 The hash code of a correctly implemented object is guaranteed to be constant only within one Python process.
- ✅ User Defined Types:
for user defined types, the hashcode is the
Overview of Common Mapping Methods: using
dict,defaultdictandOrderedDict:NOTER_PAGE: (115 . 0.580146)
Inserting or Updating Mutable Values: when to use setdefault
Should use setdefault when you want to mutate the mapping and there’s nothing there
E.g. you wanna fill in empty default values
so instead of doing this which has 2 searches through the dict index ⛔️
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18import re import sys WORD_RE = re.compile(r'\w+') index = {} with open(sys.argv[1], encoding='utf-8') as fp: for line_no, line in enumerate(fp, 1): for match in WORD_RE.finditer(line): word = match.group() column_no = match.start() + 1 location = (line_no, column_no) # this is ugly; coded like this to make a point occurrences = index.get(word, []) occurrences.append(location) index[word] = occurrences # display in alphabetical order for word in sorted(index, key=str.upper): print(word, index[word])we could do just do a single search within the dict index and do:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15"""Build an index mapping word -> list of occurrences""" import re import sys WORD_RE = re.compile(r'\w+') index = {} with open(sys.argv[1], encoding='utf-8') as fp: for line_no, line in enumerate(fp, 1): for match in WORD_RE.finditer(line): word = match.group() column_no = match.start() + 1 location = (line_no, column_no) index.setdefault(word, []).append(location) # display in alphabetical order for word in sorted(index, key=str.upper): print(word, index[word])setdefault returns the value, so it can be updated without requiring a second search.
Automatic Handling of Missing Keys
We have 2 options here.
defaultdict: Another Take on Missing Keys
- it’s actually a callable that we are passing as an arg, so when we do things like
boolorlistwe’re actually passing in the constructor to these builtins. - callable is stored within the
default_factoryand we can replace the factory as we wish! - interesting: if we do a membership check on a key that doesn’t exist, the default factory won’t be called yet.
- it’s actually a callable that we are passing as an arg, so when we do things like
The missing Method
:PROPERTIES: :NOTER_PAGE: (121 . 0.519175)
TLDR: subclass
UserDictinstaed ofdictto avoid these issuesTake note of the nuances in the implementation that is shown because they avoid infinite recursion.
It’s important to think of how the method delegation may introduce chances of infinite recursion.
Also, same thing for what the fallback methods are for builtin methods.
note:
k in my_dictfaster thank in my_dict.keys()Also technically
k in my_dictis faster than using thek in my_dict.keys()because it avoids the attribute lookup to find the.keysmethod.
Inconsistent Usage of missing in the Standard Library
TLDR: subclass
UserDictinstaed ofdictto avoid these issues subclassing builtin types is tricky! (will come up later in the book).Basically, this dunder method is inconsistently used. Be careful if you wanna subclass this, it may result in infinite recursions.
Variations of dict
collections.OrderedDict
Mostly the modern implementation for
dictis good enough- has some minor differences from the modern implementation of
dict:- can handle frequent reordering ops better than
dict=> useful to track recent accesses like in an LRU cache.
- can handle frequent reordering ops better than
- use it for simple implementations of an LRU cache.
- has some minor differences from the modern implementation of
collections.ChainMap
- chains together multiple mappings by holding references to the mappings
- any mods happen to the first-inserted mapping
- it’s useful to search hierarchically (search from d1, then d2, then d3) and prioritises the results found in the earlier implementation.
collections.Counter
- counters are great!!!
- GOTCHA: when things are tied, only one is returned.
example if counter looks like this:
Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})then if we doct.most_common(3)then even if both b and c are tied, we only get b in the result. Here’s some more context on this:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61The behavior you’re observing with `Counter.most_common(n)`—where only one of the tied elements is included when there’s a tie at the cutoff—is by design, and it’s important to understand the underlying mechanics and implications. ### Why does this happen? - **`most_common(n)` returns exactly `n` items**: The method returns the *first* `n` elements from the sorted list of items, sorted by count (descending). If multiple elements have the same count at the cutoff position, only those that appear first (according to the internal order, which is typically insertion order for equal counts) are included[1][2][9]. - **Ties are not expanded**: If two or more elements are tied for the last spot in the top `n`, only as many as needed to reach `n` are returned. The method does not automatically include all items with the same count as the nth item[6]. #### Example: ```python from collections import Counter ct = Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1}) print(ct.most_common(3)) # Output might be: [('a', 10), ('z', 3), ('b', 2)] ``` Even though both `'b'` and `'r'` have a count of `2`, only `'b'` is included because you asked for the top 3, and `'b'` appears before `'r'` in the internal ordering[2][6]. ### How is the order determined for ties? - **Insertion order**: For elements with equal counts, their order in the result is based on the order they were first encountered in the input (Python 3.7+ dictionaries preserve insertion order)[2][9]. - **No guarantee for all ties**: There is no built-in mechanism to include all elements with the same count as the nth element unless you implement it yourself[6]. ### What if you want all tied elements included? You need to post-process the result. For example, you can: 1. Get the count of the nth item. 2. Iterate through all items and include those with counts >= nth count. ```python from collections import Counter ct = Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1}) n = 3 top_n = ct.most_common(n) cutoff = top_n[-1][1] all_tied = [(k, v) for k, v in ct.items() if v >= cutoff] print(all_tied) ``` This will include all items with counts equal to or greater than the nth most common, including ties[6]. ### Summary - `most_common(n)` returns exactly `n` elements, even if there are ties at the last position. - For ties, only the first encountered elements (in insertion order) are included. - To include all tied elements, you must filter manually after getting the cutoff value[2][6][9]. This behavior is documented and is a common source of confusion—your observation is correct and is a subtle but important aspect of using `Counter.most_common()` in Python. [1] https://www.geeksforgeeks.org/python/python-most_common-function/ [2] https://docs.python.org/3/library/collections.html [3] https://www.digitalocean.com/community/tutorials/python-counter-python-collections-counter [4] https://stackoverflow.com/questions/29240807/python-collections-counter-most-common-complexity [5] https://blog.csdn.net/weixin_43056275/article/details/124384145 [6] https://stackoverflow.com/questions/33791057/counter-most-common-is-a-little-misleading/33791292 [7] https://www.youtube.com/watch?v=fqACZvcsNug [8] https://dev.to/atqed/you-can-be-happy-to-know-python-counter-how-to-get-the-most-common-elements-in-a-list-o1m [9] https://ioflood.com/blog/python-counter-quick-reference-guide/ [10] https://dev.to/kathanvakharia/python-collections-module-counter-2gn
shelve.Shelf
- shelves are for storing pickle jars
- shelves are persistent storage for a mapping of strings to pickle objects
- A Shelf instance is a context manager, so you can use a with block to make sure it is closed after use.
Ref “Pickle’s nine flaws”
And here’s a bot summary of it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43Here is a summary of the nine flaws of Python's `pickle` module as detailed by Ned Batchelder[1][2]: 1. **Insecure** Pickle is fundamentally unsafe for untrusted data. Maliciously crafted pickles can execute arbitrary code during unpickling, as the process can invoke any callable in the Python environment—not just constructors for your objects. 2. **Old pickles look like old code** Pickle stores the exact structure of objects as they existed when pickled. If your code changes (e.g., you add or remove attributes), unpickling old data can result in objects that don't match your current codebase, leading to bugs and inconsistencies. 3. **Implicit** The serialization process is implicit and automatic: you cannot explicitly control how objects are serialized. For example, you cannot choose to serialize a datetime as an ISO8601 string instead of a datetime object. 4. **Over-serializes** Pickle serializes everything in your objects, including data you may not want to persist (like caches or open file handles). There is no straightforward way to exclude unwanted attributes, and if an attribute is not pickle-able, you'll get an exception[2]. 5. **`__init__` isn’t called** When unpickling, the `__init__` method of your class is not invoked. This can leave objects in an inconsistent state, especially if `__init__` does essential setup or side effects. 6. **Python only** Pickle is Python-specific. While there are rare cross-language implementations, they're limited and not practical for general use. This makes pickled data hard to share with non-Python systems. 7. **Unreadable** Pickles are binary blobs, not human-readable. You can't inspect or search them with standard tools, making debugging and data recovery more difficult. 8. **Appears to pickle code** Pickle will serialize references to functions and classes, but not their code—only their names. This can give the false impression that code is being serialized, but on unpickling, the code must already exist in the environment. 9. **Slow** Pickle is slower than many alternative serialization formats, both in terms of speed and efficiency. > Some of these issues can be mitigated with custom methods like `__getstate__` or `__reduce__`, but at that point, alternative serialization formats (e.g., JSON, protocol buffers) may be more robust and maintainable[1]. These flaws highlight why `pickle` is best reserved for trusted, Python-only, and short-lived data interchange scenarios—not for general-purpose or cross-system serialization. [1] https://nedbatchelder.com/blog/202006/pickles_nine_flaws.html [2] https://nedbatchelder.com/blog/tag/python.html [3] https://www.python4data.science/en/latest/data-processing/serialisation-formats/pickle/index.html [4] https://pycoders.com/issues/426 [5] https://stanforddaily.com/2019/10/11/face-it-pickles-are-bad-an-irrefutable-proof/ [6] https://content.ces.ncsu.edu/pickle-and-pickle-product-problems [7] https://diff.blog/post/pickles-nine-flaws-49891/ [8] https://pythonbytes.fm/episodes/show/193/break-out-the-django-testing-toolbox [9] https://www.reddit.com/r/Python/comments/1c5l9px/big_o_cheat_sheet_the_time_complexities_of/ [10] https://podscripts.co/podcasts/python-bytes/189-what-does-strstrip-do-are-you-sure
Subclassing UserDict Instead of dict
- key idea here is that it uses composition and keeps an internal dict within the
dataattribute - implementing other functions as we extend it will require us to use the
self.dataattribute.
- key idea here is that it uses composition and keeps an internal dict within the
Immutable Mappings
we can use a read-only
MappingProxyTypefrom thetypesmodule to expose a readonly proxythe constructor in a concrete Board subclass would fill a private mapping with the pin objects, and expose it to clients of the API via a public .pins attribute implemented as a mappingproxy. That way the clients would not be able to add, remove, or change pins by accident.
Dictionary Views
- the views are supposed to be proxies as well so they are updated. Any changes to the original mapping will be viewable as well
- because they are not sequences (they are view objects) they are not subscript-able. so doing something like
myvals[0]won’t work. If we wish, we could convert it to a list, but then it’s a copy, it’s no longer a live dynamic read-only proxy.
Practical Consequences of How dict Works
why we should NOT add instance attrs outside of
__init__functionsThat last tip about instance attributes comes from the fact that Python’s default behavior is to store instance attributes in a special dict attribute, which is a dict attached to each instance.9 Since PEP 412—Key-Sharing Dictionary was implemented in Python 3.3, instances of a class can share a common hash table, stored with the class. That common hash table is shared by the dict of each new instance that has the same attributes names as the first instance of that class when init returns. Each instance dict can then hold only its own attribute values as a simple array of pointers. Adding an instance attribute after init forces Python to create a new hash table just for the dict of that one instance
also KIV the implementation of
__slots__and how that is even better of an optimisation.
Set Theory
As we had found out from the extension writeup, the intersection operator is a great oneliner found = len(needles & haystack) or found = len(set(needles) & set(haystack)) to be more generalisable (though there’s the overhead from building the set)
Set Literals
- using the set literal (
{1,2,3}) for construction is faster than using the constructor (set([ 1,2,3 ])) because the constructor will have to do a key lookup to fetch the function - the literal directly uses a
BUILDSETbytecode
- using the set literal (
Set Comprehensions
- looks almost the same as dictcomps
Practical Consequences of How Sets Work
- Set Operations
Set Operations on dict Views
.keys()and.items()are similar to frozenset.values()may work like this too but only if all the values in the dict are hashable
Even better: the set operators in dictionary views are compatible with set instances.
Chapter Summary
Further Reading
Chapter 4. Unicode Text Versus Bytes
What’s New in This Chapter
Character Issues
- “string as a sequence of characters” needs the term “character” to be defined well
- in python 3, it’s “unicode
- Unicode char separates:
- identity of the char => refers to its code point
- the byte representation for the char => dependent on the encoding used (codec between code points and byte sequences)
Byte Essentials
- binary sequences, there are 2 builtin types:
- mutable:
bytearray - immutable:
byte
- mutable:
- Each item in bytes or bytearray is an integer from 0 to 255
- literal notation depends (just a visual representation thing):
- if in ascii range, display in ascii
- if it’s a special char like tab and such, then escape it
- if amidst apostrophes, then use escape chars
- else just use the hex notation for it e.g.
\x100
- most functions work the same, except those that do formatting and those that depend on unicode data so won’t work:
- case, fold
- regexes work the same only if regex is compiled from a binary sequence instead of a
str - how to build
bytesorbytearray:- use
bytes.fromhex() - use bytes.encode(“mystr”, encoding=“utf-8”)
- use soemthing that implements buffer protocol to create from source object to new binary sequence (e.g.
memoryview).- This needs us to explicitly typecast
- generally, this will also always copy the bytes from the source – except for
memoryviewwhich is a direct proxy to the memory
- use
Indexing vs slicing & why
stris specialStrings are really the special kind here.
For bytes, bytearray, list, etc., seq returns a single element (e.g., an int), while seq[:1] returns a new sequence of the same type containing just that element. This is different from str, where both return a string. This distinction is important when working with binary data or non-string sequences in Python.
More descriptive:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79Let's break down the meaning of this passage from "Fluent Python" and the behavior it describes. ## The Key Point > For all other sequence types in Python, 1 item is not the same as a slice of length 1. This means: - **Accessing a single element** (e.g., `seq`) returns a single item (e.g., an int, a character, etc.). - **Taking a slice of length 1** (e.g., `seq[:1]` or `seq[0:1]`) returns a new sequence of the same type, containing just that one item. For most sequences in Python, **these two operations do not return the same type or value**. ### The Exception: `str` For strings, `s` and `s[:1]` both return a string (the first character), so they look the same: ```python s = "hello" print(s[0]) # 'h' print(s[:1]) # 'h' print(type(s[0]), type(s[:1])) # ``` ### The Rule: Other Sequences For other sequence types (e.g., `bytes`, `bytearray`, `list`, `tuple`): - **Indexing** returns a single element (not a sequence). - **Slicing** returns a sequence of the same type. #### Example: `bytes` ```python cafe = bytes('café', encoding='utf_8') print(cafe) # b'caf\xc3\xa9' print(cafe[0]) # 99 (int: ASCII code for 'c') print(cafe[:1]) # b'c' (bytes of length 1) print(type(cafe[0]), type(cafe[:1])) # ``` - `cafe` gives you the integer value of the first byte (`99`). - `cafe[:1]` gives you a `bytes` object of length 1: `b'c'`. #### Example: `bytearray` ```python cafe_arr = bytearray(cafe) print(cafe_arr[-1]) # 169 (int: last byte) print(cafe_arr[-1:]) # bytearray(b'\xa9') (bytearray of length 1) ``` - `cafe_arr[-1]` is an integer (the last byte). - `cafe_arr[-1:]` is a `bytearray` object of length 1. #### Example: `list` ```python lst = [10, 20, 30] print(lst[0]) # 10 print(lst[:1]) # [10] ``` - `lst` is an int. - `lst[:1]` is a list of length 1. ## Why Is This Surprising? - In Python's `str` type, `s` and `s[:1]` both return a string (the first character), which is a bit special. - For all other sequences, **indexing returns a single element (not a sequence), slicing returns a sequence**. ## Mental Model - **Indexing** (`seq[i]`): Returns the element at position `i` (type depends on the sequence). - **Slicing** (`seq[i:j]`): Returns a new sequence of the same type, containing elements from `i` to `j-1`. ## References - [Fluent Python, 2nd Edition, Chapter 4: Text versus Bytes](https://www.oreilly.com/library/view/fluent-python-2nd/9781492056348/) - [Python Data Model: Sequence Types](https://docs.python.org/3/library/stdtypes.html#sequence-types-list-tuple-range) **In summary:** For `bytes`, `bytearray`, `list`, etc., `seq` returns a single element (e.g., an int), while `seq[:1]` returns a new sequence of the same type containing just that element. This is different from `str`, where both return a string. This distinction is important when working with binary data or non-string sequences in Python.
Basic Encoders/Decoders
Highlight on page 153
Contents
Each codec has a name, like ‘utf_8’
Comment
so utf-8 is a codec here
Highlight on page 154
Contents
like ASCII and even the multibyte GB2312, cannot represent every Unicode character. The UTF encod‐ ings, however, are designed to handle every Unicode code point.
Understanding Encode/Decode Problems
Errors that we can expect:
- (generic)
UnicodeErrorUnicodeDecodeErrorUnicodeEncodeError
- When loading libraries, might end-up facing
SyntaxErroralso because of encoding issues
Coping with UnicodeEncodeError
- the error handlers for encoding error can include
'xmlcharrefreplace'. What this does is XML character reference:&#<unicode code point>and in so doing, there’s no loss of that information Here’s more context on it:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51The statement from "Fluent Python"— > 'xmlcharrefreplace' replaces unencodable characters with an XML entity. If you can’t use UTF, and you can’t afford to lose data, this is the only option. —means that when you encode a string using a limited encoding (like ASCII) and specify `errors='xmlcharrefreplace'`, **any character that cannot be represented in the target encoding is replaced with an XML numeric character reference** (e.g., `é` for "é"). This ensures that **no information is lost**: all original characters are either encoded directly (if possible) or represented as XML entities, which are reversible. ### How does it work? - When encoding, Python checks each character: - If the character can be encoded in the target encoding (e.g., ASCII), it is kept as-is. - If it cannot, it is replaced with its XML character reference: `&#;` - When decoding, you can later convert these references back to the original characters, so the process is *lossless* in terms of information content. #### Example ```python txt = "Café" encoded = txt.encode("ascii", errors="xmlcharrefreplace") print(encoded) # b'Café' ``` Here, "é" (which is not in ASCII) is replaced with `é`, preserving the character information[2][7]. ### Why is there no data loss? - **All original characters are represented:** Characters that can't be encoded are replaced with their numeric reference, which uniquely identifies the character. - **Reversible:** You can later parse the XML entities back into the original Unicode characters, restoring the original string[1][6]. ### Contrast with other error handlers - `'replace'` swaps unencodable characters for `?` (data loss). - `'ignore'` simply omits them (data loss). - `'backslashreplace'` uses Python escape sequences (reversible, but not standard in XML/HTML). - `'xmlcharrefreplace'` uses XML/HTML-compatible numeric references (reversible, and standard for text interchange). ### Practical implication If you must encode text in a limited character set (like ASCII or Latin-1) but need to ensure that all characters are preserved in some form (for later recovery or interoperability), `'xmlcharrefreplace'` is the safest choice[4][6][7]. **In summary:** Using `'xmlcharrefreplace'` means that **no original character data is lost**—all characters are either encoded directly or replaced with a reversible XML entity. This is why the book says it is the only option if you can't use UTF and can't afford to lose data. [1] https://stackoverflow.com/questions/44293891/python-string-encoding-xmlcharrefreplace-decode [2] https://www.w3schools.com/python/ref_string_encode.asp [3] https://docs.python.org/3/howto/unicode.html [4] https://docs.python.org/3/library/codecs.html [5] https://www.codecademy.com/resources/docs/python/strings/encode [6] https://code.activestate.com/recipes/303668-encoding-unicode-data-for-xml-and-html/ [7] https://www.geeksforgeeks.org/python/python-strings-encode-method/ [8] https://www.digitalocean.com/community/tutorials/python-string-encode-decode [9] https://labex.io/tutorials/python-what-is-the-role-of-the-encoding-and-errors-parameters-in-the-str-function-in-python-395133 [10] https://docs.vultr.com/python/standard-library/str/encode
- the error handlers for encoding error can include
Coping with UnicodeDecodeError
Highlight on page 156
Contents
On the other hand, many legacy 8-bit encodings like ‘cp1252’, ‘iso8859_1’, and ‘koi8_r’ are able to decode any stream of bytes, including random noise, without reporting errors. Therefore, if your program assumes the wrong 8-bit encoding, it will silently decode garbage.
Comment
utf8/16 will sound off because it’s a strict error check
the older 8bit codecs will do it silently
Highlight on page 157
Contents
“�” (code point U+FFFD), the official Unicode REPLACEMENT CHARACTER intended to represent unknown characters.
Comment
there’s an official REPLACEMENT CHARACTER
SyntaxError When Loading Modules with Unexpected Encoding
- utf8 default for python source code
- fix this by defining explicitly what encoding type to use at the top of the file when writing that file out.OR just fix it by converting to UTF-8
1# coding: cp1252
How to Discover the Encoding of a Byte Sequence
- you can’t but you can make a good guess
chardetexists for this reason, it’s an estimated detection of the encoding type.
Highlight on page 159
Contents
human languages also have their rules and restrictions, once you assume that a stream of bytes is human plain text, it may be possible to sniff out its encoding using heuristics and statistics. For example, if b’\x00’ bytes are common, it is probably a 16- or 32-bit encoding, and not an 8-bit scheme, because null characters in plain text are bugs. When the byte sequence b’\x20\x00’ appears often, it is more likely to be the space character (U+0020) in a UTF-16LE encoding, rather than the obscure U+2000 EN QUAD character—whatever that is. That is how the package “Chardet—The Universal Character Encoding Detector” works to guess one of more than 30 supported encodings. Chardet is a Python library that you can use in your programs, but also includes a command-line utility, charde tect.
Comment
typically an encoding is declared – so you have to be told what encoding it is
however, it’s possible to guess probabilistically what the encoding could be.
there are packages for that (Chardet)
BOM: A Useful Gremlin
- Byte-Order Mark: helps us know if the machine that the encoding was performed on is little or big endian.
- endianness becomes a problem only for any encoding format that takes more than a byte (so for UTF-16 and UTF-32) ==> so BOM only matters for them
- so BOM not needed for UTF-8
- but it can still be added in (discouraged though)
Highlight on page 160
Contents
UTF-16 encoding prepends the text to be encoded with the special invisible character ZERO WIDTH NO-BREAK SPACE (U+FEFF).
Highlight on page 160
Contents
This whole issue of endianness only affects encodings that use words of more than one byte, like UTF-16 and UTF-32
Highlight on page 161
Contents
using UTF-8 for general interoperability. For example, Python scripts can be made executable in Unix systems if they start with the comment: #!/usr/bin/env python3. The first two bytes of the file must be b’#!’ for that to work, but the BOM breaks that con‐ vention. If you have a specific requirement to export data to apps that need the BOM, use UTF-8-SIG but be aware that Python’s codecs documentation says: “In UTF-8, the use of the BOM is dis‐ couraged and should generally be avoided.”
Comment
use UTF-8-SIG because will be harmless
also note that the python codecs documentation says that in utf8, using a BOM (byte order mark) is discouraged.
Handling Text Files & the “Unicode Sandwich”
Here’s the gist of why it’s “unicode sandwich”
- decode bytes on input
- process text only (the meat of the sandwich is the business logic that should use strings)
- encode text on output
The best practice for handling text I/O is the “Unicode sandwich” (Figure 4-2).5 This means that bytes should be decoded to str as early as possible on input (e.g., when opening a file for reading). The “filling” of the sandwich is the business logic of your program, where text handling is done exclusively on str objects. You should never be encoding or decoding in the middle of other processing. On output, the str are encoded to bytes as late as possible.
Highlight on page 161
Contents
e best practice for handling text I/O is the “Unicode sandwich” (Figure 4-2).5 This means that bytes should be decoded to str as early as possible on input (e.g., when opening a file for reading). The “filling” of the sandwich is the business logic of your program, where text handling is done exclusively on str objects. You should never be encoding or decoding in the middle of other processing. On output, the str are enco‐ ded to bytes as late as possible.
Comment
Unicode sandwhich is the best practices for handling text files and their encoding:
bytes -> str (decode bytes as early as possbile, i.e. on input)
process text only in the business logic
encode text on output only
Highlight on page 162
Contents
Code that has to run on multiple machines or on multiple occasions should never depend on encoding defaults. Always pass an explicit encoding= argument
Comment
cross-platform code should always explicitly define the encoding value!
so unix machines will use utf-8 but then when using, say, a windows machine there might be an encoding issue becaue
Highlight on page 163
Contents
TextIOWrapper with the encoding set to a default from the local
Beware of Encoding Defaults
even within say windows itself, not every application would have the same encoding.
for unix it’s more standardised, so it’s most likely expected to be utf-8
Defaults
Main thing to remember is that the most important encoding setting is the one that is retired by
locale.getpreferredencoding()The changes can be effected by changing the environment variables.
Normalizing Unicode for Reliable Comparisons
- canonical equivalents exist, but they have different code points under the hood.
- there’s a bunch of different normalisation forms, for extra safety, when saving strings, should normalise that string (using NFC normalistaion for example)
- gotcha: some single characters can be normalised to result in visually similar but they compare different
- string normalisation can be lossy, so there can be actual dataloss from multiple sandwhich creation, destruction, creation
- NFKC and NFKD are examples of such normalisation forms - these forms should only be used for intermediate representations for search & index
- NFC is not sufficient for search and indexing because it preserves compatibility distinctions that are irrelevant (and even counterproductive) for matching.
NFKC/NFKD are used as intermediate representations for search and indexing because they erase these distinctions, enabling robust, user-friendly search behavior—at the cost of losing some original form information, which is why they are not used for storage or display.
See more info here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65To understand why **NFC normalization is not always suitable for search and indexing**, and why compatibility forms like **NFKC/NFKD** are often used as intermediate representations for these purposes, let's clarify the properties and goals of each normalization form and their implications for search/index use cases. ### **NFC vs. NFKC: What’s the Difference?** - **NFC (Normalization Form C, Canonical Composition):** - Collapses canonically equivalent sequences into a single, composed form. - Preserves distinctions between characters that are *compatible* but not *canonically equivalent* (e.g., ligatures, superscripts, full-width vs. half-width characters). - Designed to be *lossless* for textual content, so that round-tripping (normalize, then denormalize) does not lose data[4][7]. - **NFKC (Normalization Form KC, Compatibility Composition):** - Collapses both canonically equivalent and *compatibility equivalent* sequences. - This means it will, for example, convert ligatures like 'fi' (U+FB01) to 'fi', or full-width Latin letters to their standard forms. - This process is **lossy**: information about the original form (e.g., that a ligature or superscript was used) is lost[4][7]. ### **Why Not Use NFC for Search and Indexing?** **NFC is designed to preserve distinctions that are meaningful in text rendering or data storage, but are often *not* meaningful for search and indexing.** For example: - The string "field" could be encoded as: - `U+0066 U+0069 U+0065 U+006C U+0064` ("field") - `U+FB01 U+0065 U+006C U+0064` ("field" with the ligature 'fi') - **NFC will *not* turn the ligature into "fi"; it will keep the distinction.** This means a search for "field" will not match a document containing "field" (with the ligature) if both are normalized to NFC[4][7]. **For search and indexing, you often want:** - "field" and "field" to be treated as equivalent. - Full-width and half-width forms, superscripts, circled numbers, etc., to be treated as their base forms for matching. **NFKC/NFKD normalization does this:** - It "folds" away these compatibility distinctions, making visually or semantically similar forms compare equal[1][4][7]. ### **Special Role of Compatibility Normalization for Search/Index** - **Intermediate representation**: You normalize both the indexed data and the search queries to NFKC/NFKD, so that *compatibility* distinctions are erased and matches are more robust. - **Not for storage or display**: Because NFKC/NFKD is lossy, you shouldn't use it for storing or displaying user data—only for the internal process of searching and indexing[1][4]. ### **Summary Table** | Use Case | Recommended Normalization | Rationale | |-----------------|--------------------------|--------------------------------------------------------------| | Storage/Display | NFC | Preserves all distinctions, lossless for most text | | Search/Index | NFKC/NFKD | Folds away compatibility differences for robust matching | ### **References from Results** - "NFC removes the distinction between equivalent characters, while preserving the distinction between compatible characters or sequences; NFKC removes the distinction between both equivalent and compatible sequences. NFC conversion is not considered lossy, but NFKC conversion is." [4] - "It's more explicitly lossy; the compatibility forms are recommended for performing searches since they fold additional characters such as plain latin and 'full-width' latin letters." [1] - "The compatibility normalizations are super useful, because ... you often want a search query for `ffi` to match on `ffi` (and vice versa). But they are intended to lose symbolic representation (ffi and ffi are now the same thing with no way to distinguish), where the canonical normalizations are not." [7] ### **In summary** **NFC** is not sufficient for search and indexing because it preserves compatibility distinctions that are irrelevant (and even counterproductive) for matching. **NFKC/NFKD** are used as intermediate representations for search and indexing because they erase these distinctions, enabling robust, user-friendly search behavior—at the cost of losing some original form information, which is why they are not used for storage or display. [1] https://www.mediawiki.org/wiki/Unicode_normalization_considerations [2] https://stackoverflow.com/questions/15985888/when-to-use-unicode-normalization-forms-nfc-and-nfd [3] https://unicode.org/reports/tr15/ [4] https://jazz.net/wiki/bin/view/LinkedData/UseOfUnicodeNormalForms [5] https://www.w3.org/wiki/I18N/CanonicalNormalizationIssues [6] https://blog.reeset.net/archives/2532 [7] https://news.ycombinator.com/item?id=19379965 [8] https://go.dev/blog/normalization [9] https://www.reddit.com/r/programming/comments/b09c0j/when_zo%C3%AB_zo%C3%AB_or_why_you_need_to_normalize_unicode/ [10] https://unicode-org.github.io/icu/design/normalization/custom.html
Notes for page 140 V: 39% H: 25%
sequences like ‘é’ and ’e\u0301’ are called “canonical equivalents,” and applications are supposed to treat them as the same. But Python sees two different sequences of code points, and considers them not equal.
Notes for page 140 V: 82% H: 50%
it may be good to normalize strings with normalize(‘NFC’, user_text) before saving.
Case Folding (normalisation tranformation)
- folding everything into lowercase
- NOTE: casefold() and str.lower() have ~ 300 code points that return different results
Utility Functions for Normalized Text Matching
util functions that might help:
nfc_equalfold_equal
Extreme “Normalization”: Taking Out Diacritics
- google search uses this aggressive normalisation based on real world attention that people give to diacritics
- also helps for readable URLs (e.g for latin-based languages)
- one way to call this transformation is “shaving”. We “shave” the diacritics
Sorting Unicode Text
- python sorts by comparing sequences one by one
- for strings, it compares code points
- so to sort non-ascii text in python, have to use
local.strxfromto have locale-aware comparisons
Sorting with the Unicode Collation Algorithm
stdlib solution: there’s a
locale.strxfrmto do locale-specific comparisonsPython is to use the locale.strxfrm function which, according to the locale module docs, “transforms a string to one that can be used in locale-aware comparisons.”
1 2 3 4 5 6import locale my_locale = locale.setlocale(locale.LC_COLLATE, 'pt_BR.UTF-8') print(my_locale) fruits = ['caju', 'atemoia', 'cajá', 'açaí', 'acerola'] sorted_fruits = sorted(fruits, key=locale.strxfrm) print(sorted_fruits)
- use the Unicode Collation Algorithm via
pyucalib
The Unicode Database
Db is in the form of multiple text files.
Contains:
- code point to char name mappings
- metadata about the individual characters and how they are related.
That’s how the str methods isalpha, isprintable, isdecimal, and isnumeric work.
Finding Characters by Name
use
name()function from theunicodedatalibrary
Numeric Meaning of Characters
Some useful string functions here:
.isnumeric().isdecimal()
comparisons with the human meaning of these rather than the code point.
common string functions may lookup this unicode database
This is responsible for the string functions like
isdecimalisnumeric…the Unicode database records whether a character is printable, is a letter, is a decimal digit, or is some other numeric symbol. That’s how the str methods isal pha, isprintable, isdecimal, and isnumeric work. str.casefold also uses infor‐ mation from a Unicode table.
Dual-Mode str and bytes APIs
str Versus bytes in Regular Expressions
- if given bytes patterns like
\dand\wwill only match ASCII characters - if given str patterns like
\dand\wwill only match beyond just ASCII characters.
to make one point: you can use regular expressions on str and bytes, but in the second case, bytes outside the ASCII range are treated as nondigits and nonword characters.
- if given bytes patterns like
regex patterns using bytes will treat outside-ASCII range chars as nondigits and nonword chars
trivial example to make one point: you can use regular expressions on str and bytes, but in the second case, bytes outside the ASCII range are treated as nondigits and nonword characters.
str Versus bytes in os Functions
- os functions actually abide by the Unicode Sandwich: they actually call
sys.getfilesystemencoding()as soon as they can
- os functions actually abide by the Unicode Sandwich: they actually call
Chapter Summary
- remember that 1 char == 1 byte is only true if it’s utf-8, there’s more than just that.
- just always be explicit about encodings when reading them Follow the unicode sandwich and ensure the encoding is explicit always.
- Unicode provides multiple ways of representing some characters, so normalizing is a prerequisite for text matching.
Further Reading
Chapter 5. Data Class Builders
:NOTER_PAGE: (193 . 0.108844)
I think my stance on using data classes is that it should help mock things easily to come up with scaffolds which are easy to replace.
It’s interesting that the type hinting for class vs instance attributes ended up needing to use pseudoclasses specific for this purpose (ClassVar, InitVar)
Link on page 194: typing module documentation
What’s New in This Chapter
Overview of Data Class Builders
- Problem posed:
__init__constructor can become too complex if we’re just going to assign attributes from constructor parameters
- 3 options:
collections.namedtupletyping.NamedTuple- newer than
namedtuple
- newer than
@dataclassdecorator fromdataclassesmodule
- How they work:
- they don’t rely on inheritence
- typing hints are there if we use
NamedTupleordataclass - some of them are subclasses of
tuple - All of them use metaprogramming techniques to inject methods and data attributes into the class under construction.
- Some of them are more updated ways of doing things:
typed.NamedTupleis newer thannamedtuple
- Examples:
Named tuple:
define inline
Coordinate = typing.NamedTuple('Coordinate', lat=float, lon=float)defined with a
classstatement Although here, NamedTuple is not a superclass, it’s actually a metaclass1 2 3 4 5 6 7 8 9 10from typing import NamedTuple class Coordinate(NamedTuple): lat: float lon: float def __str__(self): ns = 'N' if self.lat >= 0 else 'S' we = 'E' if self.lon >= 0 else 'W' return f'{abs(self.lat):.1f}°{ns}, {abs(self.lon):.1f}°{we}'
Using dataclass
1 2 3 4 5 6 7 8 9 10 11from dataclasses import dataclass @dataclass(frozen=True) class Coordinate: lat: float lon: float def __str__(self): ns = 'N' if self.lat >= 0 else 'S' we = 'E' if self.lon >= 0 else 'W' return f'{abs(self.lat):.1f}°{ns}, {abs(self.lon):.1f}°{we}'
Main Features
- Link on page 198: inspect.get_annotations(MyClass)
- Link on page 198: typing.get_type_hints(MyClass)
Mutability
Out of the 3, only
@dataclassallows us to keep the class mutable (if we need we an mark it as frozen btw).The rest, since they are subclasses of
tupleare immutable.For the immutable ones, we can replace the object using replace functions.
NamedTuple as a metaclass customization of a class def
Although NamedTuple appears in the class statement as a super‐ class, it’s actually not. typing.NamedTuple uses the advanced func‐ tionality of a metaclass2 to customize the creation of the user’s class.
Correctly reading type hints @ runtime
It will be discussed in more detail later in the book
reading from annotations directly is not recom‐ mended. Instead, the recommended best practice to get that information is to call inspect.get_annotations(MyClass) (added in Python 3.10) or typing.get_type_hints(MyClass) (Python 3.5 to 3.9). That’s because those functions provide extra services, like resolving forward references in type hints.
Classic Named Tuples
collections.namedtuple is a factory function
So it’s possible to hack things by adding functions to this subclass.
collections.namedtuple function is a factory that builds subclasses of tuple enhanced with field names, a class name, and an informative repr.
Memory Use by collections.namedtuple
There’s no excess mem usage because it’s the class that will store the attribute names
So it’s same space usage as a tuple.
Each instance of a class built by namedtuple takes exactly the same amount of memory as a tuple because the field names are stored in the class.
Injecting methods into the subclass
this is a hack, shouldn’t be relied upon.
NOTE: No need to name the first arg as self if you’re hacking things by injecting methods
the first argument doesn’t need to be named self. Anyway, it will get the receiver when called as a method.
normal classes method definition,
selfattribute is the receiverjust some extra information about what the receiver is in the context of defining class methods in python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60In Python, the **self** parameter in class methods is the conventional name for the **receiver**—the object instance that the method is being called on. While Python documentation and community almost always use the term "self," in some other object-oriented languages (like Ruby or in theoretical OOP discussions), "receiver" is the standard term for the object that receives the method call. ### What is the "receiver"? - The **receiver** is the specific instance of the class on which the method is invoked. - In Python, when you define a method like `def foo(self, ...)`, the `self` parameter is automatically bound to the instance when you call `instance.foo(...)`[6][1][7]. - This allows each method to access and modify the attributes and other methods of the particular object instance, not just the class as a whole[6][1]. ### How does it work? - When you call `obj.method(args)`, Python translates this to `Class.method(obj, args)`. The object `obj` is passed as the first argument to the method, and inside the method, it is referred to as `self`[6][1][7]. - This is how methods can operate on instance-specific data: `self.attribute` refers to the attribute named `attribute` on the particular instance, not on the class or on other instances[1][6][7]. #### Example: ```python class Car: def __init__(self, model): self.model = model # self is the receiver def show(self): print("Model is", self.model) audi = Car("Audi A4") audi.show() # 'self' inside show() refers to the audi instance ``` - Here, `audi.show()` is equivalent to `Car.show(audi)`. The `audi` object is the receiver. ### Why is the receiver important? - It enables **object-specific state and behavior**. Each instance maintains its own data, and methods can access or mutate that data through `self`[1][6][7]. - It allows methods to call other methods on the same object, e.g., `self.other_method()`[3]. - Without the receiver, methods would not know which instance's data to operate on, and all data would have to be global or class-level. ### How does Python implement this? - When you retrieve a method from an instance (e.g., `method = obj.method`), Python returns a **bound method**—a function object with the receiver (`obj`) already attached as its first argument[5][8]. - When you call the bound method, you only need to supply the remaining arguments; `self` is supplied automatically[5]. ### Summary - **self** is the Pythonic name for the **receiver** of a method call in a class. - It refers to the specific instance on which the method was called. - It gives methods access to instance-specific data and behavior, enabling true object-oriented programming in Python[1][6][7]. > “The 'self' parameter in Python class methods represents the class instance (object). Methods can access and manipulate attributes (variables) and call other methods of the same class using this special variable.”[6] This is a foundational mechanism for encapsulation and polymorphism in Python’s object model. [1] https://www.geeksforgeeks.org/python/self-in-python-class/ [2] https://www.reddit.com/r/learnpython/comments/k9f4q7/could_someone_explain_the_use_of_self_when_it/ [3] https://docs.python.org/3/tutorial/classes.html [4] https://stackoverflow.com/questions/14671218/python-class-methods-changing-self [5] https://stackoverflow.com/questions/70076256/how-do-python-handles-self-attribute-of-a-class-internally-when-the-method-is [6] https://www.w3resource.com/python-interview/explain-the-purpose-of-the-self-parameter-in-python-class-methods.php [7] https://blog.finxter.com/understanding-the-self-in-python-classes/ [8] https://docs.python.org/3/reference/datamodel.html [9] https://softwareengineering.stackexchange.com/questions/422364/is-it-better-to-pass-self-or-the-specific-attributes-in-python-methods [10] https://www.pythonmorsels.com/what-is-self/
Typed Named Tuples
compile-time type annotations: the main feature of named tuples
Classes built by typing.NamedTuple don’t have any methods beyond those that col lections.namedtuple also generates—and those that are inherited from tuple. The only difference is the presence of the annotations class attribute—which Python completely ignores at runtime.
Typed Named Tuples
- the type annotations are ignored by python at runtime
Type Hints 101
No Runtime Effect
Type hints not enforced by compiler & interpreter
- main intent is for use by static analysis tools, at rest
The first thing you need to know about type hints is that they are not enforced at all by the Python bytecode compiler and interpreter.
Works at import time!
that’s why importing libraries may fail.
Variable Annotation Syntax
- variable here refers to the fact that variables are being annotated, not that the type hint is variable.
- the syntax is just
var_name: some_type = a_default_value
The Meaning of Variable Annotations
For classic class definitions, survival of annotations & survival of attributes within annotations
:NOTER_PAGE: (206 . 0.086168)
This applies to the classic class definitions, without the named tuples and such.
This makes sense because there’s no reason to keep the annotations.
surviving of annotation <== if there’s a type hint given
surviving of the attribute in the class <== if there’s a value assignable
Note that the annotations special attribute is created by the interpreter to record the type hints that appear in the source code—even in a plain class. The a survives only as an annotation. It doesn’t become a class attribute because no value is bound to it.6 The b and c are stored as class attributes because they are bound to values.
Annotations are type annotations for immutable attributes
This is because NT is extended from Tuple class.
Contents
If you try to assign values to nt.a, nt.b, nt.c, or even nt.z, you’ll get Attribute Error exceptions with subtly different error messages. Try that and reflect on the messages.
Comment
Because it’s read-only instance attribute and it’s expected to be immutable
using the
@dataclassdecorator allows the attrs to persist as instance attributes:NOTER_PAGE: (208 . 0.488788)
Contents
However, there is no attribute named a in DemoDataClass—in contrast with DemoNTClass from Example 5-11, which has a descriptor to get a from the instances as read-only attributes (that myste‐ rious <_collections._tuplegetter>). That’s because the a attribute will only exist in instances of DemoDataClass. It will be a public attribute that we can get and set, unless the class is frozen. But b and c exist as class attributes, with b holding the default value for the b instance attribute, while c is just a class attribute that will not be bound to the instances.
Comment
when using a decorator, the descriptor for the class that is ONLY type-hinted will only exist in concrete instances of that class.
annotation special attr are for type hints
annotations special attribute is created by the interpreter to record the type hints that appear in the source code—even in a plain class.
More About @dataclass
Don’t set a custom attribute outside of its constructor function!
:NOTER_PAGE: (209 . 0.862182)
Contents
Setting an attribute after init defeats the dict key-sharing memory optimization mentioned in “Practical Consequences of How dict Works” on page 102.
Comment
Reminder: all the attrs for a class should really just be defined within the class itself to benefit from the memory optimisation that it comes with by default
immutability is emulated by methods
Which means it can be bypassed by overriding the implementation of these functions! (the settattr and deattr dunder methods)
emulates immutability by generating setattr and delattr, which raise data class.FrozenInstanceError
Field Options
WARNING: mutable defaults are NOT allowed.
similar to the assignment gotchas where if we do my
arr = [[] * 3], reusing a mutable reference (the inner list) means that the 3 instances all point to the same memory locationwe can how that would be a problematic bug
therefore, it’s illegal to set default values that are mutable when we use dataclasses.
we can use
default_factoryas a solution to this.
default_factoryhelps prevent mutability bugsif a default value is provided that is mutable, then it would mean that many instances can edit the same mutable handle ==> this is a problematic bug. That’s why the default option is only to pass a factory function if you want to assign mutable default values so that each mutable default is a separate reference.
but this won’t apply to custom mutable objects, that’s why it’s a common source of mutable data related bugs l
The default_factory parameter lets you provide a function, class, or any other call‐ able, which will be invoked with zero arguments to build a default value each time an instance of the data class is created. This way, each instance of ClubMember will have its own list—instead of all instances sharing the same list from the class, which is rarely what we want and is often a bug.
mental model for sentinel values
``sentinel value’’
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55### Understanding Sentinel Values **Sentinel values** are special values used in programming to signify that a variable or parameter is missing, not set, or has a specific condition that needs to be distinguished from valid values. They serve as markers that help identify states in data structures or function arguments without conflicting with legitimate data. #### Key Characteristics of Sentinel Values 1. **Uniqueness**: A sentinel value is typically unique and not used as a regular value in the context where it is applied. This uniqueness allows it to serve as a clear indicator of absence or a specific condition. 2. **Common Usage**: - **Function Arguments**: In functions, sentinel values can indicate that an optional parameter was not provided. For example, in Python, you might use `None` or a custom sentinel object to differentiate between "no value" and "a value of None". - **Data Structures**: In data structures like linked lists or trees, sentinel nodes may be used to simplify boundary conditions (e.g., head and tail pointers). 3. **Examples**: ```python # Using None as a sentinel def fetch_data(key, default=None): if key not in my_dict: return default # Return the sentinel if key is missing return my_dict[key] # Using a custom sentinel MISSING = object() def get_value(key, default=MISSING): if key not in my_dict: if default is MISSING: raise KeyError(f"{key} not found") return default return my_dict[key] ``` ### Mental Model for Sentinel Values To form a mental model for sentinel values, consider the **concept of markers or flags** in various contexts: 1. **Etymological Basis**: The term "sentinel" originates from the Latin word "sentinella," meaning "to watch." Just as sentinels guard and signal the presence or absence of something important, sentinel values act as indicators in programming. They help you "watch" for specific conditions in your code. 2. **Mental Model**: Think of sentinel values as **flags on a map**: - Imagine a treasure map where certain locations are marked with flags indicating whether they contain treasure (valid data) or are empty (missing data). - Just like those flags help you navigate the map without confusion, sentinel values guide your logic by clearly indicating when something is absent or when a specific condition applies. 3. **Practical Application**: When designing functions or data structures, consider how you can implement sentinel values to handle edge cases gracefully. This approach can prevent errors and make your code more robust by explicitly managing conditions that would otherwise lead to ambiguity. ### Summary Sentinel values are special markers used to indicate missing or special conditions in programming. They provide clarity and help manage edge cases effectively. By conceptualizing them as flags on a map, you can better understand their role in guiding logic and maintaining code integrity. This mental model emphasizes the importance of clear indicators in navigating complex data scenarios, much like sentinels watch over critical points of interest. Citations: [1] https://www.reddit.com/r/slatestarcodex/comments/83phqz/what_mental_models_do_you_find_to_be_most_helpful/ [2] https://fs.blog/mental-models/ [3] https://pmc.ncbi.nlm.nih.gov/articles/PMC8290163/ [4] https://jamesclear.com/feynman-mental-models [5] https://www.linkedin.com/pulse/10x-your-results-mental-models-mark-green [6] https://forum.valuepickr.com/t/scalability-thinking-mental-models/104746 [7] https://www.safalniveshak.com/latticework-mental-models-active-reading/ [8] https://learn.microsoft.com/ja-jp/globalization/encoding/unicode-standard
Post-init Processing
Allows us to insert logic after the contructor, to do things like calculations and such.
Highlight on page 213
Contents
method generated by @dataclass only takes the arguments passed and assigns them—or their default values, if missing—to
Highlight on page 213
Contents
Common use cases for post_init are validation and computing field values based on other fields.
- Link on page 214: “Inheritance” section of the dataclasses module documentation
Typed Class Attributes
Need to use
ClassVarfrom thetypingmodule.This is a pseudotype Read more here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66Yes, **this is still the standard and recommended way to declare class variables with type hints in the most recent versions of Python (as of Python 3.13)**. ### Why is `ClassVar` Needed? - By default, when you annotate a variable inside a class, **type checkers (like mypy, pyright, or the built-in `dataclasses` module) assume it is an instance variable**—that is, each instance of the class will have its own copy. - If you want to indicate that a variable is a **class variable** (shared across all instances), you must use `typing.ClassVar` in your annotation[1][2]. - This is especially important for tools like `@dataclass`, which will otherwise treat all annotated variables as fields to be included in the instance's `__init__`. ### The Syntax ```python from typing import ClassVar class Example: all_handles: ClassVar[set[str]] = set() ``` - This tells both the type checker and `@dataclass` (if used) that `all_handles` is a class attribute, not an instance attribute. - The type inside `ClassVar[...]` can be any valid type, including generics like `set[str]`. ### Why is this necessary/ugly? - The reason for this "pseudotype" is that Python's variable annotations (PEP 526) are designed to be explicit and unambiguous for static analysis and code generation tools. - Without `ClassVar`, type checkers and dataclasses would treat the variable as an instance field, which is almost always wrong for shared state. ### Is this still the case in Python 3.13+? **Yes.** - The [official Python docs](https://docs.python.org/3/library/typing.html) (as of Python 3.13.5) still require `ClassVar` for class variables in type annotations[2]. - This is also reflected in community best practices and in the implementation of type checkers and the standard library[1][2][3][4]. ### Example with `@dataclass` ```python from dataclasses import dataclass from typing import ClassVar @dataclass class Example: all_handles: ClassVar[set[str]] = set() # Not included as a dataclass field name: str # This is an instance variable ``` - `all_handles` is not included in the generated `__init__`, nor in the instance's `__dict__`. ### Related: `Final` and `ClassVar` - If you want a class variable to be a constant, you can use `Final` from `typing`, but **you cannot combine `Final` and `ClassVar`** in the annotation (see [1]). You must choose one or the other, as combining them is not supported by type checkers. ### References to Search Results - [PEP 526 and usage of ClassVar](https://stackoverflow.com/questions/66285078/how-to-define-final-classvar-variable-in-python)[1] - [Python 3.13 typing documentation](https://docs.python.org/3/library/typing.html)[2] - [Class variables in Python](https://pynative.com/python-class-variables/)[5] **In summary:** Declaring class variables with type hints using `ClassVar[...]` is still required and is the correct, modern, and supported approach in all current and foreseeable future versions of Python. This ensures type checkers and dataclasses handle your class variables as intended. [1] https://stackoverflow.com/questions/66285078/how-to-define-final-classvar-variable-in-python [2] https://docs.python.org/3/library/typing.html [3] https://github.com/python/typing/discussions/1424 [4] https://programming-25.mooc.fi/part-9/5-class-attributes/ [5] https://pynative.com/python-class-variables/ [6] https://docs.python.org/3/tutorial/classes.html [7] https://www.digitalocean.com/community/tutorials/understanding-class-and-instance-variables-in-python-3 [8] https://realpython.com/python-variables/ [9] https://programming-25.mooc.fi/part-8/3-defining-classes/ [10] https://github.com/python/typing/discussions/1636
- Initialization Variables That Are Not Fields
@dataclass Example: Dublin Core Resource Record
- Link on page 217: Dublin Core
- Link on page 217: Dublin Core
Data Class as a Code Smell
- Data Class as Scaffolding
value: dataclasses are a good way to do temp wire-ups / stubs
In this scenario, the data class is an initial, simplistic implementation of a class to jump-start a new project or module. With time, the class should get its own methods, instead of relying on methods of other classes to operate on its instances. Scaffolding is temporary;
- Data Class as Intermediate Representation
Pattern Matching Class Instances
pattern matching in python is new
It’s very similar to elixir’s pattern matching and is different from a typical case-switch construct
it typically uses the
__match_args__dunder declaration, will be discussed in a later part of the book
Here’s some details on it
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74Python's `match-case` syntax, introduced in Python 3.10, offers a powerful alternative to traditional `switch-case` constructs found in other programming languages like C, C++, and Java. Here’s a detailed comparison of Python's `match-case` with traditional `switch-case` syntax. ### Key Differences Between Python's `match-case` and Traditional `switch-case` 1. **Pattern Matching vs. Value Matching**: - **Python's `match-case`**: Supports **pattern matching**, which means it can match complex data structures, such as lists, tuples, and even class instances. It allows for destructuring and extracting values from these structures. ```python match some_value: case (x, y): # Matches a tuple with two elements print(f"Matched a tuple with x={x} and y={y}") case _: print("No match") ``` - **Traditional `switch-case`**: Typically only matches against scalar values (like integers or strings) and does not support destructuring. It evaluates the expression and compares it against constant cases. ```c switch (value) { case 1: printf("One"); break; case 2: printf("Two"); break; default: printf("Default case"); } ``` 2. **Wildcards and Default Cases**: - **Python's `match-case`**: Uses the underscore (`_`) as a wildcard to catch all unmatched cases, similar to an `else` statement. - **Traditional `switch-case`**: Uses a `default` case for handling unmatched values, but it requires explicit declaration. 3. **Multiple Patterns**: - **Python's `match-case`**: Allows combining multiple patterns using the pipe operator (`|`) for cases that should execute the same block of code. ```python match day: case "Saturday" | "Sunday": print("It's the weekend!") case _: print("It's a weekday.") ``` - **Traditional `switch-case`**: Requires separate cases for each value or uses fall-through behavior (if not explicitly handled with `break`). 4. **No Break Statements Needed**: - **Python's `match-case`**: Automatically exits after executing the matched case block, eliminating the need for `break` statements to prevent fall-through. - **Traditional `switch-case`**: Requires explicit use of `break` to prevent fall-through to subsequent cases. 5. **Guard Conditions**: - **Python's `match-case`**: Supports guard conditions using an `if` statement within the case clause to add additional checks. ```python match details: case [amt, duration] if amt < 10000: return amt * 0.1 * duration case [amt, duration] if amt >= 10000: return amt * 0.15 * duration ``` - **Traditional `switch-case`**: Does not natively support guard conditions; you would need to use additional if-else statements. ### Summary - Python's `match-case` syntax is more flexible and powerful than traditional `switch-case`, allowing for complex pattern matching and destructuring of data structures. - It simplifies code by removing the need for break statements and supports more expressive patterns through guards and multiple patterns. - While both constructs serve similar purposes in controlling flow based on variable values, Python's approach aligns more closely with modern programming paradigms that emphasize readability and expressiveness. In conclusion, while Python's `match-case` serves a similar purpose to traditional switch-case statements in other languages, it introduces significant enhancements that make it more versatile and easier to use in many scenarios. Citations: [1] https://www.geeksforgeeks.org/python-match-case-statement/ [2] https://www.tutorialspoint.com/python/python_matchcase_statement.htm [3] https://www.youtube.com/watch?v=L7tT0NZF-Ag [4] https://www.datacamp.com/tutorial/python-switch-case [5] https://discuss.python.org/t/providing-a-shorthand-match-case-statement/21421 [6] https://stackoverflow.com/questions/74655787/match-case-statement-with-multiple-or-conditions-in-each-case [7] https://www.youtube.com/watch?v=prB2lfuPDAc [8] https://docs.python.org/pt-br/3.13/whatsnew/3.10.html
Designed to match classes instances by types and by attrs
Contents
Class patterns are designed to match class instances by type and—optionally—by attributes. The subject of a class pattern can be any class instance, not only instances of data classes.10
Simple Class Patterns
- Link on page 222: PEP 634—
- Link on page 222: “Class Patterns”
- Link on page 222: Structural Pattern Matching: Specification
Keyword Class Patterns
Captures also work with this syntax
Contents
Keyword class patterns are very readable, and work with any class that has public instance attributes, but they are somewhat verbose.
Positional Class Patterns
The pattern for an attribute can be defined positionally as well.
Named collectors / captures still work with this.
Chapter Summary
- Link on page 225: PEP 526—Syntax for Variable Annotations
Dataclasses as a code smell
Contents
warned against possible abuse of data classes defeating a basic principle of object-oriented programming: data and the functions that touch it should be together in the same class. Classes with no logic may be a sign of misplaced logic.
Further Reading
- Link on page 226: PEP 557—Data Classes
- Link on page 226: dataclasses
- Link on page 226: PEP 557
- Link on page 226: “Why not just
- Link on page 226: “Why not just use namedtuple?”
- Link on page 226: “Rationale” section
- Link on page 226: use typing.NamedTuple?”
- Link on page 226: “Ultimate guide to
- Link on page 226: RealPython.com
- Link on page 226: data classes in Python 3.7”
- Link on page 226: “Dataclasses: The code generator
- Link on page 226: to end all code generators” (video)
- Link on page 226: attrs project
- Link on page 227: dis‐
- Link on page 227: “The One Python Library Everyone Needs”
- Link on page 227: cussion of alternatives
- Link on page 227: cluegen
- Link on page 227: data class code smell
- Link on page 227: Refactoring Guru
- Link on page 227: “The Jargon File”
- Link on page 227: “Guido”
- Link on page 228: PEP 484—Type Hints
- Link on page 228: attrs
- Link on page 228: PEP 526
Highlight on page 228
Contents
Finally, if you want to annotate that class attribute with a type, you can’t use regular types because then it will become an instance attribute. You must resort to that pseu‐ dotype ClassVar annotation:
Underline on page 228
Contents
Here we are
- Link on page 228: PEP 557—Data Classes
Chapter 6. Object References, Mutability, and Recycling
What’s New in This Chapter
Variables Are Not Boxes, they are labels
updated mental model and language
We should see it as a “to bind” instead of “to assign” whereby a name is bound to an object.
A sticky note is a better image rather than a box.
Identity, Equality, and Aliases
id() checking
the
isoperator does id checking, the=operator uses whatever the__eq__is defined as (typically value-based checking).programming. Identity checks are most often done with the is operator, which compares the object IDs, so our code doesn’t need to call id() explicitly.
Choosing Between
==andisfor equality check, use
==for identity check, use
is, this avoids the direct use ofid()sinceisis used when comparing with singletons – typically justNoneSo the correct way to do None check is via a singleton
However, if you are comparing a variable to a singleton, then it makes sense to use is. By far, the most common case is checking whether a variable is bound to None. This is the recommended way to do it: x is None And the proper way to write its negation is: x is not None None is the most common singleton we test with is.
- Default to
==if unsure
isis faster than==because it can’t be overloaded
The Relative Immutability of Tuples
this is why tuples are unhashable, because they are container types and though they are immutable, their containees may not be
Copies Are Shallow by Default
shallow copying is more of a problem if mutable items within the inner nestings
This saves memory and causes no problems if all the items are immutable. But if there are mutable items, this may lead to unpleasant surprises.
shallow-copy negative example
the example below will demonstrate how when the inner element is mutable, then only the reference is copied, so if we modify that, then the original mutable entity gets mutated.
1 2 3 4 5 6 7 8 9 10l1 = [3, [66, 55, 44], (7, 8, 9)] l2 = list(l1) l1.append(100) l1[1].remove(55) # removal removes from both of the nested arrays since it's the same reference print('l1:', l1) print('l2:', l2) l2[1] += [33, 22] l2[2] += (10, 11) print('l1:', l1) print('l2:', l2)
- Deep and Shallow Copies of Arbitrary Objects
complexity in cyclical references
if it’s a naive implementation, circular references can give deepcopying an issue, but the usual deepcopy will handle things alright, not to worry
this is because deepcopy does a graph-traversal of the original object and uses a memo table to keep track of references.
Note that making deep copies is not a simple matter in the general case. Objects may have cyclic references that would cause a naïve algorithm to enter an infinite loop. The deepcopy function remembers the objects already copied to handle cyclic refer‐ ences gracefully.
Function Parameters as References
“Call by sharing”/“pass by reference” is the only mode of parameter passing in python.
This is usually the case for OOP languages in general (JS, Ruby, Java [though in Java, primitive types are call by value])
Mutable Types as Parameter Defaults: Bad Idea
the default params, if mutable and used, will all point to the same SHARED mutable obj since the params are just aliases to it
issue with mutable defaults explains why
Noneis commonly used as the default value for parameters that may receive mutable values.demonstrates, when a HauntedBus is instantiated with passengers, it works as expected. Strange things happen only when a HauntedBus starts empty, because then self.passengers becomes an alias for the default value of the passengers parameter. The problem is that each default value is evaluated when the function is defined—i.e., usually when the module is loaded—and the default values become attributes of the function object. So if a default value is a mutable object, and you change it, the change will affect every future call of the function.
- Defensive Programming with Mutable Parameters
Principle of Least Astonishment == no surprising side-effects
TwilightBus violates the “Principle of least astonishment,” a best practice of interface design.3 It surely is astonishing that when the bus drops a student, their name is removed from the basketball team roster.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21### TL;DR: Principle of Least Astonishment (POLA) The **Principle of Least Astonishment** (POLA), also known as the **Principle of Least Surprise**, is a design guideline in user interface and software design that emphasizes creating systems that behave in ways users expect. The main idea is to minimize confusion and surprises, ensuring that interactions are intuitive and predictable. #### Key Points: - **User Expectations**: Systems should align with users' mental models and past experiences to reduce cognitive load and learning curves. - **Behavior Consistency**: Components of a system should operate consistently, following common conventions to avoid unexpected behavior. - **Applications**: POLA applies across various aspects of design, including user interfaces, API design, and error handling. - **Benefits**: Adhering to POLA leads to improved usability, reduced development time, enhanced maintainability, and increased user satisfaction. By following the Principle of Least Astonishment, designers can create more intuitive and user-friendly applications that enhance overall user experience. Citations: [1] https://pointjupiter.com/ultimate-guide-principle-of-least-astonishment-pola/ [2] https://en.wikipedia.org/wiki/Least_surprise [3] https://deviq.com/principles/principle-of-least-astonishment/ [4] https://usertimes.io/2018/12/07/the-principle-of-least-astonishment/ [5] https://www.centercode.com/glossary/principle-of-least-surprise [6] https://www.linkedin.com/pulse/principle-least-surprise-incus-data-pty-ltd [7] https://dovetail.com/ux/principle-of-least-surprise/ [8] https://barrgroup.com/blog/how-endianness-works-big-endian-vs-little-endianrule of thumb on when to alias vs make a copy on mutable args
Just make a copy if you’re not sure (when you’re going to be consuming a mutable argument).
Unless a method is explicitly intended to mutate an object received as an argument, you should think twice before aliasing the argu‐ ment object by simply assigning it to an instance variable in your class. If in doubt, make a copy. Your clients will be happier. Of course, making a copy is not free: there is a cost in CPU and mem‐ ory. However, an API that causes subtle bugs is usually a bigger problem than one that is a little slower or uses more resources.
del and Garbage Collection
del is a statement and not a function, that’s why ew don’t do del(x), we do del x (though, this will work too)
Weak references are useful to have pointers but not affect refcount for an obj
- good to do monitoring / caching activities using weak references
- see this for more elaboration: Weak References | Fluent Python, the lizard book
- To inspect whether an object is still alive without holding a strong reference, Python provides the weakref module. A weakref to an object returns None if the object has been garbage collected, effectively giving you a safe way to test “dangling-ness”:
1 2 3 4 5 6 7 8 9 10 11 12 13 14import weakref class MyClass: pass obj = MyClass() obj_id = id(obj) weak_obj = weakref.ref(obj) print(weak_obj()) # <MyClass object at ...> del obj print(weak_obj()) # None, indicating the original object was garbage collected
This works because finalize holds a weak reference to {1, 2, 3}. Weak references to an object do not increase its reference count. Therefore, a weak reference does not prevent the target object from being garbage collected. Weak references are useful in caching applica‐ tions because you don’t want the cached objects to be kept alive just because they are referenced by the cache.
we can actually use ctypes to read memory spaces directly!
this memory location will have to be casted first though.
1 2 3 4 5 6 7 8 9import ctypes x = 42 address = id(x) # Use ctypes to cast the address back to a Python object and get its value value = ctypes.cast(address, ctypes.py_object).value print(value) # Output: 42
the
__del__method is more like a fini teardownunlikely that we actually will need to implement it.
if implemented for a class, it gets called by the interpreter before freeing up the memory.
also kind of depends on the implementation of python itself, e.g. some might keep track of more than just refcounts.
Tricks Python Plays with Immutables \(\rightarrow\) Interned Immutables
Interning as an optimisation technique for the internal python implementation
Basically some strings and common ints are shared memory, avoids unnecessary duplication.
- won’t work if you use
.copy() - won’t work if you use
[:]
NOTE: What is interened or not can’t be always determined because that implementation detail is undocumented.
NOTE: therefore, for immutables, always check sameness using
= instead of =isThe sharing of string literals is an optimization technique called interning. CPython uses a similar technique with small integers to avoid unnecessary duplication of num‐ bers that appear frequently in programs like 0, 1, –1, etc. Note that CPython does not intern all strings or integers, and the criteria it uses to do so is an undocumented implementation detail. Never depend on str or int interning! Always use == instead of is to compare strings or integers for equality. Interning is an optimi‐ zation for internal use of the Python interpreter.
- won’t work if you use
Chapter Summary
Practical Consequences of using references
- simple assignment doen’t create copies
- for augmented assignments e.g.
+=,*=, it depends on the LHS variable:- if bound to immutable object, then it creates new objects
- if bound to mutable object, then it modifies that object in place
- re-binding: assigning a new value to an existing variable doesn’t change the object previously bound to it, the var is just boudn to a different object.
- function params are passed as aliases
- mutable objects may get mutated unless the consumer function copies it
- it’s dangerous to use mutable default values \(\implies\) that’s why the convention is to use
Noneinstead.
Further Reading
Object identity becomes important only when objects are mutable
- if everything was immutable, it makes no difference whether variables hold actual objects or they hold refs to shared objects (intered). Just comparing them by value would hanve been sufficient.
mutable objects end up being the reason why threaded programming is hard
- if multiple threads mutate objects and the synchronization is not handled correctly, then it leads to corrupted data
GC used to be just refcounts, but that can leak memory (e.g. when there are refcycles to unreachable objects, leading to cyclic garbage). Current GC is a generational GC.
Mental Model:
The memory is thought of as having generations: each generation is a collection of objects grouped by how long they’ve existed.
Younger generations (new objects) are collected (checked for unreachable cycles) frequently. Older generations (objects that survived earlier collections) are checked less often.
More elaboration:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54### Generational Garbage Collector in CPython: Mental Model and Rationale #### 1. **Reference Counting Only: Its Limits and Memory Leaks** - **Reference Counting** (the core memory management scheme in CPython) works by keeping a count of how many references exist to each object. When the count drops to zero, memory is released immediately. - **Primary shortcoming:** If objects reference each other (e.g., two lists referencing each other), but nothing outside references them, neither’s count drops to zero. They become **"garbage"**—unreachable—but their counts never reach zero. This is a **classic memory leak**: unused memory that cannot be reclaimed. #### 2. **Generational GC: Solving Cycles and Leaks** To address cyclical references—and reduce overhead—CPython complements refcounting with a **generational garbage collector** (`gc` module). **Mental Model:** - The memory is thought of as having *generations*: each generation is a collection of objects grouped by how long they've existed. - **Younger generations** (new objects) are *collected* (checked for unreachable cycles) frequently. **Older generations** (objects that survived earlier collections) are checked *less* often. #### 3. **Why Generational GC Is Effective** - **Empirical observation:** Most objects in Python die young (they become unreachable soon after they're created). Therefore, checking *new* objects often is efficient. - **Cyclic collection:** - During collection, the GC looks for reference cycles—sets of objects referring only to each other but not from elsewhere. - The GC can safely reclaim all objects in such cycles. - By extending beyond simple refcounting, the cycle detector enables memory occupied by unreachable cycles to be safely released. - **Old objects that survive collections are promoted to older generations**; these are checked less frequently, reducing unnecessary overhead. #### 4. **Generational Structure in CPython** CPython typically uses *three generations*: - **Generation 0**: Collected (checked) most frequently; new objects start here. - **Generation 1**: Objects promoted from gen 0 if they survive one collection. - **Generation 2**: The oldest and least frequently collected generation; objects promoted from gen 1 after surviving further collections. Collections trigger: - Automatically based on allocation thresholds. - Explicitly via the `gc.collect()` API. #### 5. **Memory Leak Solution: How It Works** - **Pure reference counting** cannot detect cyclic garbage, leading to leaks. - **Generational GC** *detects* and *collects* cyclically-linked groups of unreachable objects, returning their memory to the system. - Thus, even if the reference count of an object never drops to zero due to a reference cycle, the GC will eventually detect and collect it if it has become unreachable. #### 6. **Practical Takeaways for Tech Leaders** - **Mental Model:** CPython’s memory management is twofold—reference count for immediacy and generational GC for cycle detection. - **Leak prevention:** Programmers need not (and usually cannot) manually break all cycles; the GC rescues memory otherwise lost in cycles. - **Performance:** The generational design reduces overhead by focusing frequent scans on objects most likely to be garbage. #### 7. **Further Reading and References** - The CPython documentation for the `gc` module provides details and empirical thresholds for collection. - Deep dives into Python’s memory management explain the symbiosis of refcounting and generational GC as a pragmatic solution balancing immediacy, overhead, and completeness (detection of cycles). **In summary:** A generational garbage collector in CPython efficiently manages memory by combining reference counting (for immediate reclamation) with cycle detection (generational collection). This hybrid approach solves the memory leak issue inherent in pure reference-counted systems—cycles are detected and collected—making Python both safe and performant for real-world programs.
Rebinding a ref within a fn body doesn’t effect changes outside the fn because it’s a copy of the ref
because the function gets a copy of the reference in an argument, rebinding it in the function body has no effect outside of the function.
Part II. Functions as Objects
Chapter 7. Functions as First-Class Objects
Definition of a First Class Object
Programming language researchers define a “first-class object” as a program entity that can be:
- Created at runtime
- Assigned to a variable or element in a data structure
- Passed as an argument to a function
- Returned as the result of a function
What’s New in This Chapter
Treating a Function Like an Object
the
__doc__attribute is typically used for thehelp(<fn_name>)having fist-class functions enables programming in a functional style
Higher-Order Functions
argument and return type are both functions
applyhas been deprecated because we can define**kwargsnowso a function can be defined as
fn(*args, **kwargs)
Modern Pythonic Replacements for
map,filter, andreducemapandfilterreturn generators \(\implies\) we can just directly define genexps now instead.reduceis no longer a builtin, KIV this for a later chapter in this book.
Anonymous Functions
The best use of anonymous functions is in the context of an argument list for a higher-order function.
e.g.
sorted(fruits, key=lambda word:word[::-1])
python anon functions have to be pure functions, limited language features available in lambda definition
However, the simple syntax of Python limits the body of lambda functions to be pure expressions. In other words, the body cannot contain other Python statements such as while, try, etc. Assignment with = is also a statement, so it cannot occur in a lambda.
:=assignment syntax existsThe new assignment expression syntax using := can be used—but if you need it, your lambda is probably too complicated and hard to read, and it should be refac‐ tored into a regular function using def.
⭐️ The Nine Flavors of Callable Objects
()is the call operator- genrators, native coroutines and async generator functions are different from the rest of the callables types in that their return values are never applicaitons data, it’s objects that need further processing to yiled application data / do useful work.
- callable: User-defined Functions
- callable: builtin functions
e.g.
len
- callable: builtin methods
methods implemented in C e.g.
dict.get
- callable: methods:
fns defined in the body of a class
- callable: Class
classes are callable, it calls
__new__\(\rightarrow\)__init__we an override
__new__actuallythere’s no
newoperator in Python
When invoked, a class runs its new method to create an instance, then init to initialize it, and finally the instance is returned to the caller. Because there is no new operator in Python, calling a class is like calling a function.2
- callable: class instances
if we define a call method in the class
- callable: Generator Functions
- they have
yieldin the function body – when called, they return a generator object
Generator functions Functions or methods that use the yield keyword in their body. When called, they return a generator object.
- callable: native coroutine functions
- functions that are
async def\(\rightarrow\) when called, they return a coroutine object
Native coroutine functions Functions or methods defined with async def. When called, they return a coroutine object.
- callable: async generator functions
- have a
yield-> returns generators - are
async def-> generators are to be used withasync for
Asynchronous generator functions Functions or methods defined with async def that have yield in their body. When called, they return an asynchronous generator for use with async for. Added in Python 3.6.
User-Defined Callable Types
this relates to class instances that work as callable objects.
usecases:
the main idea is really to have objects that can store their own internal state and are callable.
Here’s two concrete cases:
A class implementing
__call__is an easy way to create function-like objects that have some internal state that must be kept across invocations, like the remaining items in the BingoCageDecorators that need to remember state between calls of the decorator e.g. the
@cachedecoratorthis is also useful to split a complex implementation into staged, multi-decorator implementations.
we’re familiar with this from using frameworks like flask or django where functions can have many decorators applies that does some pre-processing.
Practical Takeaways
Mental Model: Think of the decorator stack as a pipeline: each decorator acts before or after your main logic, transforming input, output, or context as needed.
Framework idioms: Nearly every Flask or Django extension adds its value via decorators to manage permissions, caching, rate limits, etc.
Custom use: You can easily define your own decorators to factor out repeated steps in your app for preprocessing (e.g., parameter parsing), postprocessing (e.g., formatting responses), or injecting cross-cutting security checks.
In summary, the practice of splitting implementation using decorators (as in Flask/Django) is a core idiom for composing, reusing, and organizing web application logic in Python frameworks—and is a concrete, high-impact use of the broader decorator pattern described previously
elaboration on the splitting up part:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80Splitting a concrete implementation into separate methods in Python using decorators typically refers to using decorators as a modular way to extend, preprocess, or postprocess your functions—effectively breaking up a monolithic function into composable steps. Decorators allow you to separate concerns and add reusable behaviors before or after the core logic, without modifying the original function directly. ## Key Concepts - **Decorators** are functions (or classes) that take another function/method, wrap it with additional behavior, and return the wrapped function. - This is useful for **"splitting" implementation concerns**: e.g., one decorator handles logging, another argument validation, another result transformation, etc. - Using multiple decorators, you can stack behaviors, creating a pipeline of processing stages for your function[1][5]. ## Example: Splitting String Processing Steps Suppose you have a function that returns a string and you want to: 1. Convert the result to uppercase. 2. Then split it into words. You can write two decorators and apply them: ```python import functools def uppercase_decorator(func): @functools.wraps(func) def wrapper(*args, **kwargs): result = func(*args, **kwargs) return result.upper() return wrapper def split_string_decorator(func): @functools.wraps(func) def wrapper(*args, **kwargs): result = func(*args, **kwargs) return result.split() return wrapper @split_string_decorator @uppercase_decorator def greet(): return 'hello world' print(greet()) # Output: ['HELLO', 'WORLD'] ``` Here, the function’s logic is split: first uppercase conversion, then string splitting—each in its own decorator[1][5]. ## Why Use This Pattern? - **Separation of concerns**: Each decorator encapsulates a single aspect, making your code easier to maintain, test, and reuse[1][6][9]. - **Composable behaviors**: You can stack/reorder behaviors as needed. - **Cleaner implementation**: The core function stays focused on its business logic. ## Common Uses - **Argument or result preprocessing/postprocessing** (e.g., stripping strings, timing execution, error handling)[7]. - **Cross-cutting concerns** like authentication, logging, caching. - **Extending methods in classes** with shared behaviors (see below caveat when decorating class methods)[3][4][8]. ## Important Caveats - When applying decorators to class methods, the decorator receives either a function or a method, depending on implementation. You may need to ensure your decorator handles `self`/`cls` correctly, or else prefer using `functools.wraps` and testing thoroughly[3][4][8]. - The order of decorator application matters, especially if each processes return values or arguments—always document and manage dependencies between them[1][5]. ## Summary Table | Use Case | Approach | Notes | |------------------|------------------------------|---------------------------------| | Preprocessing | Decorator before function | E.g., strip, validate inputs | | Postprocessing | Decorator after function | E.g., format, cache results | | Cross-cutting | Multiple stacked decorators | E.g., logging + auth + cache | In summary, splitting a concrete implementation using decorators lets you modularize, extend, and compose functionality in clear, reusable units[1][6][9]. This is a foundational pattern in Python for writing clean, maintainable, and flexible code. [1] https://www.datacamp.com/tutorial/decorators-python [2] https://www.thepythoncodingstack.com/p/demystifying-python-decorators [3] https://stackoverflow.com/questions/62857278/different-behavior-when-implementing-a-decorator-in-python-with-a-function-or-a [4] http://blog.dscpl.com.au/2014/01/how-you-implemented-your-python.html [5] https://www.youtube.com/watch?v=NyHuBGqCBII [6] https://www.codingem.com/what-are-python-decorators/ [7] https://stackoverflow.com/questions/13698549/python-decorator-for-function-argument-preprocessing [8] https://github.com/GrahamDumpleton/wrapt/blob/develop/blog/10-performance-overhead-when-applying-decorators-to-methods.md [9] https://itnext.io/python-decorators-demystified-cef81d7e986d [10] https://refactoring.guru/design-patterns/decorator/python/exampleelaboration linked to flask / django:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78Your observation is highly relevant: **Flask and Django make extensive use of Python decorators to split and modularize concrete implementations of web functionality.** This pattern is foundational to how these frameworks are built and used. ### Contextualized Explanation with Flask/Django - **In Flask:** Every view (endpoint) is just a function, and decorators are used to transparently inject additional behavior before or after your function executes. The classic example is `@app.route`, which registers the function as a route handler. Beyond routing, decorators are used extensively for **authentication (`@login_required`), templating, caching, API argument validation, CORS, response formatting, and more**.[1][2][5] - For example, a "login required" decorator checks authentication before the underlying view runs: ```python from functools import wraps from flask import g, request, redirect, url_for def login_required(f): @wraps(f) def decorated_function(*args, **kwargs): if g.user is None: return redirect(url_for('login', next=request.url)) return f(*args, **kwargs) return decorated_function @app.route('/secret') @login_required def secret_view(): ... ``` Here, **the authentication check is split out from your business logic** into a reusable decorator[5]. - Another example, templating can be split using a decorator. Rather than explicitly rendering a template in every view, you can return just the context dictionary, and a decorator handles the rendering: ```python def templated(template): def decorator(f): @wraps(f) def decorated_function(*args, **kwargs): ctx = f(*args, **kwargs) return render_template(template, **ctx) return decorated_function return decorator @app.route('/') @templated('index.html') def index(): return dict(value=42) ``` This **splits view organization (data preparation) from view rendering**[1][5]. - **In Django:** The pattern is similar, although Django adds a distinction between **middleware** (which wraps the whole request/response pipeline) and **decorators** (which wrap only specific views). - Decorators like `@login_required`, `@require_POST`, `@csrf_exempt`, etc., **modularize cross-cutting concerns** so they can be composed and reused across multiple views. - Django middleware shares some similarities with decorators, acting at a broader scope[4]. ### Why Frameworks Encourage This - **Separation of concerns:** Decorators allow you to extract generic, orthogonal logic (like permissions, logging, or caching) from the core business function, improving maintainability and testability. - **Composable behaviors:** By stacking multiple decorators (order matters), you can chain checks, transformations, or wrappers around your views in a clear, declarative fashion[2]. - **Minimizing boilerplate:** You avoid repetition—rather than implementing access checks, error handling, or formatting logic in each view, you write these as reusable decorators once. ### Practical Takeaways - **Mental Model:** Think of the decorator stack as a pipeline: each decorator acts before or after your main logic, transforming input, output, or context as needed. - **Framework idioms:** Nearly every Flask or Django extension adds its value via decorators to manage permissions, caching, rate limits, etc. - **Custom use:** You can easily define your own decorators to factor out repeated steps in your app for preprocessing (e.g., parameter parsing), postprocessing (e.g., formatting responses), or injecting cross-cutting security checks. In summary, **the practice of splitting implementation using decorators (as in Flask/Django) is a core idiom for composing, reusing, and organizing web application logic in Python frameworks**—and is a concrete, high-impact use of the broader decorator pattern described previously[1][2][5]. --- [1]: View Decorators — Flask Documentation (3.1.x) [2]: Advanced patterns for views and routing - Explore Flask [4]: Are middlewares an implementation of the Decorator ... [5]: 12. View Decorators [1] https://flask.palletsprojects.com/en/stable/patterns/viewdecorators/ [2] http://explore-flask.readthedocs.org/en/latest/views.html [3] https://www.geeksforgeeks.org/python/decorator-method-python-design-patterns/ [4] https://stackoverflow.com/questions/48696631/are-middlewares-an-implementation-of-the-decorator-pattern [5] https://tedboy.github.io/flask/patterns/viewdecorators.html [6] https://flask.palletsprojects.com/en/stable/design/ [7] https://moldstud.com/articles/p-flask-and-restful-design-patterns-a-practical-overview-for-developers [8] https://stackoverflow.com/questions/48248771/design-patterns-for-flask-api-implementation/63376123 [9] https://python.plainenglish.io/the-magic-of-python-decorators-from-basics-to-advanced-techniques-94d25dc5f920 [10] https://dev.to/senichimaro/flask-decorator-something-57gd
checking if something is callable
just use the
callable()builitn and it will give us a boolean on whether it’s callable
for custom obj to be callable, just have to implement
__call__arbitrary Python objects may also be made to behave like functions. Implementing a call instance method is all it takes.
- usecase - example use case could be having an alias to a default func within the class e.g.
bingo.pick()andbingo()
- usecase - example use case could be having an alias to a default func within the class e.g.
usecase - implementing decorators that hold state across decorator invocation
:NOTER_PAGE: (270 0.4916420845624386 . 0.35096774193548386)
Another good use case for call is implementing decora‐ tors. Decorators must be callable, and it is sometimes convenient to “remember” something between calls of the decorator (e.g., for memoization—caching the results of expensive computations for later use) or to split a complex implementation into separate methods. The functional approach to creating functions with internal state is to use closures. Closures, as well as decorators, are the subject of Chapter 9.
closures are the functional approach to having functions with internal state (in contrast to decorators being used for this same purpose)
KIV this for a future chapter (chapter 9)
From Positional to Keyword-Only Parameters
Python’s argument declaration features.
This part is about argument captures when defining functions.
There’s two types of interesting ways to pass variadic params:
- positional
*args - keyword based
**kwargs
NOTE: the usual params can always be passed in keyword fashion (unless it’s positional-only)
Keyword-only parameters
There’s two types of argument passing to consider when writing functions:
variable positional args
accepting multiple positional arguments as tuple using
*<arg_name>this allows us to have variadic params
this gives us a positional tuple for these args
``def tag(name, *content, class_=None, **attrs):’’
we can define a keyword-only argument signature for functions
To specify keyword-only arguments when defining a function, name them after the argument prefixed with
*.- if don’t want to support variable position args, then do
def f(a, *, b):
Keyword-only arguments are a feature of Python 3. In Example 7-9, the class_ parameter can only be given as a keyword argument—it will never capture unnamed positional arguments. To specify keyword-only arguments when defining a function, name them after the argument prefixed with *. If you don’t want to support variable positional arguments, then just do this: def f(a, *, b):
- if don’t want to support variable position args, then do
Positional-Only Parameters (using
/)defining position-only params to a function
e.g.
def divmod(a,b,/)after the
/we can specify args as per usualTo define a function requiring positional-only parameters, use / in the parameter list. This example from “What’s New In Python 3.8” shows how to emulate the divmod built-in function: def divmod(a, b, ): return (a / b, a % b) All arguments to the left of the / are positional-only. After the /, you may specify other arguments, which work as usual.
Packages for Functional Programming
The intent wasn’t to support the typical functional paradigms but there is support.
The operator module is for useful operations, the functools modules is for useful higher order functions.
functools also has some higher order functions that can be used as decorators (e.g. cache, singledispatch)
The operator Module
the operator module has a bunch of callable functions that we can use as params for higher order functions.
TO_HABIT: use
itemgetterandattrgettermore when accessing nested objects!
provides function equivalents to operators for trivial things
These are callable functions, e.g. they are
itemgetter: Essentially, itemgetter(1) creates a function that, given a collection, returns the item at index 1. That’s easier to write and read than lambda fields: fields[1], which does the same thing.attrgetter:attrgettersupports nested accesses:NOTER_PAGE: (275 0.24311023622047243 . 0.09819121447028424)
A sibling of itemgetter is attrgetter, which creates functions to extract object attributes by name. If you pass attrgetter several attribute names as arguments, it also returns a tuple of values. In addition, if any argument name contains a . (dot), attrgetter navigates through nested objects to retrieve the attribute.
attrgetter demo
:NOTER_PAGE: (275 0.4183070866141732 . 0.09819121447028424)
Example 7-14. Demo of attrgetter to process a previously defined list of namedtuple called metro_data (the same list that appears in Example 7-13) >>> from collections import namedtuple >>> LatLon = namedtuple(‘LatLon’, ’lat lon’) >>> Metropolis = namedtuple(‘Metropolis’, ’name cc pop coord’) >>> metro_areas = [Metropolis(name, cc, pop, LatLon(lat, lon)) … for name, cc, pop, (lat, lon) in metro_data] >>> metro_areas[0] Metropolis(name=‘Tokyo’, cc=‘JP’, pop=36.933, coord=LatLon(lat=35.689722, lon=139.691667)) >>> metro_areas[0].coord.lat 35.689722 >>> from operator import attrgetter >>> name_lat = attrgetter(’name’, ‘coord.lat’) >>> >>> for city in sorted(metro_areas, key=attrgetter(‘coord.lat’)): … print(name_lat(city)) … (‘São Paulo’, -23.547778) (‘Mexico City’, 19.433333) (‘Delhi NCR’, 28.613889) (‘Tokyo’, 35.689722) (‘New York-Newark’, 40.808611)
also can refer to this perplexity overview of what attrgetter can do:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107The `operator.attrgetter` function in Python is a convenient way to create a callable that retrieves attributes from objects. It can be particularly useful when working with deeply nested dictionaries or objects. Below are examples demonstrating how to use `operator.attrgetter` for accessing values within a deeply nested dictionary structure. ### Example 1: Accessing Nested Attributes in Objects Suppose you have a class structure representing a person and their address: ```python from operator import attrgetter class Address: def __init__(self, city, state): self.city = city self.state = state class Person: def __init__(self, name, address): self.name = name self.address = address # Create instances of Address and Person address1 = Address("New York", "NY") address2 = Address("Los Angeles", "CA") person1 = Person("Alice", address1) person2 = Person("Bob", address2) # List of persons people = [person1, person2] # Use attrgetter to access nested attributes get_city = attrgetter('address.city') cities = list(map(get_city, people)) print(cities) # Output: ['New York', 'Los Angeles'] ``` ### Example 2: Accessing Nested Values in a Dictionary If you have a nested dictionary structure, you can use `attrgetter` to retrieve values from it. Here’s an example: ```python from operator import itemgetter # Nested dictionary structure data = [ {"name": "Alice", "location": {"city": "New York", "state": "NY"}}, {"name": "Bob", "location": {"city": "Los Angeles", "state": "CA"}}, ] # Accessing the city using itemgetter for nested dictionaries get_city = itemgetter('location') cities = [itemgetter('city')(get_city(person)) for person in data] print(cities) # Output: ['New York', 'Los Angeles'] ``` ### Example 3: Combining Multiple Attributes You can also use `attrgetter` to fetch multiple attributes at once. For instance, if you want to get both the city and state from the nested structure: ```python from operator import attrgetter class Address: def __init__(self, city, state): self.city = city self.state = state class Person: def __init__(self, name, address): self.name = name self.address = address # Create instances of Address and Person address1 = Address("New York", "NY") address2 = Address("Los Angeles", "CA") person1 = Person("Alice", address1) person2 = Person("Bob", address2) # List of persons people = [person1, person2] # Use attrgetter to access both city and state get_location = attrgetter('address.city', 'address.state') locations = list(map(get_location, people)) print(locations) # Output: [('New York', 'NY'), ('Los Angeles', 'CA')] ``` ### Summary - **`operator.attrgetter`**: This function is useful for creating callables that can retrieve attributes from objects. It works well with nested structures. - **Accessing Nested Attributes**: You can easily access deeply nested attributes using `attrgetter`, which simplifies your code and improves readability. - **Combining Attributes**: You can retrieve multiple attributes at once by passing them as arguments to `attrgetter`. These examples illustrate how `operator.attrgetter` can be effectively used for accessing nested attributes in both object-oriented and dictionary-based data structures in Python. Citations: [1] https://florian-dahlitz.de/articles/introduction-to-pythons-operator-module [2] https://note.nkmk.me/en/python-operator-usage/ [3] https://teamtreehouse.com/community/keyitemgetterattrgetter [4] https://discuss.python.org/t/operator-attrgetter-itemgetter-for-setting/20544 [5] https://www.digitalocean.com/community/tutorials/how-to-use-args-and-kwargs-in-python-3 [6] https://stackoverflow.com/questions/61452346/python-attrgetter-that-handles-none-values-and-can-be-used-in-a-loop [7] https://www.kdnuggets.com/2023/02/python-function-arguments-definitive-guide.html [8] https://www.youtube.com/watch?v=on77DvsVgrI
methodcaller vs defining a lambda for it
``Example 7-15. Demo of methodcaller: second test shows the binding of extra’’
usecases:
it allows us to partially freeze some args to an existing function
e.g.
hyphenate = methodcaller('replace', ' ', '-')
methodcaller is likely better than using a lambda because it’s more like a pointer to a callable function, with args as opposed to a new lambda being defined in each execution in the case of using lambdas
references: SO post and the perplexity dump below
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73The `operator.methodcaller` function in Python provides a way to create a callable that invokes a method on an object, using the method's name specified as a string. This can be particularly useful in scenarios where you need to call the same method repeatedly on different objects or when working with higher-order functions like `map` or `filter`. ### Value Proposition of Using `operator.methodcaller` 1. **Readability**: Using `methodcaller` can improve readability by clearly indicating that you are calling a method, especially when the method name is dynamic or when you are applying it across multiple items. 2. **Performance**: `methodcaller` can be more efficient than using a lambda function because it avoids the overhead of creating a new function object for each call. Instead, it creates a single callable that can be reused. 3. **Simplicity**: It simplifies code when you need to apply the same method call to multiple objects, making your intentions clearer without having to define multiple lambda functions. 4. **Consistency**: It provides a consistent interface for calling methods, especially when dealing with collections of objects where the method names might be determined at runtime. ### Example Usage of `operator.methodcaller` Here's how you can use `operator.methodcaller` in practice: #### Example 1: Basic Usage ```python from operator import methodcaller # Define a list of strings strings = ["hello", "world", "python"] # Use methodcaller to call the upper() method on each string upper_case_strings = list(map(methodcaller('upper'), strings)) print(upper_case_strings) # Output: ['HELLO', 'WORLD', 'PYTHON'] ``` In this example, `methodcaller('upper')` creates a callable that converts strings to uppercase. The `map` function applies this callable to each string in the list. #### Example 2: Calling Methods with Arguments You can also use `methodcaller` to call methods that require arguments: ```python from operator import methodcaller # Define a list of strings strings = ["hello", "world", "python"] # Use methodcaller to call the rjust() method on each string right_justified_strings = list(map(methodcaller('rjust', 10, '.'), strings)) print(right_justified_strings) # Output: ['.....hello', '.....world', '....python'] ``` In this case, `methodcaller('rjust', 10, '.')` creates a callable that right-justifies each string to a width of 10 characters, filling with dots. ### Comparison with Lambda Functions While you could achieve similar functionality using lambda functions, there are notable differences: - **Performance**: As mentioned earlier, using `methodcaller` can be faster than using a lambda because it avoids the overhead associated with creating new function objects for each call. - **Conciseness**: For simple method calls, `methodcaller` can make your code cleaner and more concise compared to writing out lambda expressions. - **Readability**: Using `methodcaller` explicitly indicates that you're invoking a method, which may enhance code clarity compared to lambda functions that might require additional context to understand what they do. ### Conclusion Using `operator.methodcaller` provides several advantages over defining lambdas for method calls, including improved readability, performance benefits, and simplicity. It is particularly useful in functional programming contexts where you need to apply methods across collections of objects efficiently and clearly. Citations: [1] https://stackoverflow.com/questions/2705104/lambda-vs-operator-attrgetterxxx-as-a-sort-key-function [2] https://florian-dahlitz.de/articles/introduction-to-pythons-operator-module [3] https://martinheinz.dev/blog/54 [4] https://treyhunner.com/2018/09/stop-writing-lambda-expressions/ [5] https://note.nkmk.me/en/python-operator-usage/ [6] https://realpython.com/python-operator-module/ [7] https://news.ycombinator.com/item?id=28104674 [8] https://discuss.python.org/t/operator-attrgetter-itemgetter-for-setting/20544
Freezing Arguments with functools.partial
it’s a partial application of another function, where we freeze some params
e.g.
nfc = functools.partial(unicodedata.normalize, 'NFC')Another is partial: given a callable, it produces a new callable with some of the arguments of the original callable bound to predetermined values. This is useful to adapt a function that takes one or more arguments to an API that requires a callback with fewer arguments.
Chapter Summary
main ideas are that you can assign functions to variables, pass them to other functions, store them in data structures, and access function attributes, allowing frameworks and tools to act on that information.
Python uses a statement-oriented syntax in which expressions cannot contain statements, and many language constructs are statements —including try/catch, which is what I miss most often when writing lambdas. This is the price to pay for Python’s highly readable syntax.
it’s a good thing that the “functional features” are limited in python because it helps make the language easier to use.
NOTE: python doesn’t do tail recursion optimisation (TCO)
reasons:
hard to do stack tracing, makes it harder to debug
not aligned with python’s idioms
- typically TCO necessary to avoid stack overflow, in languages that are fundamentally functional where deep recursion is idiomatic
hard to implement for the python interpreter.
current interpreter is supposed to :
- allow for dyanmic typing
- allow for introspection
it’s hard to implement the TCO stuff AND also follow these principles.
biggest obstacle to wider adop‐ tion of functional programming idioms in Python is the lack of tail-call elimination, an optimization that allows memory-efficient computation of a function that makes a recursive call at the “tail” of its body. In another blog post, “Tail Recursion Elimina‐ tion”, Guido gives several reasons why
here’s a more comprehensive perplexity output:
| |
Further Reading
Chapter 8. Type Hints in Functions
What’s New in This Chapter
About Gradual Typing
what it means by a gradual type system
“type hints are optional at all levels”
:NOTER_PAGE: (285 0.308300395256917 . 0.14267185473411154)
it has an interplay between duck typing and nominal typing
a type system that is optional
- by optional it means that we need to be able to silence it
- we can silence it at varying levels of abstraction
a type system that doesn’t catch type errors @ runtime
- only for static analysis
doesn’t enhance performance
Type hints are optional at all levels: you can have entire packages with no type hints, you can silence the type checker when you import one of those packages into a mod‐ ule where you use type hints, and you can add special comments to make the type checker ignore specific lines in your code.
Gradual Typing in Practice
- Starting with Mypy
- Making Mypy More Strict
GOTCHA: accidentally using
=instead of:for type hintsso this is legal but also a typo:
def hex2rgb(color=str) -> tuple[int,int,int]wherein we accidentally wrote
=instead of:.Just have to be careful for these things because the static analyser won’t point it out (since it’s legal).
Good Style:
- No space between the parameter name and the
:; one space after the: - Spaces on both sides of the
=that precedes a default parameter value
Use
blueinstead ofblackfor the static typechecking, it’s more aligned with python’s idioms.- No space between the parameter name and the
- A Default Parameter Value
EXTRA NOTE: python prefers single quotes by default for strings
``using single quotes’’
Using None as a Default \(\implies\) use
Optionalthe idea here is that
Nonecan be a better default value to use. So the type hinting should use anOptionalIt still needs a default value (of
None) because typehints are meaningless at runtime.BTW, it’s not the annotation that makes the param optional, it’s the provisioning of a default value for that param.
Types Are Defined by Supported Operations
what’s a “type”?
in a practical sense, see it as the set of supported operations
a supported operation here refers to whether the data object has the associated operator function defined or not.
So the example given is
abc.Sequenceand it does not have the__mul__implemented, so if the function is this then the type checker will complain1 2 3 4from collections import abc def double(x: abc.Sequence): return x * 2
Gradual Type System: an interplay b/w duck typing and nominal typing
``have the interplay of two different views of types:’’
- the key idea is, when do we want to detect typing errors: if @ runtime, then it’s more aligned with duck typing. if @ compile time, then it’s aligned with nominal typing.
duck typing (implicitly, structural typing):
focuses on “behaviour”, only enforced at runtime
objects are “typed” but variables aren’t
what really matters is what operations are supported \(\implies\) that’s why it’s duck typing.
“if it quacks like a duck” means if it has an implementation like that and the implementation supports the arguments provided
naturally this type checking is done at runtime
nominal typing:
- focuses on “type identity”
- “nominal” because it depends on the name, referring to the declaration that was made (like a label)
- compatibility of type depends on what the explicitly-defined type is
NOTE: a static checker may complain about type errors even if the code will actually work and execute without issues.
there’s a duality to be balanced here
This little experiment shows that duck typing is easier to get started and is more flexi‐ ble, but allows unsupported operations to cause errors at runtime. Nominal typing detects errors before runtime, but sometimes can reject code that actually runs—such as the call alert_bird(daffy)
Types Usable in Annotations
The Any Type
the purpose of defining an
anytypemore general types \(\implies\) narrower interfaces in the sense that they support fewer operations.
need for a special wildcard type: so you’d want to have something that can accept values of every type but not end up having a narrow interface \(\rightarrow\) that’s why we have
anyso,
Anyis a magic type that sits at the bottom and at the top of the type hierarchy (from the POV of the typechecker).
More general types have narrower interfaces, i.e., they support fewer operations. The object class implements fewer operations than abc.Sequence, which implements fewer operations than abc.MutableSequence, which implements fewer operations than list. But Any is a magic type that sits at the top and the bottom of the type hierarchy. It’s simultaneously the most general type—so that an argument n: Any accepts values of every type—and the most specialized type, supporting every possible operation. At least, that’s how the type checker understands Any
Contrasting
subtype-ofvsconsistent-withrelationsIn a gradual type-system there are elements of behavioural sub-typing (the classic one that adheres to LSP principle) as well as a more flexible compatibility notion in the form of consistent sub-typing.
subtype-of relationship: behavioural sub-typing adheres to LSP
LSP was actually defined in the context of supported operations:
If an object of T2 substitutes an object of type T1 and the program still behaves correctly, then T2 is a subtype-of T1.
T2 is expected. This focus on supported operations is reflected in the name behavioral subtyping,
consistent-with relationship: that’s what the
anyis forthis is the part where Any is consistence with both up and down the heirarchy.
Simple Types and Classes
- Can just directly use them for type-hinting.
- for classes,
consistent-withis defined likesubtype-of: a subclass is consistent with all its superclasses. - exception:
intis Consisten-With complex- all the numeric types are directly subclassed from
object. inthas a superset of functions but it’s not really a subclass ofcomplexbut it is still consistent-withcomplex!
- all the numeric types are directly subclassed from
Optional and Union Types
even the optional type is just syntax sugar for
Union[myType , None].the latest syntax allows us to use
A | Binstead ofUnion[A, B].NOTE: we can actually define return types that are Unions, but this makes it ugly because the caller of this function now needs to handle the type checking at runtime.
Union is more useful with types that are not consistent among themselves.
For example:
Union[int, float]is redundant becauseintis consistent-withfloat.If you just use
floatto annotate the parameter, it will acceptintvalues as well.
syntactic sugar for optional and union type:
|Better Syntax for Optional and Union in Python 3.10 We can write str | bytes instead of Union[str, bytes] since Python 3.10. It’s less typing, and there’s no need to import Optional or Union from typing. Contrast the old and new syntax for the type hint of the plural parameter of show_count: plural: Optional[str] = None plural: str | None = None
The | operator also works with isinstance and issubclass to build the second argument: isinstance(x, int | str). For more, see PEP 604—Complementary syntax for Union[].
try not to define return values with union types
it means the responsibility of doing type checking on the return values is on the consumer of the function \(\rightarrow\) bad pattern
Generic Collections (defining types for collections like
list[str])python collections (container classes) are generally heterogeneous
Generic types can be declared with type parameters to specify the type of the items they can handle.
the simplest form of generic type hints is
container[item]where container is any container type; examples being:- list
- set
- abc.MutableSet
references:
- see the official docs on GenericAlias
Situations that python’s type annotations won’t be able to handle:
- unsupported 1 - can’t type check
array.arraytypecode for python v 3.10
unsupported 2 - when collection defined with typecode, overflow is not checked for
yet another reminder that these numerics in python are not fixed-width
constructor argument, which determines whether integers or floats are stored in the array. An even harder problem is how to type check integer ranges to prevent OverflowError at runtime when adding elements to arrays. For example, an array with typecode=‘B’ can only hold int values from 0 to 255. Cur‐ rently, Python’s static type system is not up to this challenge.
- unsupported 1 - can’t type check
Tuple Types
There are 3 ways we can annotate tuple types:
annotating them as records
annotating them as records with named fields
annotating them as immutable sequences
tuples as records
Just use the builtin like e.g.
def geohash(lat_lon: tuple[float,float]) -> str:
for tuples being used as records with named fields \(\implies\) using
NamedTuplecan “alias” it using a named tuple – follows the
consistent-withrelationship1 2 3 4 5 6 7 8 9 10 11from typing import NamedTuple from geolib import geohash as gh PRECISION = 9 class Coordinate(NamedTuple): lat: float lon: float # NOTE this wrapper prevents static checkers from complaining that the geohash lib does not have typehints. def geohash(lat_lon:Coordinate) -> str: return gh.encode(*lat_lon, PRECISION)So here,
Coordinateis consistent-withtuple[float,float]because of this consistency, if a fn signature was
def display(lat_lon: tuple[float, float]) -> str:, then Coordinate NamedTuple will still work
1None
for tuples to be used as immutable sequences
Objective here is to annotate tuples of unspecified length that are used as immutable lists
We specify a single type, followed by a comma and
...This ellipsis is useful to us.
e.g.
tuple[int, ...]is a tuple withintitems.- note: we can’t tie down a particular length though
Here’s a consolidated example:
1 2 3 4 5 6 7 8 9 10 11 12from collections.abc import Sequence def columnize( # 1: this is a sequence of strings sequence: Sequence[str], num_columns: int = 0 # 2: return type below means it's a list of tuples and the tuples only contain strings. ) -> list[tuple[str, ...]]: if num_columns == 0: num_columns = round(len(sequence) ** 0.5) num_rows, reminder = divmod(len(sequence), num_columns) num_rows += bool(reminder) return [tuple(sequence[i::num_rows]) for i in range(num_rows)]
Generic Mappings
- the syntax is just
MappingType[KeyType, ValueType] - we can annotate local variables!
e.g.
index: dict[str, set[str]] = {}
interesting example of an inverted index
``returning an inverted index’’
There’s a whole bunch of literature on inverted indexes. This does a value -> key mapping.
good example code
In the example below:
the local variable of
indexis annotated because the typechecker will complain otherwisethe walrus operator
:=is used to define a name for an expression-outputTO_HABIT: this is useful and I already use it for while loops, but I can potentially use it for other expressions as well.
in the example for charidx.py:
1 2 3 4# we name the expression for the if-predicate so that we can use it thereafter if name := unicodedata.name(char, ''): for word in tokenize(name): index.setdefault(word, set()).add(char)More information about the walrus operator:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82The **walrus operator** (`:=`), introduced in Python 3.8, allows for assignment expressions, enabling you to assign a value to a variable as part of an expression. This feature can enhance code readability and efficiency in certain contexts. Here’s a detailed overview of its functionality, use cases, and implications. ### What is the Walrus Operator? - **Syntax**: The walrus operator is used as follows: ```python variable := expression ``` This assigns the result of `expression` to `variable` and returns that value. - **Purpose**: The primary purpose of the walrus operator is to allow assignments to be made within expressions, reducing redundancy and improving code conciseness. ### Key Use Cases 1. **Reducing Redundant Calculations**: - The walrus operator can be particularly useful when you want to use a value multiple times without recalculating it. ```python # Without walrus operator result = [func(x) for x in data if func(x)] # With walrus operator result = [y for x in data if (y := func(x))] ``` In this example, `func(x)` is called only once per iteration instead of twice. 2. **Cleaner Loop Constructs**: - It simplifies loops where the loop condition depends on user input or other calculations. ```python # Using walrus operator while (data := input("Enter your data: ")) != "": print("You entered:", data) ``` This eliminates the need for an initial assignment before entering the loop. 3. **Conditional Assignments**: - You can assign a value within an if statement, making the code more readable. ```python if (match := re.match(pattern, s)): print("Match found:", match.group()) ``` 4. **Accumulate Data In-Place**: - The walrus operator can also be used to accumulate values while iterating. ```python c = 0 print([(c := c + x) for x in [5, 4, 3, 2]]) # Output: [5, 9, 12, 14] ``` ### Advantages - **Conciseness**: It reduces boilerplate code by allowing assignments within expressions. - **Performance**: It can improve performance by avoiding repeated function calls or calculations. - **Readability**: In certain contexts, it makes the code clearer by showing intent directly where values are being assigned and used. ### Considerations - **Readability vs. Complexity**: While it can enhance readability, excessive or inappropriate use may lead to complex and hard-to-read code. It's important to balance conciseness with clarity. - **Avoiding Nested Expressions**: Using nested walrus operators can make code difficult to understand and maintain. ### Etymology of "Walrus" The term "walrus operator" is informal and comes from the resemblance of the `:=` symbol to a walrus's eyes and tusks. The playful name was popularized in discussions about its introduction and has since become widely accepted in the Python community. ### Mental Model To conceptualize the walrus operator: - Think of it as a way to "capture" a value while simultaneously using it in an expression. - Visualize it as a tool that allows you to hold onto something (the value) while you continue working with it immediately (the expression). ### Summary The walrus operator (`:=`) in Python provides a powerful way to assign values within expressions, enhancing code conciseness and performance in specific scenarios. While it offers significant advantages, careful consideration should be given to its use to maintain code clarity and avoid unnecessary complexity. Citations: [1] https://www.geeksforgeeks.org/walrus-operator-in-python-3-8/ [2] https://martinheinz.dev/blog/79 [3] https://www.kdnuggets.com/how-not-to-use-pythons-walrus-operator [4] https://realpython.com/python-walrus-operator/ [5] https://www.reddit.com/r/Python/comments/jmnant/walrus_operator_good_or_bad/ [6] https://stackoverflow.com/questions/73644898/why-is-python-walrus-operator-needed-instead-of-just-using-the-normal-assig [7] https://realpython.com/python-operator-module/ [8] https://www.digitalocean.com/community/tutorials/how-to-use-args-and-kwargs-in-python-3the tokenize function is a generator. KIV for chapter 17 for a deep dive into this.
Example 8-14. charindex.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26import re import unicodedata from collections.abc import Iterator RE_WORD = re.compile(r"\w+") STOP_CODE = sys.maxunicode + 1 def tokenize(text: str) -> Iterator[str]: """ return iterable of uppercased words """ for match in RE_WORD.finditer(text): yield match.group().upper() def name_index(start: int = 32, end: int = STOP_CODE) -> dict[str, set[str]]: index: dict[str, set[str]] = {} for char in (chr(i) for i in range(start, end)): if name := unicodedata.name(char, ""): for word in tokenize(name): index.setdefault(word, set()).add(char) return index
- the syntax is just
Abstract Base Classes
PRINCIPLE: Robustness Principle / Postel’s Law:
“Be conservative in what you send, be liberal in what you accept.”
it makes sense to define a generic type hint (of abstract classes) so that we can support many concrete implementations of it.
rule of thumb - better to use abc.Mapping or abc.MutableMapping instead of dict
Because it will support more mapping types
Therefore, in general it’s better to use abc.Mapping or abc.MutableMapping in parameter type hints, instead of dict (or typing.Dict in legacy code).
fall of the “numeric tower” of numeric class-hierarchy
there used to be a bunch of ABCs for numeric types, but now it’s not useful because numeric types are special.
they are directly subclassed from
Objecttype and areconsistent-witheach other.this numeric tower is a linear hierarchy of ABCs with Number at the top
- Number
- Complex
- Real
- Rational
- Integral
Point being that the static type checking of things within the numeric tower doesn’t work well – have to use the explicit types, KIV the solution for it, comes in a later chapter
Those ABCs work perfectly well for runtime type checking, but they are not sup‐ ported for static type checking. The “Numeric Tower” section of PEP 484 rejects the numbers ABCs and dictates that the built-in types complex, float, and int should be treated as special cases, as explained in “int Is Consistent-With complex” on page
3 options to type-annotate numeric things
use a concrete type instead e.g. int, float, complex
declare a union type
Union[float, Decimal, Fraction]Use numeric protocols e.g.
SupportsFloatkiv numeric protocols for chapter 13
In practice, if you want to annotate numeric arguments for static type checking, you have a few options:
- Use one of the concrete types int, float, or complex—as recommended by PEP
>
> 3. Declare a union type like Union[float, Decimal, Fraction].
> 4. If you want to avoid hardcoding concrete types, use numeric protocols like Sup
>
> portsFloat, covered in “Runtime Checkable Static Protocols” on page 468.
> The upcoming section “Static Protocols” on page 286 is a prerequisite for understand‐
> ing the numeric protocols.
> Meanwhile, let’s get to one of the most useful ABCs for type hints: Iterable.
Generic Iterables
Python Typeshed Project
Not that important.
Just for compatibility initially.
It is a way to provide “headers” with type annotations.
This is how the type annotations are retrofit in existing stdlibs because the stdlib fucntions have no annotations.
It relies on a .pyi file that’s basically like a c-header file.
:NOTER_PAGE: (310 0.6666666666666667 . 0.2703549060542797)
``Stub Files and the Typeshed Project’’
Explicit Type Aliases are supported, they improve readability
Though it seems that there’s a separate syntax for this.
FromTo: TypeAlias = tuple[str, str]1 2from typing import TypeAlias FromTo: TypeAlias = tuple[str, str]
⚠️ Danger of unbounded iterables on memory requirements
GOTCHA: iterable arguments need to be completely consumed. This poses a risk if we have infinite iterables (e.g. cyclic generators).
this is something to keep in mind about.
however, the value of this is that it allows flexibility and the ability to inject in generators instead of prebuilt sequences
return a result. Given an endless iterable such as the itertools.cycle generator as input, these functions would consume all memory and crash the Python process. Despite this potential danger, it is fairly common in modern Python to offer functions that accept an Iterable input even if they must process it completely to return a result.
Parameterized Generics and TypeVar
- for us to refer to a generic type, we have to use TypeVars
- KIV the fact that TypeVar also allows us to define covariants and contravariants in addition to bounds.
type var bound @ point of usage, is a reflection on the result type
where T is a type vari‐ able that will be bound to a specific type with each usage. This allows a parameter type to be reflected on the result type.
why TypeVar is needed (and unique to python)
TypeVar is a construct that is unique to the python language
introduces the variable name in the current namespace as opposed to getting that variable declared beforehand
it’s unique because languages like C, Java, Typescript don’t needt he name of type variables to be declared beforehand, so they don’t need such a construct
mental model: it’s a variable representing a type instead of being a type by itself
see more on typevar:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65The concept of **TypeVar** in Python is a unique construct primarily used for creating generic types, allowing developers to write functions and classes that can operate on any data type while maintaining type safety. This feature is particularly useful in statically typed languages, but it has specific implications and uses in Python, which is dynamically typed. Here’s a breakdown of why TypeVar is significant in Python and how it differs from similar concepts in languages like JavaScript. ### Understanding TypeVar in Python 1. **Generic Programming**: - **TypeVar** allows you to define a placeholder for a type that can be specified later when the function or class is instantiated. This enables generic programming, where you can write code that works with any data type. - Example: ```python from typing import TypeVar, Generic T = TypeVar('T') class Wrapper(Generic[T]): def __init__(self, value: T): self.value = value int_wrapper = Wrapper(10) # T is inferred as int str_wrapper = Wrapper("Hello") # T is inferred as str ``` 2. **Type Safety**: - TypeVar enhances type safety by ensuring that the operations performed on the generic type are valid for the specific type passed during instantiation. This helps catch errors at development time rather than runtime. 3. **Flexibility**: - It allows for more flexible and reusable code. You can create functions and classes that can handle multiple types without duplicating code for each specific type. ### Comparison with JavaScript JavaScript does not have a direct equivalent to Python's TypeVar due to its dynamic typing system. Here are some key differences: 1. **Dynamic vs. Static Typing**: - JavaScript is dynamically typed, meaning types are determined at runtime and variables can hold values of any type without explicit declarations. - In contrast, Python’s TypeVar allows for static type checking when using tools like `mypy`, enabling developers to specify expected types while still maintaining flexibility. 2. **Lack of Generics**: - While JavaScript supports some level of generics through its type systems (like TypeScript), it does not have built-in constructs like TypeVar that are part of the core language syntax. - In TypeScript (a superset of JavaScript), generics are defined differently, using angle brackets (`<T>`), but they do not use a construct like `TypeVar` to define a variable type that can be reused across multiple functions or classes. 3. **Type Inference**: - Python's TypeVar allows for type inference based on context, which can help with readability and maintainability of code. JavaScript's dynamic nature means that developers often rely on documentation or comments to convey expected types. ### Etymology of "TypeVar" and Mental Model The term **TypeVar** combines "Type" (referring to data types) and "Var" (short for variable). This naming emphasizes that it acts as a variable representing a type rather than being a concrete type itself. #### Mental Model: - Think of **TypeVar** as a placeholder or a template for a data type: - Imagine it as an empty box labeled "T" where you can put different items (data types) later. When you define a function or class using TypeVar, you’re saying, “This box can hold anything; just tell me what it will hold when you use it.” - This concept aligns with generic programming principles found in other languages but is uniquely adapted to Python's dynamic typing environment. ### Summary - **TypeVar** is a powerful construct in Python that enables generic programming by allowing developers to create flexible and reusable code while maintaining type safety. - Unlike JavaScript, which lacks direct support for generics in its core syntax, Python provides TypeVar as part of its typing module, facilitating static type checking. - The term "TypeVar" reflects its role as a variable representing types, allowing developers to think in terms of templates or placeholders when designing their functions and classes. Citations: [1] https://stackoverflow.com/questions/55345608/instantiate-a-type-that-is-a-typevar [2] https://discuss.python.org/t/non-uniqueness-of-typevar-on-python-versions-3-12-causes-resolution-issues/37350 [3] https://guicommits.com/python-generic-type-function-class/ [4] https://typing.readthedocs.io/en/latest/spec/generics.html [5] https://www.reddit.com/r/learnpython/comments/1adbgfp/should_i_use_a_typevar/ [6] https://dagster.io/blog/python-type-hinting [7] https://docs.python.org/es/3.13/library/typing.html [8] https://www.typescriptlang.org/play/typescript/language-extensions/nominal-typing.ts.html
make the [] operator work on classes like Sequence[T]. But the name of the T variable inside the brackets must be defined somewhere—otherwise the Python interpreter would need deep changes to support generic type notation as special use of []. That’s why the typing.TypeVar constructor is needed: to introduce the variable name in the cur‐ rent namespace. Languages such as Java, C#, and TypeScript don’t require the name of type variable to be declared beforehand,
Restricting/Bounding the TypeVar
there might be a need to explicitly restrict using a whilelist of types instead of letting the consistent-with subtyping do its job.
Without the restriction, anything that is consistent with T will work, but that’s unideal because the function that’s consuming the type most likely needs this to be restricted
we have 2 ways to restrict the possible types assigned to
T:
[1] restricted TypeVar – references a whitelist
This is a fixed whitelist.
Problem is that, it may not be easy to maintain if numerous items in the list.
that’s where bounding can be done.
``NumberT = TypeVar(‘NumberT’, float, Decimal, Fraction)’’
[2] bounded TypeVar – defines an upper bound on the type, works on anything that is consistent-with
sets an upper boundary for the acceptable types.
e.g.
HashableT = TypeVar('HashableT', bound=Hashable)then the variable could beHashableor any of its subtypescareful not to get confused with the use of the word “bound” for that named param to TypeVar. It’s just
this becomes the same generics construct as in Java
The solution is another optional parameter of TypeVar: the bound keyword parame‐ ter. It sets an upper boundary for the acceptable types. In Example 8-18, we have bound=Hashable, which means the type parameter may be Hashable or any subtype- of it.14
Predefined TypeVars
AnyStris an example of such a predefined type var, supports bothbytesandstr.
Static Protocols via
typing.ProtocolsA protocol in the historical sense is an informal interface. KIV proper introduction to Protocols till Chapter 13.
In the context of type hints,
A protocol is really all about structural typing. Types match if the behaviours are consistent-with each other.
This feature is also known as “static duck typing”. It’s because we make duck typing explicit for static type checkers.
the solution to annotate the series parameter of top was to say “The nominal type of series doesn’t matter, as long as it implements the
__lt__method.” Python’s duck typing always allowed us to say that implicitly, leaving static type checkers clueless. That’s the contrast with implicit duck typing that we have been seeing all alongprotocol definition vs implementation
protocol can be defined by subclassing
typing.Protocolit’s a class of its own,
here’s an example:
1 2 3 4 5from typing import Protocol, Any class SupportsLessThan(Protocol): def __lt__(self, other: Any) -> bool: ...and then we can use this protocol to define a TypeVar:
LT = TypeVar('LT', bound=SupportsLessThan)NOTE:
it subclasses
typing.Protocolclass body has one or more methods. the methods have
...in their bodies.this is sufficient to define the type signature for the protocol, and that’s what matters / is used to determine if something adheres to a protocol.
the implementer of a protocol doesn’t need to inherit, register or declare any relationship with the class that defines the protocol
a protocol type is defined by specifying one or more methods, and the type checker verifies that those methods are imple‐ mented where that protocol type is required. In Python, a protocol definition is written as a typing.Protocol subclass. However, classes that implement a protocol don’t need to inherit, register, or declare any rela‐ tionship with the class that defines the protocol. It’s up to the type checker to find the available protocol types and enforce their usage.
use case: when we can’t just define a boundary, but we want to define a protocol for the functions it supports
were able to use typing.Hashable as the upper bound for the type parameter. But now there is no suitable type in typing or abc to use, so we need to create it.
T just needs to be checked if it’s consistent-with the protocol
- disambiguation b/w protocols and abstract classes (as interfaces) in OOP (see perplexity thread)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80To clarify the concepts of **protocols** and **interfaces** in Python, and to compare them with Java's virtual interfaces, let's break down the definitions and functionalities. ### Disambiguation: Protocols vs. Interfaces in Python 1. **Protocols**: - **Definition**: A protocol in Python, introduced in PEP 484, defines a set of methods and properties that a class should implement, but it does not require explicit inheritance. Protocols allow for structural typing, meaning that if a class has the required methods and properties, it can be considered to implement the protocol. - **Usage**: Protocols are defined using the `typing.Protocol` class. They are useful for static type checking with tools like `mypy` and allow for "duck typing" — if an object behaves like a certain type, it can be used as that type regardless of its actual class. - **Example**: ```python from typing import Protocol class Drawable(Protocol): def draw(self) -> None: ... class Circle: def draw(self) -> None: print("Drawing a circle") def render(shape: Drawable) -> None: shape.draw() circle = Circle() render(circle) # This works because Circle has a draw method ``` 2. **Interfaces**: - **Definition**: In Python, interfaces are often implemented using abstract base classes (ABCs) defined in the `abc` module. An interface specifies a contract that classes must adhere to by explicitly declaring methods that must be implemented. - **Usage**: Interfaces require explicit inheritance from an ABC. This means that if a class claims to implement an interface, it must inherit from the ABC and implement all its abstract methods. - **Example**: ```python from abc import ABC, abstractmethod class Drawable(ABC): @abstractmethod def draw(self) -> None: pass class Circle(Drawable): def draw(self) -> None: print("Drawing a circle") def render(shape: Drawable) -> None: shape.draw() circle = Circle() render(circle) # This works because Circle implements Drawable ``` ### Comparison with Java's Virtual Interfaces - In Java, interfaces are explicitly defined contracts that classes must implement. A class can implement multiple interfaces, providing flexibility similar to Python's protocols. - Java's interfaces support default methods (methods with an implementation), which is not directly available in Python's protocols or ABCs without additional workarounds. - Both Java interfaces and Python protocols allow for polymorphism; however, Python's protocols enable duck typing without requiring explicit declarations of interface implementation. ### Summary of Differences | Feature | Protocols (Python) | Interfaces (Python via ABC) | Java Interfaces | |-----------------------|-------------------------------------|-------------------------------------------|---------------------------------------| | Definition | Structural typing | Explicit method contracts | Explicit method contracts | | Inheritance | No explicit inheritance required | Requires explicit inheritance | Requires explicit implementation | | Flexibility | More flexible (duck typing) | Less flexible (strict adherence needed) | Supports multiple interface implementation | | Default Methods | No default methods | No default methods | Supports default methods | | Use Case | Type checking with mypy | Enforcing method implementation | Defining contracts for behavior | ### Conclusion In summary, while both protocols and interfaces serve to define expected behaviors in Python, they do so in different ways. Protocols offer more flexibility through structural typing, while interfaces enforce strict adherence through inheritance. Understanding these distinctions helps in designing systems that leverage polymorphism effectively. If you have further questions or need more clarification on any specific points regarding protocols, interfaces, or their comparisons with other languages like Java, feel free to ask! Citations: [1] https://stackoverflow.com/questions/67233702/python-terminology-interface-vs-protocol [2] https://blog.glyph.im/2021/03/interfaces-and-protocols.html [3] https://sinavski.com/post/1_abc_vs_protocols/ [4] https://testdriven.io/tips/9f452585-e673-4617-8f35-ac85ab413e14/ [5] https://www.reddit.com/r/Python/comments/10ikape/interfaces_with_protocols_why_not_ditch_abc_for/ [6] https://news.ycombinator.com/item?id=26488156 [7] https://andrewbrookins.com/technology/building-implicit-interfaces-in-python-with-protocol-classes/ [8] https://discuss.python.org/t/add-built-in-flatmap-function-to-functools/21137
protocol has one or more method definitions, with … in their bodies. A type T is consistent-with a protocol P if T implements all the methods defined in P, with matching type signatures.
- disambiguation b/w protocols and abstract classes (as interfaces) in OOP (see perplexity thread)
example
the examples below use MyPy’s debugging facilities, take note.
typing.TYPE_CHECKcan be used to guard against runtime function calls- things like
reveal_type()is a Mypy debugging facility, not a regural function.
typing.TYPE_CHECKING constant is always False at runtime, but type check‐ ers pretend it is True when they are type checking.
- things like
reveal_type() is a pseudofunction, a mypy debugging facility
``reveal_type() pseudofunction call, showing the inferred type of the argument.’’
Callables via
typing.Callableallows us to hint the type of Higher Order Functions that are taking in callables
parameterized like so:
Callable[[ParamType1, ParamType2], ReturnType]The params list can have zero or more types.
if we need a type hint to match a function with a flexible signature, replace the whole parameter list with a
...Callable[..., ReturnType]other than that, there’s NO syntax to annotate optional or kwargs
Variance in Callable Types
With generic type params, we now have to deal with type hierarchies and so we have to deal with type variance.
KIV variance on Chapter 15
covariance
example:
Callable[[], int]is a subtype-ofCallable[[], float]because int is a subtype of float\(\implies\)
Callableis covariant on the return type because the subtype-of relationships of the typesintandfloatis in the same direction as the relationship of theCallabletypes that use them as return typesmost parameterized generic types are invariant
NoReturn via
typing.NoReturnfor functions that never return
actually used for no returns like exception throws in the case of
sys.exit()that raisesSystemExitextra: typeshed-like stub files don’t define default values, so they use
...instead``Stub files don’t spell out the default values, they use … instead.''
:NOTER_PAGE: file:///Users/rtshkmr/org/future_vyapari/books/Luciano Ramalho - Fluent Python_ Clear, Concise, and Effective Programming-O’Reilly Media (2022).pdf :ID: ./Luciano Ramalho - Fluent Python_ Clear, Concise, and Effective Programming-O’Reilly Media (2022).pdf-annot-325-10
extra: the use of ellipsis operator
...is context-dependent1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66The `...` operator in Python, known as the **ellipsis**, is a built-in singleton object of type `ellipsis`. Its role varies depending on context, and it’s often used where meaning can be ambiguous because Python itself does not mandate one specific use. Here are its main uses: 1. **Placeholder for Incomplete Code** You can use `...` inside functions, classes, or other blocks to indicate "code not yet implemented" or "to be done later," similar to `pass`. For example: ```python def my_function(): ... ``` This works as a no-op placeholder, and some developers prefer it stylistically over `pass`. 2. **Extended Slicing in Multi-Dimensional Arrays** In libraries like **NumPy**, `...` is very useful for slicing arrays with many dimensions. It stands for "expand all missing dimensions" in slice notation, allowing you to avoid explicitly typing many colons: ```python import numpy as np arr = np.arange(27).reshape(3, 3, 3) result = arr[..., 0] # Equivalent to arr[:, :, 0] ``` This slices all elements along all earlier dimensions and selects index 0 of the last dimension. 3. **Unique Default or Sentinel Value** Sometimes `...` is used as a unique sentinel or default parameter value to distinguish "no argument provided" from `None` or other possible values: ```python def greet(name, greeting=...): if greeting is ...: greeting = "Hello" print(f"{greeting}, {name}!") ``` 4. **Representation of Recursive or Circular References** When you print objects with circular references (e.g., a list containing itself), Python shows `[...]` in the output to avoid infinite recursion. This is a display convention, not an actual replacement of the object. 5. **Type Hinting Uses** The ellipsis appears in some advanced type hinting scenarios, for example, to indicate variable-length tuples (`Tuple[int, ...]`) or unspecified arguments in callables. ### Summary Table of Ellipsis Roles | Role | Description & Example | |------------------------------------|-----------------------------------------------| | Placeholder for unimplemented code | Use `...` inside functions/classes instead of `pass` | | Extended slicing in multidimensional arrays | `arr[..., 0]` to slice across many dimensions | | Unique default/sentinel value | Default function arguments different from None | | Circular reference representation | Shown as `[...]` in printed recursive data to avoid infinite loops | | Type hinting | Used in tuple or callable annotations to indicate variable length | In essence, `...` is a versatile built-in object intended to serve as a **syntactic convenience and semantic marker** that gains meaning from context, especially in libraries like NumPy and in type hinting. If you are seeing it "everywhere" ambiguously, it’s because its meaning tends to be **context-dependent**, and it’s often used as a compact placeholder or slicing shorthand. Let me know if you want detailed examples or specific usage in any particular context like NumPy, type hints, or function placeholders. --- References: 1. Scaler: Uses of Ellipsis in Python[1] 2. Real Python: When to Use Ellipsis[2] 3. Python Land: Python Ellipsis Explained[4] 4. Explaining Ellipsis in Function Defaults and NumPy Slicing[3] [1] https://www.scaler.com/topics/python-ellipsis/ [2] https://realpython.com/python-ellipsis/ [3] https://www.kdnuggets.com/exploring-pythons-ellipsis-more-than-just-syntax-sugar [4] https://python.land/python-ellipsis [5] https://stackoverflow.com/questions/772124/what-does-the-ellipsis-object-do [6] https://www.reddit.com/r/learnpython/comments/12pqfz5/til_about_ellipses_in_python/ [7] https://gist.github.com/promto-c/f51cc2c0eb8742ce5cc3e65601df2deb [8] https://www.geeksforgeeks.org/python/what-is-three-dots-or-ellipsis-in-python3/ [9] https://mbizsoftware.com/to-what-purpose-does-a-python-ellipsis-perform/
Annotating Positional Only and Variadic Parameters
Consider this example:
| |
So what we see here is that:
for the arbitrary positional params, it’s all fixed to
strfor the kwargs, it’s
**atrs: <mytype>where mytype would be the type of the value and the key will bestr
Imperfect Typing and Strong Testing
Some limitations to the type hinting capabilities:
unsupported: useful things like argument unpacking
handy features can’t be statically checked; for example, argument unpack‐ ing like config(**settings).
unsupported: advanced features like properties, descriptors, meta things
properties, descriptors, metaclasses, and metaprogram‐ ming in general are poorly supported or beyond comprehension for type checkers.
since can’t hint data constraints, type hinting doesn’t help with correctness of business logic
Common data constraints cannot be expressed in the type system—even simple ones. For example, type hints are unable to ensure “quantity must be an integer > 0” or “label must be a string with 6 to 12 ASCII letters.” In general, type hints are not help‐ ful to catch errors in business logic.
conclusion - robustness of python codes comes mainly from quality unit-testing
concluded: “If a Python program has adequate unit tests, it can be as robust as a C++, Java, or C# program with adequate unit tests (although the tests in Python will be faster to write).”
Chapter Summary
Protocol and how it enables static duck typing is useful because it’s very ‘pythonic’
in many ways, type hinting is very unPythonic, but
typing.Protocolfits nicely..protocols should be seen as the bridge between python’s duck-typed core and the nominal typing that allows static type checkers to catch bugs.
3.8, Protocol is not widely used yet—but it is hugely important. Protocol enables static duck typing: the essential bridge between Python’s duck-typed core and the nominal typing that allows static type checkers to catch bugs.
using the term “generics” in python is kinda funny
because it’s actually doing the opposite by tying-down exactly what the types can be instead of keeping it more “generic”
Generics or Specifics? From a Python perspective, the typing usage of the term “generic” is backward. Com‐ mon meanings of “generic” are “applicable to an entire class or group” or “without a brand name.” Consider list versus list[str]. The first is generic: it accepts any object. The sec‐ ond is specific: it only accepts str. The term makes sense in Java, though. Before Java 1.5, all Java collections (except the magic array) were “specific”: they could only hold Object references, so we had to cast the items that came out of a collection to
for a deeper dive into variance
we can do runtime type-checking in python
for advanced versions of runtime typechecking (i.e. anything beyond doing guards for
isinstance) we have to rely on some librariesSee this
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69Yes, you can perform runtime type checking in Python, and there are several ways to achieve this. Here’s a detailed overview based on the search results: ### Runtime Type Checking in Python 1. **Dynamic Typing**: Python is a dynamically typed language, meaning that types are determined at runtime. This allows for flexibility but can lead to type-related errors if not managed properly. 2. **Type Checking Tools**: - **`isinstance()`**: The built-in function `isinstance()` can be used to check if an object is an instance of a specific class or a tuple of classes. However, it does not support checking against complex type annotations defined in the `typing` module. ```python x = 5 if isinstance(x, int): print("x is an integer") ``` 3. **TypeGuard Library**: - Libraries like **TypeGuard** provide runtime type checking capabilities that can validate function arguments and return types based on type annotations. - You can use the `@typechecked` decorator to automatically check types at runtime. ```python from typeguard import typechecked @typechecked def add(a: int, b: int) -> int: return a + b add(1, 2) # Works fine add(1, "2") # Raises TypeError at runtime ``` 4. **Other Libraries**: - **`runtime-type-checker`**: This library allows you to perform type checks at runtime using decorators or direct function calls like `check_type()`. ```python from runtime_type_checker import check_type check_type("hello", str) # OK check_type(123, str) # Raises TypeError ``` 5. **Pydantic and Marshmallow**: These libraries are often used for data validation and serialization, providing runtime checks based on type annotations. - **Pydantic Example**: ```python from pydantic import BaseModel class User(BaseModel): name: str age: int user = User(name="Alice", age=30) # Valid user = User(name="Alice", age="30") # Raises validation error ``` ### Summary of Key Points - **Type Annotations**: While Python supports type hints (introduced in PEP 484), they are primarily for static analysis tools like `mypy`. By default, Python does not enforce these types at runtime. - **Runtime Type Checking Libraries**: To enforce type checks during execution, you can use libraries such as TypeGuard, runtime-type-checker, Pydantic, or Marshmallow. - **Flexibility vs. Safety**: The dynamic nature of Python provides flexibility but may lead to errors that can be caught with proper type checking mechanisms. ### Conclusion In summary, while Python does not enforce type hints at runtime by default, you can implement runtime type checking using various libraries designed for this purpose. These tools help ensure that your code adheres to the expected types defined in your annotations, providing an additional layer of safety in your applications. Citations: [1] https://stackoverflow.com/questions/43646823/python-3-5-checking-type-annotation-at-runtime [2] https://github.com/agronholm/typeguard [3] https://pypi.org/project/runtime-type-checker/ [4] https://testdriven.io/blog/python-type-checking/ [5] https://discuss.python.org/t/proposal-for-enhancing-runtime-type-checking-in-python-using-pattern-matching-and-type-hints-in-function-definitions/59391 [6] https://www.datacamp.com/tutorial/type-checking-in-python [7] https://www.infoworld.com/article/2268917/get-started-with-python-type-hints.html [8] https://realpython.com/python-type-checking/
``covers runtime type checking validation.''
Further Reading
:PROPERTIES: :NOTER_PAGE: (328 . 0.3852)
Chapter 9. Decorators and Closures
there’s a need to disambiguate the following:
“decorators” in the context of design patterns vs
“decorators” as a python source code syntax feature to do basic metaprogramming
“decorators” in the context of source code that alters the syntax tree when walking and annotating it
b and c are related
See elaboration here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104Absolutely—the term “decorator” is overloaded in the programming lexicon, and disambiguating its different meanings is essential, especially for a technical audience steeped in first-principles thinking. ## 1. **Decorator as an Object-Oriented Design Pattern** **Definition:** - The **Decorator Pattern** (from the Gang of Four design patterns) is a structural object-oriented pattern. - **Mental Model:** It’s about composing behaviors at runtime by “wrapping” objects so you can add, remove, or alter responsibilities dynamically, without modifying the original object’s code. - **Canonical Use:** You create a base interface, concrete components, and “decorator” classes implementing the same interface but containing an instance of the component (or another decorator). The decorator adds extra functionality before/after delegating calls to the wrapped object. **Example:** ```python class Coffee: def cost(self): return 5 class MilkDecorator: def __init__(self, coffee): self._coffee = coffee def cost(self): return self._coffee.cost() + 2 # adds cost of milk coffee = Coffee() milk_coffee = MilkDecorator(coffee) print(milk_coffee.cost()) # Output: 7 ``` **Key Points:** - The object’s interface remains constant. - You can layer (nest) decorators to compose features. - Pattern is about **runtime behavior extension** via object composition. ## 2. **Decorator as a Python Source Code Syntax Feature (Function/Method/Class Annotation)** **Definition:** - In Python, a *decorator* is language syntax (the `@decorator` notation) that allows alteration or augmentation of functions, methods, or classes. - **Mental Model:** This is a form of metaprogramming: you take a callable (“the decorated”) and replace it with the result of passing it to a decorator function (or class). The original entity is replaced—effectively rewiring its meaning at definition time. - This mechanism operates during **definition time**—when the source code is executed—and can be used for logging, access control, transformation, memoization, etc. **Example:** ```python def my_decorator(func): def wrapper(*args, **kwargs): print("Before") return func(*args, **kwargs) return wrapper @my_decorator def greet(): print("Hello") ``` - At load-time, `greet = my_decorator(greet)`. **Key Points:** - Not limited to adding or layering behavior: you can totally replace functionality, register, introspect, or annotate. - Strongly linked to Python’s first-class, runtime-accessible function objects. - Used pervasively in frameworks (Flask, Django, pytest, etc.). ## 3. **Decorator as an Abstract Syntax Tree (AST) Transformer** **Definition:** - In advanced metaprogramming scenarios, *decorator* can also refer to code that inspects and modifies the **AST itself**—that is, the parse tree Python generates before executing code. - **Mental Model:** These are meta-tools (not the `@decorator` feature) that programmatically traverse, annotate, or even rewrite code during, for example, static analysis, linting, or source-to-source transformation. - Examples include tools like `ast` module in Python’s standard library, or third-party packages for code analysis, type-checking, or metaclass generation. **Example (AST transformation):** ```python import ast class FunctionAnnotator(ast.NodeTransformer): def visit_FunctionDef(self, node): # Insert or rewrite a decorator in the AST node ... return node tree = ast.parse(open('somefile.py').read()) # Walk/transform the tree FunctionAnnotator().visit(tree) ``` **Key Points:** - This usage of “decorator” is about source-level transformations, not runtime behavior or object composition. - Such tools might annotate or rewrite code to reflect design-time properties or enforce invariants. - Operates at a different abstraction layer: **syntax tree instead of runtime objects**. ## **Disambiguating the Terms** - **Decorator Pattern (OOP):** Object composition to add functionality via wrappers, used in class/instance structures. “Decorator” is a *pattern* in the sense of design, independent of language syntax. - **Python Decorator Syntax:** Metaprogramming at definition time (`@decorator`), altering functions/methods through higher-order functions or callables. This is a *language feature* deeply integrated into Python’s runtime and loading mechanisms. - **AST/Syntax Tree Decorator/Transformer:** Tools that mutate or annotate the language’s syntax tree itself, often before code ever runs. This is a *meta-level code transformation* technique, not a runtime object operation. ## **Mental Model and Practical Takeaway** - Whenever we encounter the word “decorator,” first clarify: **Are we talking about a design pattern, a Python syntactic feature, or code transformation tools working with the syntax tree?** - For a **tech leader**, it’s crucial to recognize **the same term can encode different mental models**, and context defines which conceptual layer we’re operating in—object structure, runtime function composition, or compile-time/source-level transformation. > **In summary:** > - The term **“decorator”** in software can mean (1) a design pattern for dynamic behavioral extension, (2) the Python syntax feature for code transformation at definition time, or (3) a concept/tool for manipulating code at the syntax-tree level. These meanings are distinct in logic, purpose, and implementation, and using their precise terminology and mental models prevents architectural ambiguities in code review, design discussions, and tooling selection. **References:** 1. Gamma, Helm, Johnson, Vlissides. “Design Patterns: Elements of Reusable Object-Oriented Software.” 2. Python Language Reference, section on function definitions and decorators. 3. Python `ast` module documentation and real-world linter/analysis tools (e.g., Black, mypy internals).
closures are a foundational concept that help us reason about:
how to write decorators and use the
nonlocalkeywordprogramming that uses callbacks, or when writing python code in a functional fashion.
precursor learning objectives
• How Python evaluates decorator syntax • How Python decides whether a variable is local • Why closures exist and how they work • What problem is solved by nonlocal With this grounding, we can tackle further decorator topics: • Implementing a well-behaved decorator • Powerful decorators in the standard library: @cache, @lru_cache, and @single dispatch • Implementing a parameterized decorator
What’s New in This Chapter
Decorators 101
definition: “callable that takes another function as argument”
3 facts to summarise it:
- a decorator is a function or another callable
- a decorator may replace the decorated function with a different one
- decorators are executed IMMEDIATELY when a module is LOADED (@ load-time)
When you “decorate” a function in Python (either with the
@decoratorsyntax or by manual assignment), you are:Passing the original function object to a decorator callable (function or class).
Receiving back the return value of the decorator, which is typically—but not always—an inner function that wraps (or sometimes replaces) the original.
Binding a variable (often the same name as the original function) to this new object.
class decorators also exist!
When Python Executes Decorators - import-time vs run-time
- import-time vs runtime
import time would refer to when the module is loaded.
- within a script \(\rightarrow\) when the script starts
- within a different module \(\rightarrow\) when the importing is actually done
to emphasize that function decorators are executed as soon as the module is imported, but the decorated functions only run when they are explicitly invoked. This highlights the difference between what Pythonistas call import time and runtime.
Registration Decorators
typically decorators define an inner function that uses the decorated function and return that inner function.
this in a way, supports the GOF decorator pattern as well
Variable Scope Rules
this is a fundamental concept:
compare with JS, if we have a variable defined local to the scope of a function,
then in python, it will always assume that it’s a local variable and it won’t look further in the outer scopes to resolve that name.
in JS, the name resolution may go to higher scopes and we might potentially modify a global variable unknowingly
in python, refs to a locally defined name will never bubble out to a larger scope
But the fact is, when Python compiles the body of the function, it decides that b is a local variable because it is assigned within the function. The generated bytecode reflects this decision and will try to fetch b from the local scope. Later, when the call f2(3) is made, the body of f2 fetches and prints the value of the local variable a, but when trying to fetch the value of local variable b, it discovers that b is unbound.
so in this example, we have 3 scopes in action actually:
module global scope
the f3 function’s scope
the
nonlocalscopethough this part is not super obvious yet
1 2 3 4 5 6 7 8 9 10 11b = 6 def f3(a): global b print(a) print(b) b = 9 print(f3(3)) print(b)
the nature of the variable (local vs. global) can’t change in the body of a function
Closures
summary:
a closure is a function that retains the bindings of the free variables that exist when the function is defined, so that they can be used later when the function is invoked and the defining scope is no longer available.
the only situation in which a function may need to deal with external variables that are nonglobal is when it is nested in another function and those variables are part of the local scope of the outer function.
a closure is a function—let’s call it f—with an extended scope that encompasses variables referenced in the body of f that are not global variables or local variables of f.
Such variables must come from the local scope of an outer function that encompasses f.
It does not matter whether the function is anonymous or not; what matters is that it can access nonglobal variables that are defined outside of its body.
disambiguating closures from anon functions
Actually, a closure is a function—let’s call it f—with an extended scope that encom‐ passes variables referenced in the body of f that are not global variables or local vari‐ ables of f. Such variables must come from the local scope of an outer function that encompasses f. It does not matter whether the function is anonymous or not; what matters is that it can access nonglobal variables that are defined outside of its body.
- refer to this for the verbose disambiguation between closures and anon functions
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84To disambiguate **closures** and **anonymous functions** in programming languages, particularly in the context of Python, we need to clarify their definitions, characteristics, and how they relate to each other. ### Definitions 1. **Anonymous Functions**: - An **anonymous function** (often referred to as a **lambda function** in Python) is simply a function that does not have a name. It is defined using the `lambda` keyword and can be used wherever function objects are required. - Example in Python: ```python add = lambda x, y: x + y print(add(2, 3)) # Output: 5 ``` - Anonymous functions are useful for short, throwaway functions that are not reused elsewhere. 2. **Closures**: - A **closure** is a function that captures the lexical scope in which it was defined, allowing it to access variables from that scope even when it is executed outside of that scope. - In Python, closures are typically created when a nested function references variables from its enclosing scope. - Example in Python: ```python def outer_function(x): def inner_function(y): return x + y # 'x' is captured from the outer scope return inner_function closure = outer_function(10) print(closure(5)) # Output: 15 ``` - Here, `inner_function` forms a closure that captures the variable `x` from `outer_function`. ### Key Differences 1. **Nature**: - **Anonymous Function**: A function without a name; it can be defined and used inline. - **Closure**: A function that retains access to its lexical scope even when invoked outside of that scope. 2. **Creation**: - **Anonymous Function**: Can be created anywhere, typically for short-lived operations (e.g., as arguments to higher-order functions). - **Closure**: Created when a nested function references variables from its enclosing scope. 3. **Scope Access**: - **Anonymous Function**: Does not inherently capture any external state unless it is defined within another function. - **Closure**: Specifically designed to capture and retain access to its surrounding state. 4. **Use Cases**: - **Anonymous Functions**: Often used for callbacks or functional programming constructs (like `map`, `filter`, etc.). - **Closures**: Useful for data hiding and encapsulation, maintaining state across function calls. ### Python Context In Python, both anonymous functions and closures are supported: - **Anonymous Functions (Lambdas)**: ```python square = lambda x: x * x print(square(4)) # Output: 16 ``` - **Closures**: ```python def make_multiplier(factor): def multiplier(x): return x * factor # 'factor' is captured from the outer scope return multiplier double = make_multiplier(2) print(double(5)) # Output: 10 ``` ### Summary - All closures can be considered anonymous functions if they are defined without a name, but not all anonymous functions create closures. - The distinction lies in the ability of closures to capture and maintain access to their lexical environment, which anonymous functions do not inherently possess unless they are part of a nested structure. - In Python, this distinction allows for powerful programming patterns such as decorators and higher-order functions while maintaining clean and concise code. By understanding these concepts, developers can effectively utilize both anonymous functions and closures in their programming practices, leveraging their unique characteristics for various scenarios. Citations: [1] https://stackoverflow.com/questions/4912116/closure-vs-anonymous-function-difference [2] https://steemit.com/php/@hvonsteemit/the-power-of-anonymous-functions-closures-in-php [3] https://www.reddit.com/r/PHP/comments/4s1f9l/anonymous_functions_vs_closures_the_way_you_like/ [4] https://thoughtbot.com/blog/back-to-basics-anonymous-functions-and-closures [5] https://doc.rust-lang.org/book/ch13-01-closures.html [6] https://www.tutorialspoint.com/javascript-closures-vs-anonymous-functions [7] https://www.php.net/manual/en/functions.anonymous.php [8] https://realpython.com/python-type-hints-multiple-types/
- refer to this for the verbose disambiguation between closures and anon functions
free variables: variables that is not bound in the local scope
Consider this example:
1 2 3 4 5 6 7 8 9 10def make_averager(): series = [] def averager(new_value): # this assignment here makes series locally bound for the lifespan of this averager function series.append(new_value) total = sum(series) return total / len(series) return averagerso
avgis a reference to the inner function,averagerwhich has the outerseriesin its scope.within averager,
seriesWAS originally a local variable because of the assignment within its function bodyhowever after
make_averagerreturns, that local scope is gone.within
averager,seriesis a free variable, a variable that is NOT bound in the local scope.the closure for
averagerextends the scope of that function to include the binding for the free variable,seriesFigure 9-1. The closure for averager extends the scope of that function to include the binding for the free variable series. Inspecting the returned averager object shows how Python keeps the names of local and free variables in the code attribute that represents the compiled body of the function. Example 9-10 demonstrates. Example 9-10. Inspecting the function created by make_averager in Example 9-8 >>> avg._code_.co_varnames (’new_value’, ’total’) >>> avg._code_.co_freevars
how free variables are kept within
__closure__attributes:NOTER_PAGE: (344 0.5105177993527509 . 0.33121019108280253)
closures are actually represented using
cellitems / attrsavg.__closure__[0].cell_contentsalternatively, we could inspect the
__code__for that variable, just to observe this.avg.__code__.co_freevarswhich gives the free variables for that function
is kept in the closure attribute of the returned function avg. Each item in avg.__closure__ corresponds to a name in avg. code .co_freevars. These items are cells, and they have an attribute called cell_con tents where the actual value can be found.
only situation for why a function may require access to variables outside its scope
that the only situation in which a function may need to deal with external vari‐ ables that are nonglobal is when it is nested in another function and those variables are part of the local scope of the outer function.
The nonlocal Declaration
using
nonlocalkeyword to explicitly define free variableslets you declare a variable as a free variable even when it is assigned within the function. If a new value is assigned to a nonlocal variable, the binding stored in the closure is changed.
prevents the use-before-definition error because the variable will be regarded as a free-variable if it’s indicated as
nonlocal
To work around this, the nonlocal keyword was introduced in Python 3. It lets you declare a variable as a free variable even when it is assigned within the function. If a new value is assigned to a nonlocal variable, the binding stored in the closure is changed.
Variable Lookup Logic - how python resolves names
- Rules for defining how to fetch a variable
xthat appears in function:if we have a
global x, thenxcomes from and is assigned to thexglobal variable moduleNOTE: python doesn’t have a program global scope, only module global scopes
if we have a
nonlocal xdeclaration thenxcomes from and is assigned to thexlocal variable of the nearest surrounding function wherexis definedIf
xis a parameter / assigned a value in the function body, thenxis the local variableIf
xis referenced (read only), but not assigned (no modification) and is NOT a parameter:xis looked up the local scopes of the surrounding function bodies (non-local scopes) \(\rightarrow\) free variable!if nothing, then will be read from the module global scope
if still nothing, then read from
__builtins__.__dict__
:NOTER_PAGE: (346 . 0.496385)
Implementing a Simple Decorator
typical behavior of a decorator: it replaces the decorated function with a new function that accepts the same arguments and (usually) returns whatever the decorated function was supposed to return, while also doing some extra processing.
this is partly aligned with the GOF Decorator Pattern in OOP.
In both cases, we extend behaviour, but the way we do it is different.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31Your summary of a typical Python decorator—that it “replaces the decorated function with a new function that accepts the same arguments and (usually) returns whatever the decorated function was supposed to return, while also doing some extra processing”—captures how decorators are commonly used in Python. However, this pattern only partly aligns with the **Gang of Four (GOF) Decorator Pattern** as described in object-oriented design. ### GOF Decorator Pattern (Design Pattern) - The **GOF Decorator Pattern** is about **dynamically attaching new responsibilities to objects** at runtime by wrapping them in decorator objects[2][7]. - In the traditional pattern, decorators are classes that implement the same interface as the objects they wrap. Additional behavior is layered by composition, and you can recursively chain decorators together[2][3][5]. - The emphasis is on **object composition** and runtime extension, not on function replacement or metaprogramming. ### Python Decorators (Language Feature) - **Python decorators** (via the `@decorator` syntax) are a **language feature** for transforming functions or classes at definition time[1]. A Python decorator is usually a higher-order function or class that takes a function (or class) and returns a replacement—often a function that wraps the original, accepting the same parameters, returning the same output, and adding pre- or post-processing. - This approach is similar in spirit to the design pattern because it allows extension or modification of behavior without changing the original function directly[1]. The decorator often "wraps" the original so that calling the decorated function results in the new ("decorator") logic being executed, often around a call to the original. ### Key Distinctions - The **GOF pattern operates at the object/class level**, using composition and polymorphism. - The **Python feature generally operates at the function (or class) level**, using higher-order functions for metaprogramming and code transformation at definition time. - Both systems enable behavioral extension, and Python decorators can be used to implement the decorator pattern, but they're not always identical in mechanics or intention[1][5]. ### In summary: - Your description of the typical behavior matches how Python decorators are commonly implemented and used. - This overlap is **inspired by the GOF Decorator Pattern**; the intent—to extend or alter behavior without modifying the original—is present in both. - However, **Python's decorator syntax and idioms are a language feature enabling, but not limited to, the classical design pattern**. The mechanics and use cases often go beyond, including metadata registration, memoization, method validation, and many scenarios not contemplated by the original OOP design pattern[1][3][7]. So: **your summary matches common Python decorator behavior, which parallels the GOF Decorator Pattern but is not restricted to it—they share intent, but not all implementation details**[1][2][5]. [1] https://stackoverflow.com/questions/17927129/is-python-decorator-related-to-the-decorator-design-pattern [2] https://www.digitalocean.com/community/tutorials/gangs-of-four-gof-design-patterns [3] https://refactoring.guru/design-patterns/decorator [4] https://www.reddit.com/r/Python/comments/r0apia/which_of_the_design_patterns_of_the_og_gang_of/ [5] https://python-patterns.guide/gang-of-four/decorator-pattern/ [6] https://www.geeksforgeeks.org/system-design/decorator-pattern/ [7] https://en.wikipedia.org/wiki/Decorator_pattern [8] https://github.com/tuvo1106/python_design_patternsTIP: using
@functools.wraps()will allow the decoration to have the same docs and variadic kwargs and suchthis is an example of a standard, ready-to-use
decorator
``def clock(func): @functools.wraps(func) def clocked(*args, **kwargs):''
Decorators in the Standard Library
Memoization with
functools.cachestacking decorators composes them, starting from the bottom of the stack then applies outwards towards the top of the stack
1 2 3@alpha @beta def my_fn():which is equivalent to nested functions
my_fn = alpha(beta(my_fn))args to the decorated function needs to be hashable
this is because the internal representation for the
lru_cacheis actually adictand the keys are from the positional and kwargs used in the calls.arguments taken by the decorated function must be hashable, because the underlying lru_cache uses a dict to store the results, and the keys are made from the positional and keyword arguments used in the calls.
a good usecase for
@cacheis caching remote API calls!careful that we don’t end up using all the available memory ( may happen since this cache is unrestricted ). we can use
functools.lru_cache(maxsize=<mymaxsize>)instead
Using
@lru_cacheto keep the memory bounded- there’s a default of
128which is 128 entries in the cache - for optimal performance,
maxsizeparameter should be a power of 2 to make it optimal typedparameter, if true, discriminates argument type within its store, so1.0and1are treated as two different entries in the store.
- there’s a default of
Single Dispatch to Contribute to Generic Functions (aka Multimethods)
python doesn’t have method overloading (like in Java, for example)
in this example for
htmlize, with multiple rules, we can:- let
htmlizeact as a dispatcher that dispatches multiple specific functions e.g.htmlize_strand so on
- let
so,
functools.singledispatchdecorator:allows different modules to contribute to the overall solution, and lets you easily provide specialized functions even for types that belong to third-party packages that you can’t edit.
a generic function here is a group of functions to perform the same operation in different ways, depending on the type of the first argument
it’s
singledispatchbecause only the first argument is used as the determinant, else it would have been called “multiple dispatch”it’s going to use a custom
@<generic_fn_name>.registerto do the bundling of the specific functions
implementing it:
the function that we apply the
@singledispatchdecorator to will end up being the name of the generic function that we want to bundle functionality for. Also, the base case implementation (e.g. something that works with a genericObjecttype), will be found there.for the other specialised functions (contributors to the generic function) , we can use the custom
@<generic_fn>.registerto register themthe specialised function
only 1st argument matters
we can define them at varying levels of class-specificity
e.g.
boolis a subtype-ofnumbers.Integral, but the singledispatch logic seeks the implementation with the most specific matching type, regardless of the order they appear in the code.we can also stack other decorators atop the register decorator because the
@<base>.registerdecorator returns the undecorated function.
TIP: register specialised functions to handle ABCs or Protocols to enjoy more polymorphic behaviour
Using ABCs or typing.Protocol with @singledispatch allows your code to support existing or future classes that are actual or virtual subclasses of those ABCs, or that implement those protocols.
KIV virtual subclasses till chapter 13
remember that we can register functions that works with 3rd party libraries!
this analogous to function overloading in typed languages
here’s the functools docs for it
NOTE it’s NOT supposed to be a parallel to java method overloading, it’s to support MODULAR EXTENSION
- modular extension in the sense that each module can register a specialized function for each type it supports.
@singledispatch is not designed to bring Java-style method over‐ loading to Python. A single class with many overloaded variations of a method is better than a single function with a lengthy stretch of if/elif/elif/elif blocks. But both solutions are flawed because they concentrate too much responsibility in a single code unit—the class or the function. The advantage of @singledispatch is supporting modular extension: each module can register a speci‐ alized function for each type it supports. In a realistic use case, you would not have all the implementations of generic functions in the same module as in
Parameterized Decorators
Key Idea: use a decorator factory to create the decorator
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24registry = set() # this here is a decorator factory def register(active=True): def decorate(func): print('running register' f'(active={active})->decorate({func})') if active: registry.add(func) else: registry.discard(func) return func return decorate @register(active=False) def f1(): print('running f1()') @register() def f2(): print('running f2()') def f3(): print('running f3()')NOTE: we can’t just call
@nameanymore, we have to actually call that factory functionread more here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45It is correct to say that a **decorator factory** in Python must always be called using `@name()` (with parentheses), because it is a function that returns a decorator. The result of calling the factory—i.e., `name()`—must itself be a callable that accepts the function being decorated, and only this returned callable is applied as the actual decorator. - Using `@name` is for *simple decorators*: the decorator is itself a callable that takes a function as input (e.g., `def decorator(fn): ...`), and is applied as `@decorator`. - A **decorator factory** is a function returning a decorator, often parameterized (e.g., `def decorator_factory(arg): ...`). You must invoke the factory—`@decorator_factory(args)`—so that what is returned will accept and wrap the underlying function[2][3][5]. ### Does `@name` Ever Act as a Nullary Call? No, `@name` does **not** cause an implicit function call. The interpreter does *not* call `name()` for you. `@name` without parentheses applies exactly what’s bound to `name` as a decorator; it is not treated as `@name()`. This makes explicit invocation with parentheses (`@name()`) necessary if you intend to use a decorator factory, even with no arguments[2][3]. - If you accidentally use `@name` (no parentheses) when `name` is actually a decorator factory, you will get a `TypeError` because the decorator factory is not the correct type—it hasn’t yet received its arguments and it doesn’t accept the function to be decorated as its first input. ### Example: ```python def decorator_factory(arg): def decorator(fn): ... return fn return decorator @decorator_factory(42) # correct usage: applies the decorator returned from factory def foo(): ... ``` If you write `@decorator_factory` (no parentheses) above, `foo` is actually passed to `decorator_factory`, not to the decorator it returns, and the protocol is broken. ### Summary Table | Decorator Syntax | Used For | Calls Made Implicitly | |---------------------|-----------------------|------------------------| | `@name` | Simple decorator | No call (just binding) | | `@name()` | Decorator factory | Calls factory, supplies result as decorator | | `@name(arg1, arg2)` | Decorator factory | Calls factory with arguments | In conclusion: - **Decorator factories must be used as `@name()`** (or with arguments: `@name(arg, ...)`). - **`@name` does NOT act as a nullary call** and does not call the factory. - Using `@name` when only a decorator factory is defined will result in errors or unexpected behavior[2][3][5]. [1] https://stackoverflow.com/questions/44358027/why-is-using-decorator-factory-factory-functions-a-syntax-error [2] https://www.thepythoncodingstack.com/p/demystifying-decorators-parts-3-to-7 [3] https://blog.devgenius.io/decorator-factory-by-example-e3f2774b0baa [4] https://www.geeksforgeeks.org/python/decorators-in-python/ [5] https://realpython.com/primer-on-python-decorators/ [6] https://www.freecodecamp.org/news/the-python-decorator-handbook/ [7] http://simeonfranklin.com/blog/2012/jul/1/python-decorators-in-12-steps/
possible to call the decorator factory function directly too without the @
- though we would have to call it like so:
register(active=False)(f)
If, instead of using the @ syntax, we used register as a regular function, the syntax needed to decorate a function f would be register()(f) to add f to the registry, or register(active=False)(f) to not add it (or remove it).
- though we would have to call it like so:
The Parameterized Clock Decorator
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23import time DEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}' def clock(fmt=DEFAULT_FMT): def decorate(func): def clocked(*_args): t0 = time.perf_counter() _result = func(*_args) elapsed = time.perf_counter() - t0 name = func.__name__ args = ', '.join(repr(arg) for arg in _args) result = repr(_result) print(fmt.format(**locals())) # NB: see the locals passing like it's done here return _result return clocked return decorate if __name__ == '__main__': @clock() def snooze(seconds): time.sleep(seconds)- we can pass local variables to a fn like fmt like so:
print(fmt.format(**locals()))
- we can pass local variables to a fn like fmt like so:
A Class-Based Clock Decorator
- these examples just used functions as a demo example
- for non-trivial cases, better to think of decorators as classes with a
__call__()=
``implemented as a class with call''
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18import time DEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}' class clock: def __init__(self, fmt=DEFAULT_FMT): self.fmt = fmt def __call__(self, func): def clocked(*_args): t0 = time.perf_counter() _result = func(*_args) elapsed = time.perf_counter() - t0 name = func.__name__ args = ', '.join(repr(arg) for arg in _args) result = repr(_result) print(self.fmt.format(**locals())) return _result return clocked- the
clockclass here is our parameterized decorator factory
KIV class decorators for chapter 24.
Chapter Summary
Further Reading
- general series on python decorators, starting with “how you implemented your Python decorator is wrong”
dynamic vs lexical scoping
- lexical scope is the norm: free variables are evaluated considering the environment where the function is defined. Lexical scope complicates the implementation of languages with first-class functions, because it requires the support of closures. On the other hand, lexical scope makes source code easier to read.
``Dynamic Scope Versus Lexical Scope''
coming to terms b/w decorator pattern and python decorators
Note that I am not suggesting that function decorators should be used to implement the decorator pattern in Python programs. Although this can be done in specific sit‐ uations, in general the decorator pattern is best implemented with classes to represent the decorator and the components it will wrap.
Chapter 10. Design Patterns with First-Class Functions
design pattern: general recipe for solving common design problems
language independent; however practically some languages already have inbuilt recipes for some of these patterns
e.g. Generators in python are the inbuilt version of the Iterator pattern.
in the context of languages that support first-class functions, the fact that we can leverage functions as first-class objects is useful to make code simpler.
the following classic patterns might need a rethink because functions can do the same work as classes while improving readability and reducing boilerplate:
Strategy Pattern
Command Pattern
Template Method
Visitor Pattern
What’s New in This Chapter
Case Study: Refactoring Strategy
- the objective of this case study is to see how we can leverage functions as first-class objects.
Classic Strategy
- what it is:
- “Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it.”
- participants:
Context
- Provides a service by delegating some computation to interchangeable components that implement alternative algorithms.
- in the example, this is the
Order
Strategy
interface common to the components that implement the different algorithms.
it’s the
Promotionabstract class
Concrete Strategy
- one of the concrete classes that implement the abstract class
- what it is:
Function-Oriented Strategy
useful characteristics form the class-based implementation:
concrete strategies have a single useful method
strategy instances are stateless and hold no instance attributes
It’s because of these reasons, we can consider replacing the concrete strategies with simple functions, and removing the abstract class.
“strategy objects often make good flyweights” is the advice, wherein the cons of the Strategy pattern, which is its runtime cost (e.g. when instantiating the strategy) is addressed by using a Flyweight pattern.
now we end up getting more boilerplate
the python way of using first class functions works well in general because:
in most cases, concrete strategies don’t need to hold internal state because they deal with data injected by the context \(\implies\) good enough to use plain old functions.
a function is more lightweight than an instance of a user-defined class + we can just create each function once and use it.
Choosing the Best Strategy using MetaStrategy: Simple Approach
- Once you get used to the idea that functions are first-class objects, it naturally follows that building data structures holding functions often makes sense.
Finding Strategies in a Module
Modules are also first-class objects
globals()returns the current global symbol table. We can inspect attributes of the class object and get the function attributes defined within it like so:promos = [func for _, func in inspect.getmembers(promotions, inspect.isfunction)]I see this as a “pull method” almost where we try to pull together attributes that might make sense. Naturally a registration decorator approach makes more sense already so that we can do a “pull method” approach
Decorator-Enhanced Strategy Pattern
Here’s the example:
| |
Advantages of using this decorator:
promo strategy functions don’t need special names, flexibility in naming
the registration decorator also becomes a highlighting of the purpose of the function being decorated
- also makes it easy to just comment out the decorator
registration can be done from any other module, anywhere in the system as long as we use the same registering decorator
The Command Pattern
The goal of Command Pattern is to decouple an object that invokes an operation (the invoker) from the provider object that implements it (the receiver).
put a Command object between the two, implementing an interface with a single method,
execute, which calls some method in the receiver to perform the desired operation.Invoker doesn’t need to know the interface of the receiver
different receivers can be adapted through different
Commandsubclassesthe invoker is configed with a concrete command and calls its
executemethod to operate it.
some pointers from the example:
we have commands and command receivers.
Command receivers are the objects that implement the action specific to a command.
There can be multiple receivers that may respond to a command.
“Commands are an object-oriented repalcement for callbacks”. Nice. Depends on use-case but we could directly implement the callbacks if we want.
How to use simple callback functions directly?
Instead of giving the invoker a
Commandinstance, we can simply give it a function. Instead of callingcommand.execute(), the invoker can just callcommand(). TheMacroCommandcan be implemented with a class implementing__call__. Instances ofMacroCommandwould be callables, each holding a list of functions for future invocation.if we need more complex command usage (e.g. with undo) then we just need to keep necessary state, we could put it within classes like
MacroCommandand we can use a closure to hold the internal state of a function between calls.
Chapter Summary
the GOF book’s patterns should be seen as steps in the design process of a system rather than end-points or structures that have to be implemented.
this will allow us to not mindlessly add in boilerplate or structures that actually would have better ways of getting implemented if we had thought about the language’s idioms
- In python’s case, functions or callable objects provide a more natural way of implementing callbacks in Python than mimicking the Strategy or the Command patterns
Further Reading
not many options available for python and design patterns in pythonic fashion, there’s a list here in this book
funfact: If functions have a
__call__method, and methods are also callable, do__call__methods also have a__call__method?YES!!!
Part III. Classes and Protocols
Chapter 11. A Pythonic Object
Learning Objectives:
- builtins that convert objects to other types
- alternative constructors
- extending the formatting mini language
What’s New in This Chapter
Object Representations
- python has the following ways to get common string representations. everything except for bytes should return Unicode strings:
repr(), depends on__repr__: developer’s POVstr()depends on__str__: user’s POVbytes()depends on__bytes__for byte sequenceformat()depends on__format__: for f-stringsstr.format()method also relies on this.
Vector Class Redux
this example is really useful
some notes from the example:
__iter__is what makes the object iterable, so that we can do things like:- unpacking and so on
we can implement this by using a generator expression to yield the components one after the other
kiv the implentation of
__eq__and operator overloading until then
An Alternative Constructor
@classmethodallows a method to be called on a class.Naturally, this ISN’T a static method. Here’s an outline of the diffs. The next section is about this actually.1 2 3 4 5 6@classmethod def frombytes(cls, octets): typecode = chr(octets[0]) memv = memoryview(octets[1:]).cast(typecode) return cls(*memv)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47Yes, class methods and static methods are different in Python; they serve distinct purposes and have different access to class and instance data. - **Class methods** are defined using the `@classmethod` decorator. Their first parameter is `cls`, which refers to the class itself (not an instance). Class methods can access and modify class-level attributes and are often used for factory methods or operations that affect the class as a whole. They cannot directly access or modify instance-specific data[1][2][5][6][8]. - **Static methods** are defined using the `@staticmethod` decorator. They do not take `self` or `cls` as their first argument and have no automatic access to either instance or class state. Static methods are utility functions, included in a class for organizational purposes, but they behave like plain functions that happen to live in a class’s namespace. They cannot access or modify class or instance data[1][2][4][5][6][8]. ### Key Differences | Aspect | Class Method | Static Method | |----------------------------|-------------------------------|------------------------------------| | Decorator | `@classmethod` | `@staticmethod` | | First parameter | `cls` (the class) | None required | | Accesses class data? | Yes, via `cls` | No | | Accesses instance data? | No | No | | Use case | Factory methods, class state | Utility functions | | Can modify class state? | Yes | No | | Can modify instance state? | No | No | #### Example Usage ```python class Example: count = 0 @classmethod def increment_count(cls): cls.count += 1 @staticmethod def add(x, y): return x + y ``` - `increment_count()` can change `Example.count`. - `add(2, 3)` simply returns the sum and does not access or change any class or instance data[2][5][6][8]. In summary: **Class methods operate on the class and its state; static methods are independent and do not touch class or instance data.** [1] https://realpython.com/instance-class-and-static-methods-demystified/ [2] https://www.geeksforgeeks.org/python/class-method-vs-static-method-python/ [3] https://stackoverflow.com/questions/136097/what-is-the-difference-between-staticmethod-and-classmethod-in-python [4] https://www.python-engineer.com/posts/difference-classmethod-and-staticmethod/ [5] https://www.linkedin.com/pulse/exploring-differences-between-class-methods-static-python [6] https://accuweb.cloud/resource/articles/class-vs-static-method-in-python [7] https://www.boardinfinity.com/blog/class-and-static-method-in-python-differences/ [8] https://flexiple.com/python/class-method-vs-static-method [9] https://www.youtube.com/watch?v=PIKiHq1O9HQ
@classmethod Versus @staticmethod
classmethod: to define a method that operates on the class and not on instances. classmethod changes the way the method is called, so it receives the class itself as the first argument, instead of an instance.a good use case is for alternative constructors like we see here in
frombytes, or for operations that work at the class-levelNOTE: having learnt java in school, this seems to directly map to the use of static functions in java.
HOWEVER
@classmethodin Python is not the same as Java static methods. In Python, classmethods are more powerful: they get the class as an argument, so they are aware of inheritance (subclasses), and can instantiate correct subclasses—something Java static methods cannot directly do, since they are not polymorphic in the same way and are resolved at compile-timestaticmethod: this changes a method so that it receives no special first argument. In essence, a static method is just like a plain function that happens to live in a class body, instead of being defined at the module level.this just has no access to the class or instance data.
seems like there aren’t many good usecases for this.
Formatted Displays
the different invokers delegate the formatting logic to the dunder method
__format__(<format_spec>)two ways to get the formatting specifier:
the second arg in
format(my_obj, format_spec)within replacement fields (which are
{}) that delimit the specifier within an f-string or thefmtinfmt.str.format().e.g.
'1 BRL = {rate:0.2f} USD'.format(rate=brl)in this example, the
rateis not part of the specifier, it’s the kwarg for the replacement field. The actual specifier is just'0.2f'we could also directly reference this:
f'1 USD = {1 / brl:0.2f} BRL'(notice the use of the )
Replacement fields:
A format string that looks like
'{0.mass:5.3e}'has 2 separate notations:field name:
0.massto the left is thefield_namefor the replacement syntax.it can be an arbitrary expression in an f-string.
formatting specifier:
5.3eafter the colon is the formatting specifierthis is just the formatspec mini language (ref)
FormatSpec Structure
fstringsvsstr.format()the
fstringsallows in place replacementthe others separate it and make it more of an interpolation. This is great when we wanna separate it.
let me do a bot dump for this.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61The **format specifier** (or `format_spec`) is a mini-language used inside replacement fields of Python format strings (e.g., in `'{0.mass:5.3e}'`) to control how the formatted value is presented. ### Breakdown of the Notation: - **Field name:** The part before the colon (`:`), like `0.mass` in your example, specifies what value to format. It can be a positional argument (`0`), an attribute access (`mass`), or an arbitrary expression in f-strings. - **Format specifier:** The part after the colon (`5.3e` in your example) is the **format spec mini-language** that instructs Python how to render the value. This includes alignment, width, precision, type (e.g., scientific notation), padding, and more. ### About the Format Spec Mini-Language The format spec language is defined in Python’s string formatting documentation and includes syntax like: ``` [[fill]align][sign][#][0][width][,][.precision][type] ``` Where: - **fill**: Any character used to fill the padding space. - **align**: `` (right), `=` (pad after sign), `^` (center). - **sign**: `+`, `-`, or space for numeric sign display. - **#**: Alternate form (e.g., include `0x` for hex). - **0**: Enables zero-padding. - **width**: Minimum field width as a number. - **,**: Enables thousands separator. - **.precision**: Number of decimal places (or significant digits). - **type**: Type of conversion, such as: - `e` or `E` for scientific notation, - `f` or `F` for fixed-point, - `g` or `G` for general format, - `d` for decimal integer, - `s` for string, etc. Your example `{0.mass:5.3e}` formats the value `mass` of the first argument in scientific notation (`e`), with a total width of 5 characters and 3 digits after the decimal point. ### Practical Use - Format specs can control numeric formatting (precision, notation). - They can align text inside fixed-width fields. - Support thousand separators and padding. - Allow highly readable and localized string outputs. ### References and Deep Dive - Official Python docs on [Format Specification Mini-Language](https://docs.python.org/3/library/string.html#formatspec) - Real Python tutorial on [Python’s Format Mini-Language](https://realpython.com/python-format-mini-language/) - Examples for format spec syntax are available in many Python formatting guides. If you want, I can provide a detailed summary or a "bot dump" of the format spec mini-language with examples—just let me know! [1] https://realpython.com/python-format-mini-language/ [2] https://docs.python.org/3/library/string.html [3] https://realpython.com/python-string-formatting/ [4] https://stackoverflow.com/questions/44551535/access-the-cpython-string-format-specification-mini-language-parser [5] https://www.telerik.com/blogs/string-formatting-python [6] https://docs.python.org/3/tutorial/inputoutput.html [7] https://learnpython.com/blog/python-string-formatting/ [8] https://pyformat.info [9] https://mimo.org/glossary/python/formatted-strings- The Format Specification Mini-Language is extensible because each class gets to interpret the format_spec argument as it likes.
Enhancing/extending FormatSpec for our custom objects
extending is as simple as just having a bunch of if-elses pased on the format spec that we get.
seems like it’s a good practice to remove the
'p'suffix fromfmt_spec. This is so that the subsequent formatting calls on the individual components downstream this part of the code doesn’t get confused.Thus, to preserve compatibility with the built-in format machinery, the custom
'p'suffix must be removed before passing thefmt_specdown toformat()elaboration:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78Great question! Let's analyze the code snippet and the rationale behind removing the custom `'p'` suffix from the `fmt_spec` in the `__format__` method. ### Context Recap: What Is Happening Here? The method `__format__` is being customized in a class that likely represents a 2D vector or complex number-like object with components and angle: ```python def __format__(self, fmt_spec=''): if fmt_spec.endswith('p'): fmt_spec = fmt_spec[:-1] coords = (abs(self), self.angle()) outer_fmt = '' else: coords = self outer_fmt = '({}, {})' components = (format(c, fmt_spec) for c in coords) return outer_fmt.format(*components) ``` - **`fmt_spec`**: The format specification string passed when formatting, e.g., in an f-string. - **Custom `'p'` suffix:** If the format spec ends with `'p'`, the method interprets it as a special request to format the vector in *polar coordinates* — providing `(r, θ)` instead of `(x, y)`. - If `'p'` is detected, it is **stripped off** (`fmt_spec = fmt_spec[:-1]`), so it doesn't confuse the subsequent formatting calls on the individual float components. ### Why Remove the Custom `'p'` Suffix from `fmt_spec`? #### 1. **Format specifiers need to be valid for the inner formatting calls** - The method eventually calls `format(c, fmt_spec)` on each component, where each `c` is a float (radius and angle) or float-like. - The Python built-in formatter (`format()` function) and the numeric format mini-language **do not recognize `'p'`** as a valid format code. - If `'p'` were left in the format spec string, calling `format(float_value, fmt_spec)` would raise a `ValueError` because `'p'` is not a defined type specifier. Thus, to **preserve compatibility with the built-in format machinery**, the custom `'p'` suffix must be removed **before** passing the `fmt_spec` down to `format()`. #### 2. **Maintaining a clean interface for users** - The `'p'` suffix acts as a *signal* to the `__format__` method that **polar formatting** should be used. - By removing it early, the code simply leverages the underlying float formatting logic for the numeric components while exposing a neat, domain-specific format feature. - This lets users write something like `format(vec, ".2fp")` -- meaning "format this vector in polar coordinates, with two decimal places," where `" .2f"` is the standard float format and `'p'` is the custom extension. #### 3. **Separation of concerns** - The `'p'` flag is handled at the level of `__format__` **only** to choose the representation (Cartesian vs polar). - The output formatting of numeric components is delegated to the built-in or standard format spec mini-language. - Removing `'p'` keeps these concerns cleanly separated and avoids leaking the custom format logic into the lower formatting layers. ### Mental Model: Decorator Analogy to Formatter Chains We can think of this like a decorator on the `format` function: - The outer function (`__format__`) decorates or wraps the usual formatting logic. - It handles the special parameter (`'p'`) that changes *what* is formatted (polar vs Cartesian). - Then it **cleans** the format spec for the underlying calls that format numeric components, passing on only the valid portion (`.2f`, `.3e`, etc.). - This preserves **compatibility, safety, and separation** between the custom feature and standard behavior. ### Summary | Reason | Explanation | |------------------------------------------|---------------------------------------------| | Prevent invalid format spec errors | `'p'` is **not valid** in built-in float format codes; must be removed before numeric formatting calls. | | Clean user interface for extended formatting | `'p'` is a **custom flag** for polar representation, distinct from numeric formatting codes. | | Separation of concerns | Handle polar/cartesian choice separately from numeric formatting of components. | | Avoid breaking the built-in `format()` contract | Passing `'p'` would cause exceptions or undefined behavior. | ### Optional: What Happens if You Don’t Strip `'p'`? If the code passes on the whole string including `'p'`, e.g., `"5.2fp"`, to `format(1.23, "5.2fp")` on a float: - Python raises a `ValueError` like: ``` ValueError: Unknown format code 'p' for object of type 'float' ``` Because `p` is an unknown format type in the standard format mini-language. If you want, I can provide more detailed examples or links to the Python format spec mini-language documentation or even discuss how this relates to PEP 3101 formatting protocol and how to design robust `__format__` implementations. **In essence, the removal of the custom 'p' suffix from the format spec string ensures that this domain-specific extension coexists safely with Python’s built-in formatting system, maintaining robustness and good user experience.**
we should try to avoid confusion for the users of the custom object. Just try not to reuse a code-letter that already exists in similar object types (make reference to the formatspec mini language to see what is already available)
A Hashable Vector2d
what hashability unlocks:
- we can keep sets of our custom object
- we can use our custom object as
dictkeys
how?
have to implement
__hash__and__eq__and make the object immutable.technically the immutability (by protecting accesses and using private attrs is not a strict requirement).
for immutability, fields can be converted to private fields (two leading underscores) and adding
@propertydecorators to define the getter functions for these.
Supporting Positional Pattern Matching
what are positional patterns?
the examples here are non-positional because each value is provided:
1 2 3 4 5 6 7 8 9 10 11 12def keyword_pattern_demo(v: Vector2d) -> None: match v: case Vector2d(x=0, y=0): print(f'{v!r} is null') case Vector2d(x=0): print(f'{v!r} is vertical') case Vector2d(y=0): print(f'{v!r} is horizontal') case Vector2d(x=x, y=y) if x==y: print(f'{v!r} is diagonal') case _: print(f'{v!r} is awesome')so a positional pattern would look something like this:
case Vector2d(_, 0):have to add
__match_args__: need to add a class attribute named__match_args__, listing the instance attributes in the order they will be used for positional pattern matchingtypically at least have the required args within
__match_args__
Complete Listing of Vector2d, Version 3
Just to put a pin on the v3 of this didatic example:
| |
TO_HABIT: TIL that python has doctests too!
damn.
Private and “Protected” Attributes in Python
there’s no way to actually make the variables private and immutable though
name mangling: why the double underscores is useful to useconsider the case where if we don’t have a good mechanism for “private” attributes, it’s going to be possible for a child subclass to accidentally overwrite a parent-attribute
with this in mind, the mechanism for using the double underscores is to mangle the name with the class name.
Python stores the name in the instance
__dict__prefixed with a leading underscore and the class name, so in the Dog class,__mood(the “private” attr) becomes_Dog__mood, and in Beagle it’s_Beagle__mood.This language feature goes by the lovely name of name mangling.
It’s a safety feature (to prevent accidentally access / modification) rather than a security feature.
“Protected attributes”:
for those that don’t like the name mangling feature, they can just use a convention of a single underscore and explicitly naming the attribute in a “mangled” fashion.
this has no special interpreter support though.
GOTCHA: In modules, a single _ in front of a top-level name does have an effect:
if you write
from mymod import *, the names with a _ prefix are not imported from mymod. However, you can still write from mymodimport _privatefunc.
Saving Memory with __slots__
instance attributes’ storage model:
typically stored within a dict (
__dict__), which has significant memory overheadif we use
__slotsto hold a sequence of attr names, then it’s an alternative storage model.stored in a hidden array / references that use less memory than a
dict
using slots:
the
__slots__attribute holds attrs in either atuple(similar to the__match_args__) orlist.Tuple is clearer since it implicitly shows that there’s no changing it.
can only be defined when the class is defined, can’t be updated (referring to its shape) thereafter
COUNTER-INTUITIVE:
a subclass only partially inherits the effect of the parent’s
__slots__.Partial because:
slot attrs defined in the parent will still be stored in the reference array
attrs not stored in the parent will end up being stored in a dict.
Slots of the supercalsses are added to the slots of the current class.
we can have both slots (fixed attributes) and dict (dynamic attributes)
if we need weak refs AND we’re using slots, then the slots attributes should include
'__weakref__'NOTE: slots will end up referring to the internal storage variables and match args will ref to the public attribute names for positional pattern matching.
Simple Measure of slot Savings
here’s how they did the checking of ram usage and such
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29import importlib import sys import resource NUM_VECTORS = 10**7 module = None if len(sys.argv) == 2: module_name = sys.argv[1].replace('.py', '') module = importlib.import_module(module_name) else: print(f'Usage: {sys.argv[0]} <vector-module-to-test>') if module is None: print('Running test with built-in `complex`') cls = complex else: fmt = 'Selected Vector2d type: {.__name__}.{.__name__}' print(fmt.format(module, module.Vector2d)) cls = module.Vector2d mem_init = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss print(f'Creating {NUM_VECTORS:,} {cls.__qualname__!r} instances') vectors = [cls(3.0, 4.0) for i in range(NUM_VECTORS)] mem_final = resource.getrusage(resource.RUSAGE_SELF).ru_maxrss print(f'Initial RAM usage: {mem_init:14,}') print(f' Final RAM usage: {mem_final:14,}')Essentially, the slot version uses half as much RAM and is faster.
Summarizing the Issues with slots
remember to redeclare
__slots__in each subclass to prevent their instances from having__dict__the instance slots are binded ONLY at the time when the class is defined
classes can’t use
@cached_propertydecorator unless the slot attributes includes'__dict__'class instances can’t be targets of weak references unless we add
'__weakref__'in the slots.
Overriding Class Attributes
a common use case for class attributes is to provide default values for instance attributes
what happens is that
self.typecodegets default resolved by treating it as a class attribute (in the case that there’s no such instance attribute).If you want to change a class attribute, you must set it on the class directly, not through an instance.
So do
Vector2d.typecode = 'f'instead of doingv1.typecode = 'f'the more idiomatic way is to subclass just to customise a class data attribute
subclass to customise
Chapter Summary
we can add in more control to our code (adding getters, keeping attributes immutable) on a need-basis since the consumers / places the class will be referred from will not change.
So we can stick to public attributes first.
Implementing setters and getters up-front is a distraction from the goal. In Python, we can simply use public attributes, knowing we can change them to properties later, if the need arises.
extra: in java’s enforced privacy idioms, the privacy is only really enforced if there’s a Java Security Manager that is configured and deployed on top of the java app.
this is because the reflections API (introspection tooling for Java) can be used to read the value of a private field.
Further Reading
Chapter 12. Special Methods for Sequences
Objectives for this chapter:
Make the toy vector implementation behave like a standard Python immutable flat sequence. with float elements
supports the following:
basic sequence protocol
__len__and___getitem__safe representation of instances with many items
slicing supported properly
aggregate hashing that considers every element
custom formatting extensions
Useful TRICKS:
- we can get the class of an instance by doing
cls = type(self)
- we can get the class of an instance by doing
What’s New in This Chapter
Vector: A User-Defined Sequence Type
Vector space benefits: use cases of vectors > 3 dims:
- for implementing N-dimensional vectors for info retrieval
- for vector space models, cosine similarity is usually the key metric for relevance.
the takes on the vector implementation behaviour are not mutually exclusive, they build on each other
Vector Take #1: Vector2d Compatible
the best practice for a sequence constructor is to take the data as an iterable argument in the constructor, like all built-in sequence types do.
remember the goal for a good implementation of
__repr__is that it should give serviceable output such that a user can have a chance of identifying the receiver (self).the
reprlib.repr()can be used to get a limited-lenght representation
Protocols and Duck Typing
- Protocols:
context of object-oriented programming, a protocol is an informal interface, defined only in documentation and not in code.
it’s ONLY a typing/tooling construct for static analysis, it supports structural subtyping / static duck-typing.
we can partially implement part of a protocol if we wish, depending on the contextual requirements
there’s 2 kinds of protocols:
static protocols
Definition:
Static protocols in Python refer to protocol classes (from typing.Protocol) that exist solely for static type analysis during development—they have no effect at runtime unless specially marked.
Purpose:
To provide interfaces that static type checkers (like mypy or Pyright) can use for verifying whether an object “matches” a required set of methods/attributes, regardless of explicit inheritance.
Behavior:
A class matches a static protocol if it provides ALL required methods/attributes (matching names and type signatures).
There is no runtime enforcement or validation by default—type conformance is only checked when tools like mypy analyze your code.
Classes do not need to inherit from the protocol to be considered as conforming to it for static analysis
Use case:
Ensuring that different objects used in a function provide a required interface (“static duck typing”), enabling type-safe polymorphism and generic programming.
1 2 3 4 5 6from typing import Protocol class SupportsClose(Protocol): def close(self) -> None: ... # Any class with a .close() method matches SupportsClose for type checkingdynamic protocols Definition:
Dynamic protocols are protocol classes designed to support runtime checking of protocol conformance, in addition to static analysis.
Purpose:
To enable both static type checking and runtime assertions that an object supports a given protocol interface.
How:
Achieved by decorating the protocol class with
@typing.runtime_checkableBehavior:
At runtime, you can use
isinstance(obj, ProtocolClass)to check if an object supports the protocol (i.e., implements the required methods/attributes).The protocol still does not require explicit inheritance—conformance is structural.
1 2 3 4 5 6 7 8from typing import Protocol, runtime_checkable @runtime_checkable class SupportsClose(Protocol): def close(self) -> None: ... obj = open("file.txt") isinstance(obj, SupportsClose) # True if .close() exists with correct signature
Vector Take #2: A Sliceable Sequence
delegation is an easy way to support the protocol.
Have to ensure that the types don’t change for the ones that are supposed to return our custom type, the example being used here is for slice functionality, it’s in these instances that we can’t just use delegation and have to explicitly handle it.
How Slicing Works
- some observations on how slicing is handled:
the accessor
s[1:5]returns a slice objectwe can have multiple slices in our accessing if we do something like
s[1:5, 8:10]and we’ll get something like this:(slice(1, 5, None), slice(8, 10, None))from which we conclude:
it’s a tuple (of
sliceobjects) that is being returnedthe tuple may return multiple
sliceobjects
sliceis a builtin type, with attrsstart,stop,stepandindiceswe found this by doing
dir(slice)indices exposes the tricky logic that’s implemented in the built-in sequences to gracefully handle missing or negative indices and slices that are longer than the original sequence. This method produces “normalized” tuples of non-negative start, stop, and stride integers tailored to a sequence of the given length.
NOTE: we don’t need to implement this for the vector example here because we’ll be delegating it to the
_componentsarray
- some observations on how slicing is handled:
A Slice-Aware
__getitem__to make
Vectorbehave as a sequence, we need__len__and__getitem__both are essential to handle slicing correctly
There’s 2 cases to handle:
case 1: we’re accessing via a slice
in this case, we have to extract out the class and then build another Vector instance from the slice of the components array.
this is what allows us to properly return Vector classes on sliced accesses.
case 2: we’re accessing via a single index
then we can extract out the index from the key using
operator.index(key)operator.index()function calls the__index__special method. The function and the special method. It’s defined in this PEP 357it’s different from
intin the sense thatoperator.index()will return aTypeErrorfor non-int arguments supplied as an attempt to access an index.
1 2 3 4 5 6 7 8 9 10 11 12def __len__(self): return len(self._components) def __getitem__(self, key): # case 1: we're accessing via a slice if isinstance(key, slice): cls = type(self) return cls(self._components[key]) # case 2: we're accessing via a single index index = operator.index(key) return self._components[index]
Vector Take #3: Dynamic Attribute Access
the
__getattr__is the fallback function if a name is not found within the various hierarchy graphs (not in instance, not in class, not in inheritance graph)KIV part 4 of the textbook for more info on attribute lookups
1 2 3 4 5 6 7 8 9 10 11 12 13 14__match_args__ = ('x', 'y', 'z', 't') # allows positional pattern matching def __getattr__(self, name): cls = type(self) try: pos = cls.__match_args__.index(name) except ValueError: pos = -1 if 0 <= pos < len(self._components): return self._components[pos] msg = f'{cls.__name__!r} object has no attribute {name!r}' raise AttributeError(msg)GOTCHA: since
__getattr__is a fallback, the following snippet behaves inaccuratelythis is because when we do the
v.x, it gets accessed to a new attribute calledv.xwithin instancev. Therefore, the name resolution never gets done by the fallback (__getattr__)The implementation for
__getattr__also doesn’t account for such names\(\implies\) we implement
__setattr__because the problem here is in the attribute setting, that’s not behaving properly here.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15def __setattr__(self, name, value): cls = type(self) if len(name) == 1: if name in cls.__match_args__: error = 'readonly attribute {attr_name!r}' elif name.islower(): error = "can't set attributes 'a' to 'z' in {cls_name!r}" else: error = '' if error: msg = error.format(cls_name=cls.__name__, attr_name=name) raise AttributeError(msg) # default: use the superclass's __setattr__ super().__setattr__(name, value)For this example, we want the
xandyto be readonly, that’s why we’re throwing attribute errors.NOTE: usually getters and setters come together to ensure some consistency in the use of the objects.
here, we had to implement both
__getattr__and__setattr__NOTE: we shouldn’t use
__slots__as a shortcut to prevent instance attribute creation, they should be used only to save memory, when needed. In this case, we prevent readonly attribute overwrites by implementing the__setattr__properly that handles this.
Vector Take #4: Hashing and a Faster ==
implementing the hash function that is performant
1 2 3 4 5 6 7 8 9 10import functools import operator def __eq__(self, other): return tuple(self) == tuple(other) def __hash__(self): # NOTE: use generator here for lazy operations. hashes = (hash(x) for x in self._components) return functools.reduce(operator.xor, hashes, 0)alternatively, hash could have been implemented as:
1 2 3def __hash__(self): hashes = map(hash, self._components) return functools.reduce(operator.xor, hashes)so the fast hash here can use an XOR:
functools.reduce(lambda a, b: a ^ b, range(n))or using
operator.xorlike sofunctools.reduce(operator.xor, range(n))interesting: we can see the initializer ALSo as a value to return on empty sequence (in addition to the usual “first argument in the reducing loop”).
for
+,|,^the initializer should be0, but for*,&it should be1.TO_HABIT: remember that
operatorprovides the functionality of all Python infix operators in function form, so using it will prevent custom lambda definitionsTO_HABIT: using
functools.reducefor the fast compute of a hash with huge number of components is a good use case for using reduce.
improving the performance of
__eq__doing the tuple conversion will be expensive for large vectors.the better implementation reminds me of Java style:
1 2 3 4 5 6 7def __eq__(self, other): if len(self) != len(other): return False for a, b in zip(self, other): if a != b: return False return Truea one liner:
1 2def __eq__(self, other): return len(self) == len(other) and all(a == b for a, b in zip(self, other))
Vector Take #5: Formatting
Chapter Summary
So this is the final code, vector_v5.py:
| |
- uses
itertools.chainfor the__format__function - KIV the generator tricks until chapter 17
Further Reading
reducehas other names in the CS world!The powerful
reducehigher-order function is also known asfold,accumulate,aggregate,compress, andinject.See the wiki link.
you can often tell when a protocol is being discussed when you see language like “a file-like object.” This is a quick way of saying “something that behaves sufficiently like a file, by implementing the parts of the file interface that are relevant in the context.”
it’s not sloppy to implement a protocol partially (for dynamic protocols)
When implementing a class that emulates any built-in type, it is important that the emulation only be implemented to the degree that it makes sense for the object being modeled. For example, some sequences may work well with retrieval of individual elements, but extracting a slice may not make sense.
this KISS-es it.
for more strictness, we can make it a static protocol wherein everything needs to be implemented
Chapter 13. Interfaces, Protocols, and ABCs
python has 4 ways to define and use interfaces:
Duck typing
goose typing: using ABCs
^ focus of this chapter
static typing: traditional static typing using the
typingmodulestatic duck typing
popularised by GoLang, supported by
typing.Protocol
this chapter is about the typing that revolves around interfaces.
The Typing Map
The two dimensions introduced here:
runtime vs static checking
structural (based on method’s provided by the object) vs nominal (based on the name of its class/superclass)
What’s New in This Chapter
Two Kinds of Protocols
In both cases, we don’t need to do any sort of explicit registration for the protocol (or to use inheritance).
Dynamic Protocol
Implicit, defined by convention as per documentation.
A good example is the protocols within the interpreter, seen in the “Data Model” of the language ref. e.g. Sequence, Iterable
Can’t be verified by type checkers
Static Protocol
An explicit definition as a subclass of
typing.ProtocolABCs ca n be used to define an explicit interface (similar in outcome to static protocols).
Programming Ducks
Python Digs Sequences
- this is pretty cool: Python manages
to make iteration and the
inoperator work by invoking__getitem__when__iter__and__contains__are unavailable.The interpreter uses special methods (
__getitem__,__iter__, etc.) dynamically to support iteration and membership tests even without explicit ABCs. This is a classic Python dynamic protocol idiom.
Monkey Patching: Implementing a Protocol at Runtime
Monkey patching is dynamically changing a module, class, or function at runtime, to add features or fix bugs.
in this example, we want a custom class to automatically work with
random.shuffle()so that we can shuffle that sequence.We inspect
random.shuffle()and figure out what it’s underlying functionality is, which is to rely on the__setitem__function.So we can monkey patch the
__setitem__and we can achieve our desired outcome. This means that we change the module @ runtime.Monkey patching is powerful, but the code that does the actual patching is very tightly coupled with the program to be patched, often handling private and undocumented attributes.
Python does not let you monkey patch the built-in types. I actually consider this an advantage, because you can be certain that a str object will always have those same methods. This limitation reduces the chance that external libraries apply conflicting patches.
Defensive Programming and “Fail Fast”
TO_HABIT: the examples here show how to do a check by checking whether it can behave like a duck instead of checking whether it’s a duck. This is a superior way of doing meaningful type checks in my opinion but there’s some possible pitfalls into doing so.
we want to be able to detect dynamic protocols without explicit checks
Failing fast means raising runtime errors as soon as possible, for example, rejecting invalid arguments right a the beginning of a function body.
Duck type checking means we should check behaviour instead of doing explicit typechecks.
Some patterns:
IDIOM: use a builtin function instead of doing type-checking \(\implies\) check for method presense
in the example, to check if the input arg is a list, instead of doing a type check at runtime, it’s suggested to use the
list()constructor because that constructor will handle any iterable that fits in memory. Naturally, this copies the data.If we can’t accept copying, then we can do runtime check using
isinstance(x, abc.MutableSequence)warning: what if infinite generator?
eliminate that by calling
len()on the arg, tuples, arrs and such will still pass this check
Defensive code leveraging duck types can also include logic to handle different types without using
isinstance()orhasattr()tests.suppose we want to type hint that “
field_namesmust be a string of identifiers separated by spaces or commas”,then our check could do something like this:
1 2 3 4 5 6 7 8 9 10Example 13-5. Duck typing to handle a string or an iterable of strings try: # this is an attempt, assumes that it's a string field_names = field_names.replace(',', ' ').split() except AttributeError: pass # if not string, then can't continue testing, just pass it # converting to a tuple ensures that it's iterable and we test our own copy of it (to prevent accidentally changing the input) field_names = tuple(field_names) if not all(s.isidentifier() for s in field_names): raise ValueError('field_names must all be valid identifiers')This is an expressive form of using duck typing to our advantage for type checking.
Goose Typing
- ABCs help to define interfaces for explicit type checking at runtime (and also work for static type checking).
complement duck typing
introduce virtual subclasses:
- classes that don’t inherit from a class but are still recognized by
isinstance()andissubclass()
- classes that don’t inherit from a class but are still recognized by
Waterfowl and ABCs
the strong analogy of duck typing to actual phenetics (i.e. phenotype-based) classification is great, mimics how we do duck typing (based on shape and behaviour)
how important is the explicit type checking depends on the usage-context of an object
parallel objects can produce similar traits and this is the case where we may have false positives on the classifications
that’s why we need a more “explicit” way of typechecking and that’s where “goose typing” comes into the picture.
python’s ABCs provide the
registerclass-method which lets us “declare” that a certain class becomes a “virtual” subclass of an ABC (meets name, signature and semantic contract requirements)we can declare this even if the class need not have been developed with any awareness of the ABC (and wouldn’t have inherited from it) \(\implies\) this is structural subtyping with ABCs where the structure is sufficient
registration can be implicit (without us needing to register custom classes), just have to implement the special methods.
- key advice:
When implementing a class that represents a concept from the standard library’s ABCs (e.g., Sequence, Mapping, Number, etc.):
Explicitly inherit from or register with the appropriate ABC if your class fits the contract of that ABC.
This helps make your class reliably compatible with tools, libraries, or Python code that expects these standard interfaces.
If a library or framework you use defines classes but omits to formally subclass/register with the standard ABCs:
Perform the ABC registration yourself at program startup (e.g., by manually registering the class with
collections.abc.Sequence).This will ensure
isinstance(obj, collections.abc.Sequence)checks work as intended, improving reliability and interoperability.When checking if an object matches a conceptual interface (such as being a “sequence”):
Use isinstance(the_arg, collections.abc.Sequence) rather than checking for method presence (duck typing) or relying on type names.
This is more future-proof and integrates with Python’s built-in and third-party tools.
Avoid defining your own custom ABCs or metaclasses in production code:
These advanced features are often overused and can lead to unnecessarily complex, harder-to-maintain code.
The author likens custom ABCs/metaclasses to a “shiny new hammer”: appealing when you first learn them, but prone to misuse (“all problems look like a nail”).
Emphasizes sticking to straightforward, simple code for better maintainability and happiness for you and future developers.
Tension between Duck Typing and Goose Typing
They are a continuum, not an either/or. Use duck typing for everyday, flexible code, and goose typing (ABCs and explicit interface contracts) where precision, reliability, and maintainability matter (public APIs, reusable libraries, systems programming).
See richer elaboration here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80You've highlighted a key *tension* in Python between **duck typing** ("if it quacks like a duck, treat it as a duck") and **ABC-based explicit/virtual interface type checking** ("goose typing," using `isinstance` with domain-driven interfaces made explicit via ABCs). Let’s clarify how these approaches relate and when to use each. ### Duck Typing (Classic Pythonic Style) **Principle**: *Check for behavior, not type.* If you expect an object to behave like a sequence, just try to use it as such (e.g., iterate over it, index into it). If it fails at runtime, raise an error immediately (“fail fast”). **Code example:** ```python def head(seq): return seq[0] # works for any object supporting indexing ``` - If `seq` supports indexing (`__getitem__`), this just works. - This is *pure duck typing*—no explicit type checks or interface enforcement. ### Goose Typing: ABCs and Virtual Subclassing **Principle**: Use Python’s Abstract Base Classes (`collections.abc.Sequence`, `MutableMapping`, etc.) to define *explicit interfaces* for families of types (not just classes). - You can *register* a class as a "virtual subclass" of an ABC, even if it doesn't inherit from it. - Now, `isinstance(obj, collections.abc.Sequence)` will treat your class as a Sequence. **Benefits:** - Enables more robust and explicit type checks. - Useful when interoperating with other libraries, for documentation, for static-checking tools, or when you want to *fail fast* with a clear, predictable check. - Python’s standard library and third-party tools often use `isinstance(x, ABC)` checks internally, so registering your custom class improves **interoperability**. ### How do these approaches relate? - **Duck typing**: Write code that operates on any object with the required behaviors (methods/attributes), with no formal interface contract. - Pro: maximal flexibility; principle of least surprise for Pythonistas. - Con: can result in runtime errors that are sometimes hard to debug or anticipate. - **Goose typing**: Explicitly document and/or enforce the “duck” shape via ABCs—*preferably standard library ABCs*—and use `isinstance` checks for run-time or static confirmation. - Con: Slightly more rigid, but much clearer and more future-proof if you want predictable, explicit interfaces. **In modern large-scale or library codebases, combining duck typing for flexibility with ABCs for explicit interface definition (“goose typing”) gives you both power and predictability.** ### Practical Guidance from Your Notes - Use **duck typing** by default; just try the operation and handle exceptions—this is flexible, concise, and Pythonic. - For situations where: - You need to *fail fast*, - You want to document and defend API boundaries, - You’re interacting with other libraries/frameworks using ABCs, **it’s recommended to explicitly register your classes with appropriate ABCs and use `isinstance` checks**. - This isn't an either/or—it's a continuum. Use *duck typing* for everyday, flexible code, and *goose typing* (ABCs and explicit interface contracts) where precision, reliability, and maintainability matter (public APIs, reusable libraries, systems programming). ### Metaphor Recap - **Duck typing**: "Does it walk and quack like a duck? Use it as a duck." - **Goose typing**: "Let's agree on what waterfowl are. If you’re a duck, get your name on the official registry, so everyone knows for sure and tools can verify it." ### References - [Python's isinstance docs][1] - [Structural subtyping via ABCs and the register method][11] **Summary:** - *"Duck typing"* means acting on behaviors and handling failures. - *"Goose typing"* means using ABCs for explicit, reliable interface checks (`isinstance` and virtual subclassing). - Use each to the degree that your problem, API guarantees, and interoperability demand. Both are core to Pythonic code. Let me know if you want idiomatic examples for when to use each or more detailed pros/cons for specific scenarios! [1] https://realpython.com/what-does-isinstance-do-in-python/ [2] https://stackoverflow.com/questions/1549801/what-are-the-differences-between-type-and-isinstance [3] https://ioflood.com/blog/python-isinstance-function-guide-with-examples/ [4] https://switowski.com/blog/type-vs-isinstance/ [5] https://www.reddit.com/r/learnpython/comments/hg6fyd/do_not_compare_types_use_isinstance_instead/ [6] https://github.com/python/typing/issues/1363 [7] https://stackoverflow.com/questions/3111611/is-this-use-of-isinstance-pythonic-good [8] https://realpython.com/python-type-checking/ [9] https://www.curiousefficiency.org/posts/2004/12/type-checking-in-python/ [10] https://typing.python.org/en/latest/guides/type_narrowing.html [11] https://peps.python.org/pep-0544/
Subclassing an ABC
This is about using goose-typing in practice.
- we can use the subclassing as a benchmark for this section on subclassing:
needed to adhere strictly to the interface.
therefore there’s a need to implement concrete versions of all the abstract methods defined in the abc.
concrete methods are implemented in terms of the public interface of the class, so it’s possible for us to subclass without any knowledge of the internal structure of the instances.
- we can use the subclassing as a benchmark for this section on subclassing:
ABCs in the Standard Library
some places we can find useful ABCs:
collections.abcmodule (most widely used),iopackage,numberspackagefrom
collections.abc
NOTE: photo is outdated, from python 3.6 Sequence, Mapping and Set are subclassed from Collection, which is a child of Iterable, Container, Sized
Remember that each of the immutable collections have a mutable subclass.
if
insinstance(obj, Hashable)returnsFalse, you can be certain that obj is not hashable. But if the return isTrue, it may be a false positive.also for
isinstance(obj, Iterable), we might have false negatives. This is because Python may stil be able to iterate overobjusing__getitem__TO_HABIT: duck typing is the most accurate way to determine if an instance is hashable/iterable: if we just call
hash(obj)/iter(obj)
Defining and Using an ABC
this is only for learning purposes, we should avoid implementing our own ABCs and metaclasses.
A good usecase for ABCs, descriptors, metaclasses are for building frameworks.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32# tag::TOMBOLA_ABC[] import abc class Tombola(abc.ABC): # <1> subclass abc.ABC to define an ABC @abc.abstractmethod def load(self, iterable): # <2> use this decorator, keep the body empty, can include in docstring """Add items from an iterable.""" @abc.abstractmethod def pick(self): # <3> """Remove item at random, returning it. This method should raise `LookupError` when the instance is empty. """ def loaded(self): # <4> ABC may include concrete methods. """Return `True` if there's at least 1 item, `False` otherwise.""" return bool(self.inspect()) # <5> def inspect(self): """Return a sorted tuple with the items currently inside.""" items = [] while True: # <6> try: items.append(self.pick()) except LookupError: break self.load(items) # <7> return tuple(items) # end::TOMBOLA_ABC[]some observations:
since this is abstract, we can’t know what the concrete subclasses will actually use for the implementation \(\implies\) we end up trying to use the other abstract functions more so than assuming things.
it’s OK to provide concrete methods in ABCs, as long as they only depend on other methods in the interface.
For example, for
inspect, we use the abstractpickfunction andloadto return it to the original state.Before ABCs existed, abstract methods would raise
NotImplementedErrorto signal that subclasses were responsible for their implementation.NOTE: an
@abstractmethodmethod can have a base implementation. The subclass will still need to override it but the subclass will also be able to access it usingsuper()and build onto / directly use the super functionality.LANG_LIMITATION: there’s no formal method for “adding” expected error types (exceptions) in Python Interfaces. No exception contracts.
Docs are the only practical way to make expected exceptions explicit in Python interfaces today. Writing thoughtful docstrings and custom exception classes is the accepted best practice. ABCs enforce method presence not exception contracts.
more elaboration here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67When it comes to specifying or "adding" expected error types (exceptions) in Python interfaces like abstract base classes (ABCs) or general functions, **the language itself provides no formal mechanism** to declare which exceptions a method or function should raise, unlike some statically typed languages that have checked exceptions. ### How do we communicate expected error types in Python then? 1. **Documentation is the de facto standard for specifying expected exceptions** - Docstrings are the primary place to declare what errors a method can raise. This is how Python developers indicate usage interface contracts including possible exceptions. - For example: ```python def divide(x, y): """ Divide x by y. Raises: ZeroDivisionError: If y is zero. TypeError: If inputs are not numbers. """ return x / y ``` 2. **ABCs and raising `NotImplementedError` for abstract methods** - When defining abstract methods in ABCs, it is common to raise `NotImplementedError` to indicate subclasses *must* implement that method. - This is the only *exception-related interface* that ABCs imply formally in code. 3. **Static typing tools (e.g., MyPy) do not check for exceptions raised** - Current Python type checkers mostly ignore exception flow or explicitly declared exceptions. There is no built-in or standard way to express exception contracts in type hints. 4. **Custom exception classes for domain-specific errors** - For clarity and maintainability, if your interface or library can raise expected errors, you should define and document custom exception classes. - You communicate the valid exceptions by naming them in documentation and/or user guides. ### Why does Python not have explicit exception declarations on interfaces? - Python follows an **EAFP (Easier to Ask Forgiveness than Permission)** ethos. - Explicit exception declarations would add verbosity and complexity. - Pythonic style encourages **handling exceptions where you can recover** and letting others propagate upward naturally. - **Fail-fast philosophy** encourages letting the system raise unexpected exceptions during development and handling them appropriately in higher layers. ### Summary table: | Approach | Mechanism | Remarks | |------------------------|------------------------------|------------------------------------------------| | Expected exceptions | Documented in docstrings | Widely accepted convention | | ABC interface contract | Raise `NotImplementedError` | Defines required implementations, not errors raised in general | | Static typing | No standard exception syntax | No checked exceptions like in Java, C# | | Custom exceptions | Define exception classes | Clarifies error types, improves maintainability| | Runtime enforcement | Try/except handlers | Handle errors where recovery/alternative is feasible | ### Additional notes: - If you want to **make expected exceptions more discoverable**, consider tools that generate API docs (Sphinx, pdoc) that especially call out `:raises:` sections in your docstrings. - In complex frameworks, **middleware or wrapper layers** may catch and re-raise or convert exceptions for clearer error handling without explicit declaration in the interface. - Some third-party libraries or custom frameworks might support more formal error policies (contracts), but this is not core Python. **In essence:** **Docs are the only practical way to make expected exceptions explicit in Python interfaces today.** Writing thoughtful docstrings and custom exception classes is the accepted best practice. ABCs enforce method presence **not** exception contracts. If you want, I can help you draft a template for documenting expected exceptions clearly in your Python APIs. [1] https://docs.python.org/3/library/exceptions.html [2] https://realpython.com/python-built-in-exceptions/ [3] https://stackoverflow.com/questions/57658862/making-an-abstract-base-class-that-inherits-from-exception [4] https://docs.python.org/3/library/abc.html [5] https://mypy.readthedocs.io/en/stable/error_code_list.html [6] https://labex.io/tutorials/python-how-to-handle-abstract-method-exceptions-437221 [7] https://blog.sentry.io/practical-tips-on-handling-errors-and-exceptions-in-python/ [8] https://accuweb.cloud/resource/articles/explain-python-valueerror-exception-handling-with-examples
ABC Syntax Details
we used to have the other abstract decorators:
@abstractclassmethod,@abstractstaticmethod,@abstractpropertybut they’re deprecated now because we can decorator stackwhen decorator stacking,
@abc.abstractmethodMUST be the innermost decoratorthe order of decorators matter.
1 2 3 4 5class MyABC(abc.ABC): @classmethod @abc.abstractmethod def an_abstract_classmethod(cls, ...): pass
Subclassing an ABC
delegation of functions (e.g. init delegates to another ABC’s functions) seems to be a good idea to keep the code consistent
whether to override the concrete implementations from the ABC is our choice to make
A Virtual Subclass of an ABC
Here’s an example of a subclass:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23from random import randrange from tombola import Tombola @Tombola.register # <1> NOTE: being used as a decorator here, could have been a plain function invocation as well class TomboList(list): # <2> def pick(self): if self: # <3> position = randrange(len(self)) return self.pop(position) # <4> else: raise LookupError('pop from empty TomboList') load = list.extend # <5> def loaded(self): return bool(self) # <6> def inspect(self): return tuple(self) # Tombola.register(TomboList) # <7>it’s a “trust me bro” but if we lie, we still get caught by the usual runtime exceptions
issubclassandisinstancewill work but there’s no real inheritance of any methods or attributes from the ABC- this happens because inheritance is guided by the
__mro__class attribute ( for method resolution order ) and in this case, only “real” superclasses exist in the__mro__
- this happens because inheritance is guided by the
syntax:
usually a plain function invocation, can be done in a decorator style as well
Tombola.register(TomboList)function invocation style (called after the class definition)@Tombola.register(decorator style)
- Usage of register in Practice
Structural Typing with ABCs
typically we use nominal typing for ABCs. it happens when we have an explicit inheritance, which registers a class with its parent and this links the name of the parent to the sub class and that’s how at runtime, we can do
issubclasschecks.Dynamic and Static Duck Typing are two approaches to static typing
we can do consistent-with structural subtyping as well if the class implements the methods defined in the type
this works because parent subclass (abc.Sized) implements a special class method named
__subclasshook__. The__subclasshook__forSizedchecks whether the class argument has an attribute named__len__this is the implementaion within ABCMeta
1 2 3 4 5 6@classmethod def __subclasshook__(cls, C): if cls is Sized: if any("__len__" in B.__dict__ for B in C.__mro__): return True return NotImplementedwe shouldn’t add the hook for our custom functions. It’s not dependable to rely on this implicit behaviour.
Static Protocols
The Typed double Function
- duck typing allows us to write code that is future-compatible!
Runtime Checkable Static Protocols aka Dynamic Protocol
typing.Protocolcan be used for both static and runtime checkingif we want to use it for runtime checking, then we need to add
@runtime_checkableto the protocol definitionhow this works is that
typing.Protocolis an ABC and so it supports__subclass__hook and adding the runtime checkable decorator allows us to make the protocol supportisinstance/issubclasschecks. Because Protocol inherits from ABC-related machinery,@runtime_checkableallows the__subclasshook__to behave accordingly for runtime isinstance and issubclass checks.NOTE: it’s still checking for consistent-with to check if it’s the same type.
caveat: performance/side-effect trade-offs
Careful if side effects or expensive operations if methods checked by
__subclasshook__have such costs
ready to use runtime checkables:
- check numeric convertibility:
typing.SupportsComplex1 2 3 4 5 6 7 8@runtime_checkable class SupportsComplex(Protocol): """An ABC with one abstract method __complex__.""" __slots__ = () @abstractmethod def __complex__(self) -> complex: passRECIPE: TO_HABIT: if you want to test whether an object c is a complex or SupportsComplex, you can provide a tuple of types as the second arg to
isinstance:isinstance(c, (complex, SupportsComplex))I had no idea this was a thing.
alternatively, we can use the Complex ABC within the numbers module.
1 2import numbers isinstance(c, numbers.Complex)type checkers don’t seem to recognise the ABCs within the
numbersabctyping.SupportsFloat
- check numeric convertibility:
“Duck Typing is Your Friend”
Often, ducktyping is the better approach for runtime type checking. WE just try the operations you need to do on the object.
So in the complex number situation, we have a few approaches we could take:
approach: runtime checkable static protocols
1 2 3 4if isinstance(o, (complex, SupportsComplex)): # do something that requires `o` to be convertible to complex else: raise TypeError('o must be convertible to complex')approach: goose typing using
numbers.ComplexABC1 2 3 4if isinstance(o, numbers.Complex): # do something with `o`, an instance of `Complex` else: raise TypeError('o must be an instance of Complex')approach:⭐️ duck typing and the EAFP (Easier to ask for forgiveness principle).
1 2 3 4try: c = complex(o) except TypeError as exc: raise TypeError('o must be convertible to complex') from exc
Limitations of Runtime Protocol Checks
@ runtime, type hints are ignored, so are
isinstanceandissubclasschecks against static protocolsproblem:
isinstance/issubclasschecks only look at the presence or absence of methods, without checking their signatures, much less their type annotations. That would have been too costly.this is because that type checking is not just a matter of checking whether the type of
xisT: it’s about determining that the type ofxis consistent-withT, which may be expensive.since they only do this, we can end up getting false positives on these type checks.
Supporting a Static Protocol
the point below is now deprecated. We can just run it as is.
using
from __future__ import annotationsallows typehints to be stored as strings, without being evaluated at import time, when functions are evaluated.so if we were to define the return type as the same class that we’re building, then we would have to use this import else it’s a use-before-definition error.
Designing a Static Protocol
trick: single-method protocols make static duck typing more useful and flexible
After a while, if you realise a more complete protocol is required, then you can combine two or more protocols to define a new one
example Here’s the protocol definition, it has a single function
1 2 3 4 5 6from typing import Protocol, runtime_checkable, Any @runtime_checkable class RandomPicker(Protocol): # NOTE the elipsis operator usage def pick(self) -> Any: ...
and here are some tests written for it
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25import random from typing import Any, Iterable, TYPE_CHECKING from randompick import RandomPicker # <1> class SimplePicker: # <2> def __init__(self, items: Iterable) -> None: self._items = list(items) random.shuffle(self._items) def pick(self) -> Any: # <3> return self._items.pop() def test_isinstance() -> None: # <4> popper: RandomPicker = SimplePicker([1]) # <5> assert isinstance(popper, RandomPicker) # <6> def test_item_type() -> None: # <7> items = [1, 2] popper = SimplePicker(items) item = popper.pick() assert item in items if TYPE_CHECKING: reveal_type(item) # <8> assert isinstance(item, int)- observations:
- not necessary to import the static protocol to define a class that implements it
Best Practices for Protocol Design
Align with Interface Segregation Principle: clients should not be forecd to depend on interfaces they don’t use. This gives the two following advice:
Narrow interfaces (often with a single method) are more useful.
Client Code Protocols: Good to define the protocol near the “client code” (where it’s being used) instead of a library.
Useful for extensibility and mock-testing.
Naming:
just name based on nouns that make sense and is minimalistic, nothing too fancy here.
clear concept \(\rightarrow\) plain names (Iterator, Container)
gives callback methods \(\rightarrow\)
SupportsXe.g. SupportsReadread/write attrs or getter/setter methods \(\rightarrow\)
HasXeg. HasItems
Create Minimalistic protocols and extend them later by creating derived protocols
Extending a Protocol
1 2 3 4 5 6from typing import Protocol, runtime_checkable from randompick import RandomPicker @runtime_checkable # <1> need to reimport, this won't get inherited class LoadableRandomPicker(RandomPicker, Protocol): # <2> have to define the Protocol def load(self, Iterable) -> None: ... # <3> OOP-like, only need to include the extended function, the super protocol's functions will be "inherited"instead of adding methods to the original protocol, it’s better to derive a new protocol from it.
keeps protocols minimal and aligns with Interface Segregation Principle – is really narrow interfaces here.
GOTCHA: not entirely the same as inheritance
the decorator
@runtime_checkableneeds to be re-appliedin the super class fields, we still need to add
Protocolalong with the rest of the protocols that we are extendingsimilar to inheritance: the functions being extended will be inherited by the derived class. We only need to indicate the new functions in the derived class.
The numbers ABCs and Numeric Protocols
Objective: we want to be able to support static type checking, and we want to be able to do this for external libraries that register their types as virtual subclasses of
numbersABCs.Current Approach: use the numeric protocols within
typingmodulenumbers.Numberhas no methods \(\implies\) numeric tower not useful for static type checking (it’s useful for runtime type checking though)
GOTCHA:
decimal.Decimalis not registered as a virtual subclass of numbers.Real. The reason is that, if you need the precision of Decimal in your program, then you want to be protected from accidental mixing of decimals with floating-point numbers that are less precise.because real (floats) are less precise and we don’t wanna interchange with them and have information losses.
Takeaways:
The numbers ABCs are fine for runtime type checking, but unsuitable for static typing.
The numeric static protocols SupportsComplex, SupportsFloat, etc. work well for static typing, but are unreliable for runtime type checking when complex numbers are involved.
Chapter Summary
contrasted dynamic protocols (that support duck typing) and static protocols (static duck typing)
for both, just need to implement necessary methods, no explicit registration needed
runtime effect:
Static protocol no runtime effect.
Dynamic protocol is runtime checkable. Aka when we
@runtime_checkablea static protocol, then it becomes a dynamic protocol.NOTE: this is a different contrast from Dynamic Duck Typing vs Static Duck typing
Dynamic Duck typing is the fail fast approach, where we “try and see it”
Static Duck Typing is the contract based use of Protocols
This is a subtle but often confusing distinction. Dynamic duck typing is Python’s inherent runtime behavior, while static duck typing reflects the formal contract via protocols at type-checking time
Python interpreter’s support for sequence and iterable dynamic protocols.
The interpreter uses special methods (
__getitem__,__iter__, etc.) dynamically to support iteration and membership tests even without explicit ABCs. This is a classic Python dynamic protocol idiom.monkey patching: adhering to the protocol @ runtime
defensive programming: detect structural types using
try/exceptand failing fast instead of explicit checks usingisinstanceorhasattrchecksIDIOM: This is a widely advocated Python idiom: “EAFP (Easier to Ask Forgiveness than Permission)”,
Goose typing:
creating and using ABCs
traditional subclassing and registration
__subclasshook__special method as a way for ABCs to support structural typing based on methods that fulfill interface define in the ABCs (without a direct registration)
Static protocols
is kind of the sttuctural interface in the python world.
@runtime_checkableactually leverages__subclasshoook__to support structural typing at runtime,though the best use of these protocols is with static type checkers.
type hints make structural typing more reliable.
design of static protocol:
- keep the narrow interface
- keep the definition near to usage
- extend it when you need to add functionality; in line with interface segregation principle.
Numbers ABCs and Numeric Protocols:
- numeric static protocols (e.g . SupportsFloats) has shortcomings
main message of this chapter is that we have four complementary ways of programming with interfaces in modern Python, each with different advantages and drawbacks.
You are likely to find suitable use cases for each typing scheme in any modern Python codebase of significant size.
Rejecting any one of these approaches will make your work as a Python programmer harder than it needs to be.
Possible Misconceptions
Adjacent Gotchas and Difficult Concepts You Might Misconstrue or Overlook
Runtime Checking Limits of Dynamic Protocols: Runtime `isinstance` checks with `@runtime_checkable` protocols are limited to checking presence of attributes/methods (using `hasattr` internally) and do not verify method signatures, argument types, or behavior correctness. This can give false positives if method signatures do not match—only static type checkers guarantee that.
`_subclasshook_` Complexity and Pitfalls: While powerful, implementing or overriding `_subclasshook_` can be tricky because it must handle all subclass checks gracefully and correctly, respecting caching and fallback behaviors to avoid subtle bugs. Excessive or ill-considered use may confuse the MRO and class hierarchy assumptions.
Difference Between ABC Registration and Protocol Conformance: Registering a class as a virtual subclass of an ABC influences `isinstance` checks but does not affect static type checking, whereas protocols influence static (and optionally runtime) interface conformance. Bridging these self-consistently in a codebase can sometimes be confusing.
Protocols and Inheritance vs Nominal Typing: Protocols enable structural typing, eschewing nominal inheritance for interface compatibility, but this can lead to subtle type checking behaviors where classes unintentionally conform just by method names, masking incorrect assumptions. This requires developers to design protocols and type hints thoughtfully.
Static Type Checking Requires Adoption of Tooling: The benefits of static protocols are realized only when using type checkers; pure runtime execution won’t enforce protocols unless combined with runtime checkable features. Adoption means introducing additional tooling and some learning curve for teams.
Monkey Patching Risks: While useful at runtime for dynamic protocol adherence, monkey patching comes with maintainability and debugging risks, especially when changing behaviors of widely used or critical classes. It can also mask design flaws if overused.
Difference Between Static and Runtime Failure Modes: Static protocols help catch interface noncompliance early, but dynamic duck typing detects mismatches only at runtime, often deeper within program flow, affecting error locality and debuggability.
Supporting References
- Real Python: Python Protocols: Leveraging Structural Subtyping (2024)
- The Turing Taco Tales: Static Duck Typing With Python’s Protocols (2024)
- Xebia: Protocols In Python: Why You Need Them (2022)
- PEP 544 – Protocols: Structural Subtyping (2017) (Historical and spec source)
- Python official docs on typing and Abstract Base Classes
Mental Model Summary for You as a Tech Leader
Your notes effectively capture the layered nature of interface programming in Python:
- At the lowest layer, Python runtime embraces dynamic duck typing: just try it and fail fast.
- To improve runtime type recognition and interoperability, Python uses ABCs with virtual subclassing (`register`) and `_subclasshook_` (“goose typing”), enabling `isinstance` semantics on structural grounds.
- To further support static analysis tooling, Python offers static protocols that check structure without inheritance, giving formal contracts for type checkers.
- Finally, runtime-checkable protocols bridge these worlds, allowing runtime `isinstance` checks on protocols designed primarily for static typing.
Together, these patterns compose a robust, hybrid approach adaptable to many scales and requirements—**rejecting any will unnecessarily limit your Python design flexibility and safety guarantees**
Further Reading
Chapter 14. Inheritance: For Better or for Worse
Focus areas for this chapter:
- The super() function
- The pitfalls of subclassing from built-in types
- Multiple inheritance and method resolution order
- Mixin classes
chapter introduces multiple inheritance for those who have never used it, and provides some guidance on how to cope with single or multiple inheritance if you must use it.
What’s New in This Chapter
The super() Function
example use cases
when a subclass overrides a method of a superclass
and we want to let the superclass method do its job then add more logic to it
when we let the superclasses do their part in init fns
LANG_LIMITATION / IDIOM: unlike java constructor that automatically calls the nullary super constructor, python doesn’t do this so we need to ALWAYS manually write this in.
1 2 3def __init__(self, a, b) : super().__init__(a, b) ... # more initialization codeit will work (but not recommended) for us to hardcode the base class and call that base class’s function.
Also won’t work well with the multiple inheritance stuff
Subclassing Built-In Types Is Tricky
Main takeaway:
Subclassing built-in types like dict or list or str directly is error-prone because the built-in methods mostly ignore user-defined overrides. Instead of subclassing the built-ins, derive your classes from the collections module using UserDict, UserList, and UserString, which are designed to be easily extended.
- it’s a flaw in method delegation within the C Language code of the builtin types (only affects classes derived directly from those types).
Major Caveat: bypassing behaviour
the code of the built-ins (written in C) usually does not call methods overridden by user-defined classes.
this applies for other dunder methods calling the overriden method.
using the overriding method directly is likely to work still.
This built-in behavior is a violation of a basic rule of object-oriented programming: the search for methods should always start from the class of the receiver (self), even when the call happens inside a method implemented in a superclass.
virtual vs nonvirtual methods
virtual: late-bound
non-virtual: bound at compile time
in python, every method is like latebound like a vritual method
builtins written in C seem to be nonvirtual by default (at least in CPython).
Multiple Inheritance and Method Resolution Order
guiding question:
if we do multiple inheritance and both super classes have overlapping method names, how to make reference to the correct super function from the subclass
\(\implies\) this is the diamond problem and we wanna see how python solves this
2 factors that determined the activation sequences:
MRO of the leaf class
Goes all the way from current class all the way to the
objectclassDefines the activation order
use of
super()in each methodDetermines whether a particular method will be activated.
So if the method calls super() then we move to the next class in the MRO order and execute that.
How?
It’s not necessarily a BFS, it uses the C3 Algorithm (not important to understand unless need to wrangle complex hierarchies.)
MRO accounts for inheritance graph. Amongst siblings, it’s determined by the subclass declaration.
e.g.
Leaf(B, A),Leaf(A, B)are two different subclass declarations.Cooperative Methods: methods that call
super()Cooperative methods enable cooperative multiple inheritance. These terms are intentional: in order to work, multiple inheritance in Python requires the active cooperation of the methods involved.
GOTCHA: cooperative methods can be a cause of subtle bugs. \(\implies\) That’s why it is recommended that every method
mof a nonroot class should callsuper().m().
A noncooperative method can be the cause of subtle bugs.
Manycoders reading Example 14-4 may expect that when method A.pong calls super.pong(), that will ultimately activate Root.pong. But if B.pong is activated before, it drops the ball.
That’s why it is recommended that every method m of a nonroot class should call super().m().
Mixin Classes
definition:
designed to be sub classed together with at least one other class as part of a multiple inheritance arrangement
won’t provide all the functionality of a concrete object
it’s supposed to be functionality mixins \(\implies\) customizes the behaviour of child or sibling classes.
so naturally will have some concrete methods implemented
are a convention that has no explicit language support in python/cpp
Mixins must appear first in the tuple of base classes in a class declaration
mixins typically depend on sibling classes that implements / inherits methods with the same signature
therefore, they must appear early in the MRO of a subclass that uses it
Case-Insensitive Mappings
See this beautiful example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140""" Short demos =========== ``UpperDict`` behaves like a case-insensitive mapping`:: # tag::UPPERDICT_DEMO[] >>> d = UpperDict([('a', 'letter A'), (2, 'digit two')]) >>> list(d.keys()) ['A', 2] >>> d['b'] = 'letter B' >>> 'b' in d True >>> d['a'], d.get('B') ('letter A', 'letter B') >>> list(d.keys()) ['A', 2, 'B'] # end::UPPERDICT_DEMO[] And ``UpperCounter`` is also case-insensitive:: # tag::UPPERCOUNTER_DEMO[] >>> c = UpperCounter('BaNanA') >>> c.most_common() [('A', 3), ('N', 2), ('B', 1)] # end::UPPERCOUNTER_DEMO[] Detailed tests ============== UpperDict uppercases all string keys. >>> d = UpperDict([('a', 'letter A'), ('B', 'letter B'), (2, 'digit two')]) Tests for item retrieval using `d[key]` notation:: >>> d['A'] 'letter A' >>> d['b'] 'letter B' >>> d[2] 'digit two' Tests for missing key:: >>> d['z'] Traceback (most recent call last): ... KeyError: 'Z' >>> d[99] Traceback (most recent call last): ... KeyError: 99 Tests for item retrieval using `d.get(key)` notation:: >>> d.get('a') 'letter A' >>> d.get('B') 'letter B' >>> d.get(2) 'digit two' >>> d.get('z', '(not found)') '(not found)' Tests for the `in` operator:: >>> ('a' in d, 'B' in d, 'z' in d) (True, True, False) Test for item assignment using lowercase key:: >>> d['c'] = 'letter C' >>> d['C'] 'letter C' Tests for update using a `dict` or a sequence of pairs:: >>> d.update({'D': 'letter D', 'e': 'letter E'}) >>> list(d.keys()) ['A', 'B', 2, 'C', 'D', 'E'] >>> d.update([('f', 'letter F'), ('G', 'letter G')]) >>> list(d.keys()) ['A', 'B', 2, 'C', 'D', 'E', 'F', 'G'] >>> d # doctest:+NORMALIZE_WHITESPACE {'A': 'letter A', 'B': 'letter B', 2: 'digit two', 'C': 'letter C', 'D': 'letter D', 'E': 'letter E', 'F': 'letter F', 'G': 'letter G'} UpperCounter uppercases all `str` keys. Test for initializer: keys are uppercased. >>> d = UpperCounter('AbracAdaBrA') >>> sorted(d.keys()) ['A', 'B', 'C', 'D', 'R'] Tests for count retrieval using `d[key]` notation:: >>> d['a'] 5 >>> d['z'] 0 """ # tag::UPPERCASE_MIXIN[] import collections def _upper(key): # <1> try: return key.upper() except AttributeError: return key class UpperCaseMixin: # <2> def __setitem__(self, key, item): super().__setitem__(_upper(key), item) def __getitem__(self, key): return super().__getitem__(_upper(key)) def get(self, key, default=None): return super().get(_upper(key), default) def __contains__(self, key): return super().__contains__(_upper(key)) # end::UPPERCASE_MIXIN[] # tag::UPPERDICT[] class UpperDict(UpperCaseMixin, collections.UserDict): # <1> pass class UpperCounter(UpperCaseMixin, collections.Counter): # <2> """Specialized 'Counter' that uppercases string keys""" # <3> # end::UPPERDICT[]
Multiple Inheritance in the Real World
Usage of multiple inheritance is not the norm in cpp or python really.
There are some known good use cases though.
ABCs Are Mixins Too
Just like Java, we support multiple inheritance of interfaces
for those ABCs that have concrete methods, they play 2 roles:
they play the role of an interface definition
they also play the role of mixin classes
- ThreadingMixIn and ForkingMixIn
Django Generic Views Mixins
the original generic views were functions so they were not extensible
have to start from scratch if we want to do something similar but not the same
Concrete subclasses of View are supposed to implement the handler methods, so why aren’t those methods part of the View interface? The reason: subclasses are free to implement just the handlers they want to support. A TemplateView is used only to display content, so it only implements get
reminder on why:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44Great question! What you’re touching on is a common and important aspect of Python’s interface and subclassing philosophy, especially in frameworks like Django (which uses **View** classes). ### In Python, do you have to implement *all* methods of an interface/abstract base class? **Short answer:** **Not necessarily.** Unlike some statically typed languages with strict interface contracts, Python’s interfaces and abstract base classes (ABCs) often allow (or even expect) subclasses to implement only the parts of the interface that make sense for them. ### Why? 1. **Python’s dynamic and flexible nature** - Python favors *duck typing* and optional implementation over strict enforcement. - ABCs in Python can define optional methods, or provide default no-op or generic implementations in base classes. 2. **Partial method implementation is common in frameworks** - Consider a `View` base class that defines many “handler methods” like `get()`, `post()`, `put()`, etc. - Concrete subclasses (e.g., `TemplateView`, `CreateView`) implement only the handlers relevant to the use case. - This lets you write minimal classes that do exactly what you need, without burden. 3. **Interface methods can be *optional* or *protocol-like*** - Instead of forcing every subclass to implement an entire interface, the base class or the framework’s machinery calls a method *if it exists*. - If the method is not implemented, either a default behavior occurs, or a runtime error only arises if the method is actually called. 4. **Explicit design: selective handler implementation** - The `TemplateView` subclass only implements the `get()` method because it only responds to HTTP GET requests. - If you called `post()` on a `TemplateView`, it might raise a `NotImplementedError` or return a “method not allowed” response. - This selective implementation is a common design pattern in web frameworks. ### Contrast to stricter languages or interfaces In languages like Java or C#, interfaces typically require **all** declared methods to be implemented. Python’s philosophy is more permissive: - **You can think of many interfaces or ABCs in Python as “soft” contracts.** - **You implement the “part you use.”** - This works well because Python’s runtime dispatch is dynamic: calls to methods that don’t exist will fail only if you exercise them. ### Summary - In Python, you **do not always have to implement every method** defined by an interface or abstract base class. - Interfaces or base classes often define *optional* or *selective* methods. - Subclasses implement only the methods relevant to their behavior. - This design promotes flexibility and simplicity in code, especially in toolkits like Django where views handle different HTTP methods. - Calling a method that’s not implemented typically leads to a runtime error only if that method is invoked. If you want, I can provide a small Python example illustrating this partial implementation pattern (e.g., a base class with several methods, and subclasses implementing only some of them). Would that be helpful?It does take some time to learn how to leverage class-based views and how to extend them to fulfill specific application needs, but I found that it was worthwhile to study them.
Value that the mixins give for Django:
They eliminate a lot of boilerplate code, make it easier to reuse solutions, and even improve team communication—for example, by defining standard names to templates, and to the variables passed to template contexts. Class-based views are Django views “on rails.”
Multiple Inheritance in Tkinter
the class heirarchy SHOULD NOT be very deep
usually it’s around 3 or 4 levels of concrete classes
GUI toolkits are where inheritance is most useful. The hierarchies can get really deep in them.
⭐️ Coping with Inheritance
These are the rules of thumb that we need to rely on.
We have to do so because there’s no general theory about inheritance that can guide us against creating incomprehensible, brittle designs.
Favor Object Composition over Class Inheritance
do composition and delegation
it can even replace the use of mixins and make behaviours available to different classes.
subclassing is a form of tight coupling and tall inheritance trees tend to be brittle.
Understand Why Inheritance Is Used in Each Case
Reasons FOR using inheritance:
creates a subtype, so it’s a is-a relationship best done with ABCs
avoids code duplication by reuse, Mixins are useful for this too
The realisation here is that to prevent code reuse, inheritance is only an implementation detail, we can do composition & delegation too. However, interface inheritance is separate matter.
Make Interfaces Explicit with ABCs
- Multiple inheritance of ABCs is not problematic.
- An ABC should subclass only abc.ABC or other ABCs.
- if a class is intended to define an interface, it should be an explicit ABC or a typing.Protocol subclass.
- Multiple inheritance of ABCs is not problematic.
Use Explicit Mixins for Code Reuse
- for reuse by multiple unrelated subclasses, without implying an “is-a” relationship,
- not to be instantatied
- since there’s no formal convention, try to Suffix the mixin name with
Mixin
Provide Aggregate Classes to Users
A class that is constructed primarily by inheriting from mixins and does not add its own structure or behavior is called an aggregate class.
group together combinations of ABCs or mixins
we can now just use the aggregate class without having to figure out in which order they should be declared to work as intended.
typically just has an empty body (with docstring / pass)
Subclass Only Classes Designed for Subclassing
some superclass methods may ignore the subclass overrides in unexpected ways.
\(\implies\) we should subclass only those that are intended to be extended.
how to check?
see the docs, if it’s a base class named, that hints at it
the docs will also indicate which of the methods are intended to be overridden.
see if the
@finaldecorator exists on the method (then it’s not intended for extension by overriding that method)
Avoid Subclassing from Concrete Classes
if you do this, any internal state within a concrete class might get corrupted
even if we coorperate by calling
super(), there’s still many ways bugs can be introducedIf you must use subclassing for code reuse, then the code intended for reuse should be in mixin methods of ABCs or in explicitly named mixin classes.
- Tkinter: The Good, the Bad, and the Ugly
Chapter Summary
Further Reading
Smalltalk has traits which are a language construct that serves the role that a mixin class does, while avoiding some of the issues with multiple inheritance.
Scala also has traits.
while working as an application developer, you find yourself building multilevel class hierarchies, it’s likely that one or more of the following applies:
You are reinventing the wheel. Go look for a framework or library that provides
components you can reuse in your application.
You are using a badly designed framework. Go look for an alternative.
You are overengineering. Remember the KISS principle.
You became bored coding applications and decided to start a new framework.
Congratulations and good luck!
Chapter 15. More About Type Hints
This is a new chapter in this edition of the book.
What’s New in This Chapter
Overloaded Signatures
it’s the signatures that we are overloading, not the function.
remember that python doesn’t allow function overloading!
implementation:
the actual function will ned no type hints, because the overloads will take care of it
can be implemented within the same module:
1 2 3 4 5 6 7 8 9 10 11 12 13 14import functools import operator from collections.abc import Iterable from typing import overload, Union, TypeVar T = TypeVar('T') S = TypeVar('S') # <1> for the second overload @overload def sum(it: Iterable[T]) -> Union[T, int]: ... # <2> @overload def sum(it: Iterable[T], /, start: S) -> Union[T, S]: ... # <3> def sum(it, /, start=0): # <4> return functools.reduce(operator.add, it, start)
Max Overload
pythonic apis are hard to annotate. this is because they strongly leverage the powerful dynamic features of python
this section demonstrates what it takes to annotate the
maxfunction.
Takeaways from Overloading max
- the expressiveness of annotation markings is very limited, compared to that of python
TypedDict
gotcha: remember for json objs we’ll need to do runtime checking. the
pydanticpackage is great for this.Static type checking is unable to prevent errors with code that is inherently dynamic, such as json.loads()
objective: we want to be able to define the structure of a container type (heterogeneous)
we should be able to provide a type specific to a key
TypedDicthave no runtime effect, only for static analysisGives:
Class-like syntax to annotate a dict with type hints for the value of each “field.”
A constructor that tells the type checker to expect a dict with the keys and values as specified.
1 2 3 4 5 6 7from typing import TypedDict class BookDict(TypedDict): isbn: str title: str authors: list[str] pagecount: intlooks very similar to a dataclass builder like a
typing.NamedTuplebut it isn’t.
@ runtime, the constructor just ends up creating a plain dict. No instance attributes, no init functions for the class, no method definitions.
none of the types will be enforced, “illegal” assignments can happen
Type Casting
type casting is for type checkers to get assisted by us
typing.cast()special function provides one way to handle type checking malfunctions or incorrect type hints in code we can’t fix.Casts are used to silence spurious type checker warnings and give the type checker a little help when it can’t quite understand what is going on.
Does absolutely nothing @ runtime
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23# tag::CAST[] from typing import cast def find_first_str(a: list[object]) -> str: index = next(i for i, x in enumerate(a) if isinstance(x, str)) # We only get here if there's at least one string return cast(str, a[index]) # end::CAST[] from typing import TYPE_CHECKING l1 = [10, 20, 'thirty', 40] if TYPE_CHECKING: reveal_type(l1) print(find_first_str(l1)) l2 = [0, ()] try: find_first_str(l2) except StopIteration as e: print(repr(e))too many uses of
castis likely a code-smell; Mypy is not that useless!why casts still have some purpose:
- the other workarounds are worse:
# type: ignoreis less informativeAnyis contagious, it will have cascading effects through type inference and undermine the type checker’s ability to detect errors in other parts of the code
- the other workarounds are worse:
Reading Type Hints at Runtime
within the
__annotations__attribute, it’s a dict that has the names and their typesthe return type has the key
"return"annotations are evaluated by the interpreter at import time, just like param default values
Problems with Annotations at Runtime
extra CPU and memory load when importing
types not yet defined are strings instead of actual types \(\implies\) the forward-reference-problem
we can use introspection helpers for this
e.g.
inspect.get_type_hintsthis is the recommended way to read type hints at runtime
Dealing with the Problem
- just keep an eye out on how to handle this, it’s likely to change from 3.10 onwards
Implementing a Generic Class
have to concretise the generic type by giving a type parameter:
machine = LottoBlower[int](range(1, 11))here’s a generic LottoBlower:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29import random from collections.abc import Iterable from typing import TypeVar, Generic from tombola import Tombola T = TypeVar('T') class LottoBlower(Tombola, Generic[T]): # <1> have to subclass Generic to declare the formal type params def __init__(self, items: Iterable[T]) -> None: # <2> self._balls = list[T](items) def load(self, items: Iterable[T]) -> None: # <3> self._balls.extend(items) def pick(self) -> T: # <4> try: position = random.randrange(len(self._balls)) except ValueError: raise LookupError('pick from empty LottoBlower') return self._balls.pop(position) def loaded(self) -> bool: # <5> return bool(self._balls) def inspect(self) -> tuple[T, ...]: # <6> return tuple(self._balls)
Basic Jargon for Generic Types
Generic type: type with 1 or more type vars
Formal Type Parameter: the generic type var used to define a generic type
Parameterized type: type declared with actual type parameters (resolved)
Actual type param: the actual types given as params when a param type is declared
Variance
useful to know if we want to support generic container types or provide callback-based APIs.
Practically speaking, most cases supported if we just support the invariant containers
the following sections use a concrete analogy to drive the point:
Imagine that a school cafeteria has a rule that only juice dispensers can be installed. General beverage dispensers are not allowed because they may serve sodas, which are banned by the school board.
code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95from typing import TypeVar, Generic class Beverage: """Any beverage.""" class Juice(Beverage): """Any fruit juice.""" class OrangeJuice(Juice): """Delicious juice from Brazilian oranges.""" T_co = TypeVar('T_co', covariant=True) class BeverageDispenser(Generic[T_co]): def __init__(self, beverage: T_co) -> None: self.beverage = beverage def dispense(self) -> T_co: return self.beverage class Garbage: """Any garbage.""" class Biodegradable(Garbage): """Biodegradable garbage.""" class Compostable(Biodegradable): """Compostable garbage.""" T_contra = TypeVar('T_contra', contravariant=True) class TrashCan(Generic[T_contra]): def put(self, trash: T_contra) -> None: """Store trash until dumped.""" class Cafeteria: def __init__( self, dispenser: BeverageDispenser[Juice], trash_can: TrashCan[Biodegradable], ): """Initialize...""" ################################################ exact types juice_dispenser = BeverageDispenser(Juice()) bio_can: TrashCan[Biodegradable] = TrashCan() arnold_hall = Cafeteria(juice_dispenser, bio_can) ################################################ covariant dispenser orange_juice_dispenser = BeverageDispenser(OrangeJuice()) arnold_hall = Cafeteria(orange_juice_dispenser, bio_can) ################################################ non-covariant dispenser beverage_dispenser = BeverageDispenser(Beverage()) ## Argument 1 to "Cafeteria" has ## incompatible type "BeverageDispenser[Beverage]" ## expected "BeverageDispenser[Juice]" # arnold_hall = Cafeteria(beverage_dispenser, bio_can) ################################################ contravariant trash trash_can: TrashCan[Garbage] = TrashCan() arnold_hall = Cafeteria(juice_dispenser, trash_can) ################################################ non-contravariant trash compost_can: TrashCan[Compostable] = TrashCan() ## Argument 2 to "Cafeteria" has ## incompatible type "TrashCan[Compostable]" ## expected "TrashCan[Biodegradable]" # arnold_hall = Cafeteria(juice_dispenser, compost_can)
An Invariant Dispenser
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54# tag::BEVERAGE_TYPES[] from typing import TypeVar, Generic class Beverage: # <1> we establish a type hierarchy """Any beverage.""" class Juice(Beverage): """Any fruit juice.""" class OrangeJuice(Juice): """Delicious juice from Brazilian oranges.""" T = TypeVar('T') # <2> simple typevar class BeverageDispenser(Generic[T]): # <3> Parameterised on the beverage type """A dispenser parameterized on the beverage type.""" def __init__(self, beverage: T) -> None: self.beverage = beverage def dispense(self) -> T: return self.beverage def install(dispenser: BeverageDispenser[Juice]) -> None: # <4> module-global function """Install a fruit juice dispenser.""" # end::BEVERAGE_TYPES[] ################################################ exact type # tag::INSTALL_JUICE_DISPENSER[] juice_dispenser = BeverageDispenser(Juice()) install(juice_dispenser) # end::INSTALL_JUICE_DISPENSER[] ################################################ variant dispenser # tag::INSTALL_BEVERAGE_DISPENSER[] beverage_dispenser = BeverageDispenser(Beverage()) install(beverage_dispenser) ## mypy: Argument 1 to "install" has ## incompatible type "BeverageDispenser[Beverage]" ## expected "BeverageDispenser[Juice]" # end::INSTALL_BEVERAGE_DISPENSER[] ################################################ variant dispenser # tag::INSTALL_ORANGE_JUICE_DISPENSER[] orange_juice_dispenser = BeverageDispenser(OrangeJuice()) install(orange_juice_dispenser) ## mypy: Argument 1 to "install" has ## incompatible type "BeverageDispenser[OrangeJuice]" ## expected "BeverageDispenser[Juice]" # end::INSTALL_ORANGE_JUICE_DISPENSER[]BeverageDispenser(Generic[T])is invariant whenBeverageDispenser[OrangeJuice]is not compatible withBeverageDispenser[Juice]— despite the fact thatOrangeJuiceis a subtype-ofJuice.It depends on how we have defined the typevar
In this case, the function was defined with an actual type var:
def install(dispenser: BeverageDispenser[Juice]) -> None:
A Covariant Dispenser
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51from typing import TypeVar, Generic class Beverage: """Any beverage.""" class Juice(Beverage): """Any fruit juice.""" class OrangeJuice(Juice): """Delicious juice from Brazilian oranges.""" # tag::BEVERAGE_TYPES[] T_co = TypeVar('T_co', covariant=True) # <1> convention to suffix it like that. class BeverageDispenser(Generic[T_co]): # <2> we use the typevar as the param for the generic class def __init__(self, beverage: T_co) -> None: self.beverage = beverage def dispense(self) -> T_co: return self.beverage def install(dispenser: BeverageDispenser[Juice]) -> None: # <3> """Install a fruit juice dispenser.""" # end::BEVERAGE_TYPES[] ################################################ covariant dispenser # tag::INSTALL_JUICE_DISPENSERS[] # both Juice and OrangeJuice aer valid in a covariant BeverageDispenser: juice_dispenser = BeverageDispenser(Juice()) install(juice_dispenser) orange_juice_dispenser = BeverageDispenser(OrangeJuice()) install(orange_juice_dispenser) # end::INSTALL_JUICE_DISPENSERS[] ################################################ more general dispenser not acceptable # tag::INSTALL_BEVERAGE_DISPENSER[] beverage_dispenser = BeverageDispenser(Beverage()) install(beverage_dispenser) ## mypy: Argument 1 to "install" has ## incompatible type "BeverageDispenser[Beverage]" ## expected "BeverageDispenser[Juice]" # end::INSTALL_BEVERAGE_DISPENSER[]covariance: the subtype relationship of the parameterized dispensers varies in the same direction as the subtype relationship of the type parameters.
two type of types: A: type vars B: dispenser type vars
The question is whether the we allow the variance in the same direction (co-variant).
Supports Generic type and ALSO its subtypes
Implementation notes:
- by convention, the typevar should be suffixed with
_co - just need to set
covariant=Truewhen we declare the typevar
- by convention, the typevar should be suffixed with
A Contravariant Trash Can
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44# tag::TRASH_TYPES[] from typing import TypeVar, Generic class Refuse: # <1> """Any refuse.""" class Biodegradable(Refuse): """Biodegradable refuse.""" class Compostable(Biodegradable): """Compostable refuse.""" T_contra = TypeVar('T_contra', contravariant=True) # <2> class TrashCan(Generic[T_contra]): # <3> def put(self, refuse: T_contra) -> None: """Store trash until dumped.""" def deploy(trash_can: TrashCan[Biodegradable]): """Deploy a trash can for biodegradable refuse.""" # end::TRASH_TYPES[] ################################################ contravariant trash can # tag::DEPLOY_TRASH_CANS[] bio_can: TrashCan[Biodegradable] = TrashCan() deploy(bio_can) trash_can: TrashCan[Refuse] = TrashCan() deploy(trash_can) # end::DEPLOY_TRASH_CANS[] ################################################ more specific trash can # tag::DEPLOY_NOT_VALID[] compost_can: TrashCan[Compostable] = TrashCan() deploy(compost_can) ## mypy: Argument 1 to "deploy" has ## incompatible type "TrashCan[Compostable]" ## expected "TrashCan[Biodegradable]" # end::DEPLOY_NOT_VALID[]implementation:
- use
_contrasuffix for the contravariant typevar
- use
in our example,
TrashCanis contravariant on the type of refuse.
Variance Review
Invariant Types
if L (generic type) is invariant, then L[A] (parameterised type) is not a supertype or a subtype of L[B]
This is regardless of the relationships between A and B (the actual types)
examples: mutable collections in python are invariant so
list[int]is not consistent-withlist[floatand vice-versaif a formal type param (T) appears in the type hints of the method args AS WELL AS the return types, then the parameter must be invariant
this ensures type safety
by default, TypeVar creates invariant types
Covariant Types
nomenclature:
X :> Y: means that X is supertype of OR same as Y and vice versa
Covariant generic types follow the subtype relationship of the actual type parameters.
if
A :> B(type B is a subclass of type A) and a we consider type C (generic type). Iff C is contravariant thenC[A] :> C[B].Here, A and B are the actual type params.
examples:
Frozen set
float :> intandfrozenset[float] :> frozenset[int]SAME DIRECTION
Iterators
Any code expecting an
abc.Iterator[float]yielding floats can safely use anabc.Iterator[int]yielding integers.
Callable types are covariant on the return type
this is so that the subclass will also work
Contravariant Types
A :> B, a generic typeKis contravariant ifK[A] <: K[B]reverses the subtype relationship of the actual type parameters (opposite direction)
A contravariant container is usually a write-only data structure, aka a sink
Callable[[ParamType, …], ReturnType]is contravariant on the parameter types, but covariant on the ReturnTypeexamples:
Refuse :> BiodegradablesoTrashCan[Refuse] <: TrashCan[Biodegradable]for callbacks,
contravariant formal parameter defines the type of args used to invoke / send data to this object \(\implies\) the callback object is therefore the sink
covariant formal params define the types of outputs produced by the object (yield type or return type) \(\implies\) callback object acts as a source the gives outputs.
Rules of Thumb
producing:
If a formal type parameter defines a type for data that comes out of the object, it can be covariant. So we can produce more specific (narrower) results than strictly required.
consuming:
If a formal type parameter defines a type for data that goes into the object after its initial construction, it can be contravariant. So we can accept/consume more specific (narrower) results than strictly required.
consuming == producing \(\implies\) invariant
If a formal type parameter defines a type for data that comes out of the object and the same parameter defines a type for data that goes into the object, it must be invariant.
To err on the safe side, make formal type parameters invariant.
Callbacks are special because they accept inputs and return output
- Python’s typing system with Callable is directly designed to reflect this.
See this elaboration:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120You're absolutely on the right track! **Callbacks** (like callables or function-type objects) in Python's typing system **are indeed special** because **they play both roles:** - They **accept inputs** (they are a "sink" for arguments), and - They **return outputs** (they are a "source" for results) This duality is exactly why variance in callables is *split*: - **Parameter types are contravariant** (inputs; the callback can accept _more general_ arguments than strictly required) - **Return types are covariant** (outputs; the callback can produce _more specific_ results than strictly required) Let me show this with an example. --- ### Example: Callbacks, Variance, and Typing Imagine you define this type: ```python from typing import Callable # A callback that takes a Biodegradable and returns a Juice CallbackType = Callable[[Biodegradable], Juice] ``` This means: - You need something that can accept a `Biodegradable` (or *any* base/parent of Biodegradable, i.e., `Refuse`) - And it must return a `Juice` (or any *subtype*, e.g., `OrangeJuice`) #### Function Matching the Signature ```python def process_refuse(refuse: Refuse) -> OrangeJuice: """Accepts any refuse, returns orange juice (a subtype of Juice).""" return OrangeJuice() ``` This function: - Accepts a `Refuse` (broader than just `Biodegradable`) ⇒ **contravariant** - Returns an `OrangeJuice` (narrower than `Juice`) ⇒ **covariant** **We can use process_refuse wherever CallbackType is required, thanks to variance:** ```python def handle_event(cb: CallbackType) -> None: refuse = Biodegradable() juice = cb(refuse) print(f"{juice!r} dispensed.") handle_event(process_refuse) # This typechecks! ``` --- ### Why? - **Contravariant parameter**: A function that can handle any `Refuse` is good enough anywhere that needs just `Biodegradable` — it won't ever receive a non-biodegradable! - **Covariant return**: If someone expects a `Juice`, it's fine to give them something more specific (like `OrangeJuice`). --- ## Summary Table | Callback signature | Description | Variance | |----------------------------------------- |---------------------------|-------------- | | `Callable[[ParamType], ReturnType]` | callback taking input(s), returning output | Parameter: **Contravariant**Return: **Covariant** | - Think of input parameters as arguments being "sent in" (*sink*, contravariant) - Think of return values as outputs "sent out" (*source*, covariant) --- ## Intuitive Analogy - **Input arguments**: You want callbacks that can accept *at least* what you have (so a broader parameter is better). - **Output/Return**: You want callbacks to promise to return *at least* what you asked for (so a narrower/specific return type is better). --- ### Expanded Example #### Class hierarchy ```python class Refuse: pass class Biodegradable(Refuse): pass class Compostable(Biodegradable): pass class Beverage: pass class Juice(Beverage): pass class OrangeJuice(Juice): pass ``` #### Callbacks ```python from typing import Callable # Expected callback: takes a Biodegradable, returns a Juice CallbackType = Callable[[Biodegradable], Juice] def cb1(arg: Refuse) -> OrangeJuice: ... # Accepts any Refuse, returns a specific Juice def cb2(arg: Compostable) -> Beverage: ... # Accepts only Compostable, returns a general Beverage def cb3(arg: Biodegradable) -> Juice: ... # Accepts Biodegradable, returns Juice f: CallbackType f = cb1 # OK! Wider input, narrower output f = cb2 # mypy: error (input too narrow, output too broad) f = cb3 # OK! exact types ``` --- ## Conclusion So your summary is **correct**: - **Callbacks _are both_ a sink (inputs) and a source (outputs)**. - **Input arguments:** Contravariant (wider is OK) - **Return type:** Covariant (narrower is OK) **Python’s typing system with Callable is directly designed to reflect this.**
Implementing a Generic Static Protocol
There’s some examples here for reference, nothing special though
Chapter Summary
We have covered:
type
@overload, including for the max functiontyping.TypedDict, which is not a class builder,this is useful for defining the type of a dict (keys and values) when a dict is used as a record, often with the handling of JSON data
can give a false sense of security though, since it has no runtime effect
typing.castas a way to handle some issues with type checkers. If overdone, it’s a code smell.Runtime type hint access including name-forwarding approaches
GENERICS!!
back to typed world
Generic Static Protocol
- allows us to be specific in the original protocol form
Further Reading
remember to keep up with Mypy’s docs because the official python docs on typing might lag because of the rate at which new features for typing are introduced.
“Covariance or contravariance is not a property of a type variable, but a property of a generic class defined using this variable.”
\(\implies\) this is why I was finding it so mindboggling when the topic of variance in generics is not new to me .
In python, the typevar is what the notion of co/contra-variance is bound to. This happened because the authors worked under the severe self-imposed constraint that type hints should be supported without making any change to the interpreter.
that’s why the variance is tied to the TypeVar declaration
that’s why the
[]is used instead of<>for defining the type param
Chapter 16. Operator Overloading
There’s a value in allowing infix operators to handle any arbitrary type (not just primitive types):
- readable code that allows the non-primitive types to help with exactness of operations
This is why operator overloading is important.
Objectives:
- how to overload properly
- How an infix operator method should signal it cannot handle an operand
- Using duck typing or goose typing to deal with operands of various types
- The special behaviour of the rich comparison operators (e.g.,
=, >, <, etc.) - The default handling of augmented assignment operators such as
+=, and how to overload them
What’s New in This Chapter
Operator Overloading 101
objective: interoperability of unary/infix/other operators with user defined objects
other operators includes
(),.,[]in pythonLANG_LIMITATIONS: Python Limitations on operator overloading (to protect us):
can’t change the meaning of the operators for built-in types
can’t create new operators, only can overload existing ones
some operators can’t be overloaded:
is,and,or,notthe bitwise versions can be overloaded though (so
$, |, ~)
Unary Operators
random notes on these:
- usually
x =+x= but not in some cases - bitwise NOT is also
~x =-(x + 1)= if x is 2, then~x =-3=
- usually
easy to implement the appropriate unary function, just make the function pure and immutable
if the receiver itself is immutable, then we can just return self.
when is
xand+xnot equal?e.g. when precision matters. E.g. when using
Decimalyou can setxbased on a particular arithmetic precision, then change the precision and computex=+xand because the precisions will be different we will get back aFalsee.g. when using
collections.CounterTRICK: Unary
+produces a new Counter without zeroed or negative tallies. So we can use it to copy (and remove the negatives / zeros).
Overloading + for Vector Addition
typically, sequences should support the
+operator for concatenation and*for repetition.when we have operands of diff types, we try to look for add or
r_addand take a best-effort approach:
support operations involving objects of different types, Python implements a special dispatching mechanism for the infix operator special methods:
If
ahas__add__, calla.__add__(b)and return result unless it’sNotImplemented.If a doesn’t have
__add__, or calling it returnsNotImplemented, check ifbhas__radd__, then callb.__radd__(a)and return result unless it’sNotImplemented.If
bdoesn’t have__radd__, or calling it returnsNotImplemented, raiseTypeErrorwith an unsupported operand types message.
GOTCHA:
NotImplementedis a singleton, not the same asNotImpelmentedErrorDo not confuse NotImplemented with NotImplementedError. The first, NotImplemented, is a special singleton value that an infix operator special method should return to tell the interpreter it cannot handle a given operand. In contrast, NotImplementedError is an exception that stub methods in abstract classes may raise to warn that subclasses must implement them.
note that if there’s any error, an overloaded operator function should return
NotImplementedinstead of other errors likeTypeError.this is so that the dispatch mechanism is not aborted prematurely
Overloading * for Scalar Multiplication
Using @ as an Infix Operator
- it’s been used for matrix multiplication, has both reflected version and an in-place version
- this is a useful goose typing example as well, both the ABCs implement the
__subclasshook__methods so we don’t need explicit subclassing / registration
Wrapping-Up Arithmetic Operators
Rich Comparison Operators
- differs from the arithmetic operators in these ways:
- same set of methods is used in forward and reverse operator calls (with the arguments changed as expected)
- for
!=and==, ifNotImplementedthen fallback toid()checks.
Augmented Assignment Operators
- for immutable objects, the augment assignment operators are just syntactic sugar for the expanded version, that’s why they return new objects
- for mutable objects, depends on whether we implemented the dunder methods or not
- Very important: augmented assignment special methods of mutable objects must return self. That’s what users expect.
- IDIOM: In general, if a forward infix operator method (e.g., mul) is
designed to work only with operands of the same type as self, it’s useless to implement the corresponding reverse method (e.g.,=_rmul_=) because that, by definition, will only be invoked when dealing with an operand of a different type.
Chapter Summary
when handling mixed operands, we have 2 choices:
use duck typing:
this is useful and flexible but the error messages may be less useful or even misleading
use goose typing:
this is useful as a compromise between flexibility and safety beacuse existing / future user-defined types can be declared as actual or virtual subclasses of an ABC
Also if ABC implements the
__subclasshook__then it’s even more convenient because no need explicit subclassing or registration.
the in place operator is usually more flexible than its infix operator in terms of type strictness.
Further Reading
Part IV. Control Flow
Chapter 17. Iterators, Generators, and Classic Coroutines
iterator design pattern is builtin to python.
Every standard collection in Python is iterable. An iterable is an object that provides an iterator,
What’s New in This Chapter
A Sequence of Words
Why Sequences Are Iterable: The iter Function
the dispatch flow is like so:
- need to iterate on
x\(\implies\) callsiter(x)builtin - try
__iter__implementation - elif try
__getitem__, if present then fetch items by index, start from 0-index - fail and raise
TypeError
- need to iterate on
all Python sequences are iterable:
by definition, they all implement
__getitem__(especially for backward compatibility).std sequences also implement
__iter__and custom ones should also have thisthis is an extreme form of duck typing:
an object is considered iterable not only when it implements the special method
__iter__, but also when it implements__getitem__goose typing approach, it’s just checking the existence of
__iter__method. No registration needed becauseabc.Iterableimpelements the__subclasshook__the ducktyped approach to typechecking for iterable is better than the goose-typing approach
Using iter with a Callable
when used with a callable, second arg is a sentinel value for detecting the stop iteration.
sentinel value will never really be yielded because that’s the sentinel.
iterators may get exhausted.
the callable given to
iter()MUST NOT require arguments. If necessary, remember to convert it to a partial function (where the arguments are pre-binded) so that it’s effectively a nullary function.
Iterables Versus Iterators
python obtains iterators from iterables
any obj for which the
iter()builtin can get an iterator is an iterable- either gets it from
__iter__or indirectly from__getitem__
- either gets it from
an iterator raises a
StopIterationwhen there are no further items. there’s no way to check for empty other than this, and there’s no way to reset an iterator other than to create it again.__issubclasshook__implementation withinIterator:1 2 3 4 5@classmethod def __subclasshook__(cls, C): if cls is Iterator: return _check_methods(C, '__iter__', '__next__') return NotImplementedthe
_check_methodsis provided by theabcmoduleit traverses the MRO for the class and checks if methods implemented or not
MISCONCEPTION: virtual subclassing doesn’t ONLY need to be explicitly registered. The use of
__issubclasshook__that relies on__checkmethods__is an example of implicit virtual subclassingeasiest way to typecheck for
iteratoris to do goosetypecheck:isinstance(x, abc,Iterator)
Sentence Classes with iter
- iterators are supposed to implement both
__next__and__iter__. the iter dunder method is so that they work well in places that expect and iterable.
Sentence Take #2: A Classic Iterator
- this is just a didatic example, uses a custom class that keeps track of a cursor for the next idx to present value from and if out of bounds, marks as stop iter.
Don’t Make the Iterable an Iterator for Itself
iterators are also iterable (because they have the
__iter__method that returnsself) but iterables are NOT iterators (they can create iterators)common source of error is to confuse the two.
common antipattern:
to implement
__next__for an iterable so that an iterable is also an iterator over itself.so a proper implementation of the pattern requires each call to
iter(my_iterable)to create a new, independent, iterator.
Sentence Take #3: A Generator Function
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28""" Sentence: iterate over words using a generator function """ # tag::SENTENCE_GEN[] import re import reprlib RE_WORD = re.compile(r'\w+') class Sentence: def __init__(self, text): self.text = text self.words = RE_WORD.findall(text) def __repr__(self): return 'Sentence(%s)' % reprlib.repr(self.text) def __iter__(self): for word in self.words: # <1> yield word # <2> # <3> # done! <4> # end::SENTENCE_GEN[]pythonic way is to use a generator instead of a custom class that acts as the iterator
here,
__iter__is a generator functiona generator function doesn’t raise
StopIteration, it just exits when it gets exhausted
How a Generator Works
a generator function is a generator factory
it is a function, when called, returns a generator object
generator function generates generator objects
generator function and generator objects are not the same
not necessary to have just a single
yield(typically within a loop construct), we can have as manyyields as we like in our generator functionon each
next()applied to the generator object, we’ll just end up continuing the control flow until the nextyieldstatementthe fallthrough at the end of a generator function is for the generator object to raise
StopIterationthe consumer of the generator object may handle things cleanly
When the generator function runs to the end, the generator object raises
StopIteration. The for loop machinery catches that exception, and the loop terminates cleanly.Language:
functions “return” values, generators “yield” values
generator functions return generator objects
Lazy Sentences
Sentence Take #4: Lazy Generator
we know that the
findallmethod for the regex was being eager so we use the lazy version:re.finditer. This returns a generator yieldingre.MatchObjectinstances on demand \(\implies\) it’s not lazy.finditerbuilds an iterator over the matches ofRE_WORDonself.text, yieldingMatchObjectinstances.code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24""" Sentence: iterate over words using a generator function """ # tag::SENTENCE_GEN2[] import re import reprlib RE_WORD = re.compile(r'\w+') class Sentence: def __init__(self, text): self.text = text # <1> def __repr__(self): return f'Sentence({reprlib.repr(self.text)})' def __iter__(self): for match in RE_WORD.finditer(self.text): # <2> yield match.group() # <3> # end::SENTENCE_GEN2[]
Sentence Take #5: Lazy Generator Expression
intent here is to replace generator functions with generator expressions. should be seen as syntactic sugar.
we can write generator expressions using generator objects that do not directly consume the generator objects, thereby preserving the lazy behaviour
code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44""" Sentence: iterate over words using a generator expression """ # tag::SENTENCE_GENEXP[] import re import reprlib RE_WORD = re.compile(r'\w+') class Sentence: def __init__(self, text): self.text = text def __repr__(self): return f'Sentence({reprlib.repr(self.text)})' def __iter__(self): return (match.group() for match in RE_WORD.finditer(self.text)) # end::SENTENCE_GENEXP[] def main(): import sys import warnings try: filename = sys.argv[1] word_number = int(sys.argv[2]) except (IndexError, ValueError): print(f'Usage: {sys.argv[0]} <file-name> <word-number>') sys.exit(2) # command line usage error with open(filename, 'rt', encoding='utf-8') as text_file: s = Sentence(text_file.read()) for n, word in enumerate(s, 1): if n == word_number: print(word) break else: warnings.warn(f'last word is #{n}, {word!r}') if __name__ == '__main__': main()the
__iter__method here is no longer a generator function (since it has no yield), it uses a generator expression to build a generator object and returns itsame outcome though, both cases return a generator object
When to Use Generator Expressions
should be seen as a syntactic shortcut to create a generator without defining and calling a function.
syntax stuff:
- if we’re passing in a genexpr as the only argument to a function, we can omit the surrounding
()and it will work. This doesn’t work if there’s more than one argument that we’re supplying though.
- if we’re passing in a genexpr as the only argument to a function, we can omit the surrounding
compared with generator functions:
generator functions can be seen as coroutines even, supports complex logic with multiple statements
should use generator functions when the genexpr looks too complex.
Contrasting Iterators and Generators
iterators:
- anything implementing
__next__method - produce data for client code consumption:
- consumed via drivers such as
forloops - consumed via the explicit calling of
next(it)
- consumed via drivers such as
- practicall, most iterators in python are Generators.
- anything implementing
Generators
an iterator that the python compiler builds
ways to create a generator:
implement a generator function, with a
yieldkeyword. this is a factory of generator objectsuse a generator expression to build a generator object
it’s the generator objects that provide
__next__so that they are iterators. The generators (generator functions) don’t need to implement__next__we can have async generators
An Arithmetic Progression Generator
TRICK: we can see the
rangefunction as a built in that generates a bounded arithmetic progression of integers!TRICK: python 3 doesn’t have an explicit type coersion method, but we can work around this:
1 2 3 4 5 6 7 8 9 10 11def __iter__(self): result_type = type(self.begin + self.step) # NOTE: by keeping the target result type, we can then coerce it like so: result = result_type(self.begin) forever = self.end is None index = 0 while forever or result < self.end: yield result index += 1 result = self.begin + self.step * indexif the whole point of a class is to build a generator by implementing
__iter__, we can replace the class with a generator function. A generator function is, after all, a generator factory.code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31""" Arithmetic progression generator function:: >>> ap = aritprog_gen(1, .5, 3) >>> list(ap) [1.0, 1.5, 2.0, 2.5] >>> ap = aritprog_gen(0, 1/3, 1) >>> list(ap) [0.0, 0.3333333333333333, 0.6666666666666666] >>> from fractions import Fraction >>> ap = aritprog_gen(0, Fraction(1, 3), 1) >>> list(ap) [Fraction(0, 1), Fraction(1, 3), Fraction(2, 3)] >>> from decimal import Decimal >>> ap = aritprog_gen(0, Decimal('.1'), .3) >>> list(ap) [Decimal('0'), Decimal('0.1'), Decimal('0.2')] """ # tag::ARITPROG_GENFUNC[] def aritprog_gen(begin, step, end=None): result = type(begin + step)(begin) forever = end is None index = 0 while forever or result < end: yield result index += 1 result = begin + step * index # end::ARITPROG_GENFUNC[]
Arithmetic Progression with itertools
ready to use generators in itertools, which we can combine
some useful ones:
itertools.countis infinite generator, accepts astartand astepitertools.takewhilefunction: it returns a generator that consumes another generator and stops when a given predicate evaluates toFalseexample:
gen = itertools.takewhile(lambda n: n < 3, itertools.count(1, .5))
code:
1 2 3 4 5 6 7 8 9 10# tag::ARITPROG_ITERTOOLS[] import itertools def aritprog_gen(begin, step, end=None): first = type(begin + step)(begin) ap_gen = itertools.count(first, step) if end is None: return ap_gen return itertools.takewhile(lambda n: n < end, ap_gen) # end::ARITPROG_ITERTOOLS[]NOTE:
aritprog_genis not a generator function because it has noyieldin its body, it still returns ageneratorthough, like a generator function does.1Nonewhen implementing generators, know what is available in the standard library, otherwise there’s a good chance you’ll reinvent the wheel.
Generator Functions in the Standard Library
This section focuses on general-purpose functions that take arbitrary iterables as arguments and return generators that yield selected, computed, or rearranged items.
Some groups of standard generators:
Filtering generator functions:
they yield a subset of items produced by the input iterable, without changing the items themselves.
Mapping generators: (in the context of map functions, not map objects)
they yield items computed from each individual item in the input iterable—or iterables,
- starmap is cool. it does an unpacking from an iterator that yields tuples e.g. this gives us a running average:
list(itertools.starmap(lambda a, b: b / a, enumerate(itertools.accumulate(sample), 1)))1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75The **`itertools.starmap` function** in Python is a specialized iterator that applies a given function to elements from an iterable, where each element is itself an iterable (typically a tuple) and is unpacked as arguments to the function. ### Detailed Explanation - `starmap(function, iterable)` is similar to the built-in `map()` function, but while `map()` passes each element as a whole argument to the function, **`starmap` unpacks each element (tuple) as positional arguments to the function**. - This means if you have an iterable of tuples like `[(a1, b1), (a2, b2), ...]`, `starmap` calls `function(a1, b1)`, `function(a2, b2)`, etc. - It returns an iterator that yields the results of these function calls lazily, i.e., items are computed only as you iterate. ### Mental Model - Think of `starmap` as a clever iterator transform that "unzips" or unpacks arguments for you when you have multiple parameters. - It is particularly useful when working with functions or operations that expect multiple positional arguments but you have your data already grouped as tuples in your iterable. - This differs from `map`, which treats each element as a single argument. ### Prototype of `starmap` behavior (simplified) ```python def starmap(function, iterable): for args in iterable: yield function(*args) # unpack each tuple as arguments ``` ### Practical Example ```python from itertools import starmap def multiply(x, y): return x * y pairs = [(2, 3), (4, 5), (6, 7)] result = starmap(multiply, pairs) print(list(result)) # Output: [6, 20, 42] ``` In this example, `multiply` requires two arguments; `pairs` contains tuples with two elements each, and `starmap` calls `multiply` with unpacked tuple elements. ### Comparison with `map` - Using `map(pow, [(2, 3), (4, 5)])` would fail because `pow` expects two separate arguments, but `map` passes the entire tuple as one argument. - Using `starmap(pow, [(2, 3), (4, 5)])` works because it unpacks the tuples as separate arguments automatically. ### Use Cases Beyond Simple Functions - It is often leveraged to apply functions like `pow`, arithmetic operators, or user-defined functions that take multiple arguments. - Useful in multiprocessing scenarios (e.g., `multiprocessing.Pool.starmap`) for applying functions with multiple inputs concurrently. ### Summary Table | Aspect | Description | |---------------------------|---------------------------------------------------------------------| | Function signature | `itertools.starmap(function, iterable_of_arg_tuples)` | | Functional behavior | Applies function as `function(*args)` for each tuple in iterable | | Returns | An iterator yielding results lazily | | Difference from `map` | `map` passes each element as-is; `starmap` unpacks tuple arguments | | Use case | Applying multi-argument functions over an iterable of argument tuples| ### References - Python official docs for itertools: `starmap` applies a function to unpacked arguments from tuples in an iterable. - Tutorialspoint, GeeksforGeeks, and Educative.io provide practical examples demonstrating the use and difference from `map`. - Multiprocessing's `Pool.starmap()` uses exactly the same concept to map multi-argument functions in parallel. This understanding helps senior engineers grasp how `starmap` elegantly bridges the gap between iterable data structures and multi-argument function applications in Python’s iterator toolkit. [1] https://www.tutorialspoint.com/python/python_itertools_starmap_function.htm [2] https://www.geeksforgeeks.org/python/python-itertools-starmap/ [3] https://www.educative.io/answers/what-is-the-itertoolsstarmap-method-in-python [4] https://www.mybluelinux.com/python-map-and-starmap-functions/ [5] https://superfastpython.com/multiprocessing-pool-starmap/ [6] https://docs.python.org/3/library/multiprocessing.html [7] https://indhumathychelliah.com/2020/09/14/exploring-map-vs-starmap-in-python/ [8] https://stackoverflow.com/questions/56672348/applying-the-pool-starmap-function-with-multiple-arguments-on-a-dict-which-are [9] https://www.youtube.com/watch?v=aUUJRF6Zako
- starmap is cool. it does an unpacking from an iterator that yields tuples e.g. this gives us a running average:
Merging Generators: yield items from multiple input iterables
chain.from_iterable: It’s almost like flattening.
Generator functions that expand each input into multiple output items:
pairwiseis interesting: each item in the input, pairwise yields a 2-tuple with that item and the next — if there is a next item.list(itertools.pairwise(range(7)))
TRICK: Combinatorics Generators see the elaboration here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131The **combinatorics generators in the `itertools` module** of Python are a suite of powerful, memory-efficient iterator-based functions designed to generate combinatorial collections such as permutations, combinations, and Cartesian products systematically without building them fully in memory. These functions are foundational for algorithmic tasks involving combinatorial enumeration, sampling, or search. Here is a detailed outline tailored for a senior engineer who values mental models, rigor, and first principles: *** ### 1. Overview of Combinatorics Generators in `itertools` Python’s `itertools` module offers **four primary combinatoric iterators** that generate combinatorial constructs lazily: | Iterator Name | Purpose | Key Characteristics | |-------------------------------|---------------------------------------------|----------------------------------------------------------| | `product()` | Cartesian product of input iterables | Generates tuples combining every element with every other (with optional repetition) | | `permutations()` | All possible orderings (permutations) | Generates all possible ordered arrangements of a specified length | | `combinations()` | Combinations without replacement | Generates all possible selections of a specified length without regard to order | | `combinations_with_replacement()` | Combinations allowing repeated elements | Like combinations but allows repeated elements in output | *** ### 2. Detailed Description with Mental Models #### a. `itertools.product(*iterables, repeat=1)` - **Conceptual model:** The Cartesian product can be thought of as the "all pairs/all tuples" construction, where you combine every element of iterable 1 with every element of iterable 2, and so forth. - **Use case:** Explores all possible selections when repetition and order matter. - **Implementation detail:** Produces tuples where each position corresponds to one iterable element. The `repeat` argument simulates self cartesian products. - **Example:** ```python from itertools import product list(product([1, 2], repeat=2)) # Output: [(1, 1), (1, 2), (2, 1), (2, 2)] ``` - **Scaling note:** The output size grows multiplicatively — caution with large inputs. #### b. `itertools.permutations(iterable, r=None)` - **Conceptual model:** All possible orderings of `r` distinct elements from the iterable, where order matters. - **Use case:** Problems requiring permutations without replacement. - **Implementation:** Yields tuples of length `r` (default `r` equals length of iterable). - **Example:** ```python from itertools import permutations list(permutations('ABC', 2)) # Output: [('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'C'), ('C', 'A'), ('C', 'B')] ``` - **Key mental model:** Unlike combinations, `'AB'` and `'BA'` are distinct. #### c. `itertools.combinations(iterable, r)` - **Conceptual model:** Select `r` elements from iterable, ignoring order and disallowing repetitions. - **Use case:** Choosing subsets or unique groupings. - **Implementation:** Yields sorted tuples of length `r`. - **Example:** ```python from itertools import combinations list(combinations('ABC', 2)) # Output: [('A', 'B'), ('A', 'C'), ('B', 'C')] ``` - **Mental model:** For `['A', 'B', 'C']` picking 2 is like choosing pairs regardless of arrangement. #### d. `itertools.combinations_with_replacement(iterable, r)` - **Conceptual model:** Like combinations but elements can appear multiple times. - **Use case:** Selecting combinations where repeats are allowed. - **Implementation:** Yields sorted tuples where elements can recur. - **Example:** ```python from itertools import combinations_with_replacement list(combinations_with_replacement('AB', 2)) # Output: [('A', 'A'), ('A', 'B'), ('B', 'B')] ``` *** ### 3. Functional and Performance Notes - All these combinatoric iterators **return generator objects**, supporting lazy evaluation to handle potentially large combinatorial spaces without memory blowup. - Outputs are tuples representing fixed-size sequences or selections. - The generation order and structure adhere to mathematical combinatorics rules (e.g., lexicographic ordering for combinations). - Be mindful of the combinatorial explosion, where output size can grow factorially or exponentially with input size. *** ### 4. Related Tools and Concepts in `functools` and Others - While `functools` does not include combinatorics generators directly, its role complements iterator tools by providing **function composition**, **partial application** (`partial`), and caching mechanisms (`lru_cache`) common in higher-order functional programming. - For complex pipeline building involving combinatorics generators, these tools enhance composability and performance in functional-style codebases. *** ### Mental Model Summary Table | Function | Category | Usage Mental Model | Output | Notes | |----------------------------------|--------------------|------------------------------------------------|-------------------------------|--------------------------------| | `product(*iterables, repeat=1)` | Cartesian product | Cross-combine elements, repeat allows self-product | Tuples representing Cartesian product elements | Size = $$\prod |iterables_i|$$ or $$|iterable|^{repeat}$$ | | `permutations(iterable, r=None)` | Permutations | Order-sensitive arrangements of length r | Tuples of length r | Number of permutations = n!/(n-r)! | | `combinations(iterable, r)` | Combinations | Unordered selection of r items without replacement | Tuples of length r | Number = C(n, r) | | `combinations_with_replacement(iterable, r)` | Combinations with replacement | Unordered selection allowing duplicates | Tuples of length r | Number = C(n+r-1, r) | *** ### References - Python official documentation — `itertools` [combinatoric iterators section](https://docs.python.org/3/library/itertools.html#itertools.combinations) - GeeksforGeeks "Combinatoric Iterators in Python" (2025)[1][2] - Blog posts and overviews such as Juha-Matti Santala’s "Combinatoric iterators from itertools" (2024)[3] - Real Python and Towards Data Science tutorials on `itertools` This combinatorics toolkit in `itertools` forms the backbone for algorithmic exploration in exhaustive, sampled, or random combinatorial problems while preserving efficiency and clarity in Python's iterator model. Let me know if you'd like me to dive into usage patterns, performance characteristics, or idiomatic compositions with these combinatorics generators. [1] https://www.geeksforgeeks.org/python-itertools/ [2] https://www.geeksforgeeks.org/combinatoric-iterators-in-python/ [3] https://hamatti.org/posts/combinatoric-iterators-from-itertools/ [4] https://www.pythonlikeyoumeanit.com/Module2_EssentialsOfPython/Itertools.html [5] https://towardsdatascience.com/a-guide-to-python-itertools-like-no-other-454da1ddd5b8/ [6] https://realpython.com/python-itertools/ [7] https://mathspp.com/blog/module-itertools-overview [8] https://docs.python.org/3/library/itertools.html [9] https://labex.io/tutorials/python-how-to-use-itertools-combinations-in-python-398083 [10] https://arjancodes.com/blog/python-itertools-module-tutorial-for-efficient-data-handling/Rearranger Generators: yield all items in the input iterables, in some rearranged ways
They all accept at most one input variable.
itertools.groupby,itertool.teereturn multiple generatorsGOTCHA:
itertools.groupbyassumes that the input iterable is sorted by the grouping criterion, or at least that the items are clustered by that criterion — even if not completely sorted.e.g. use case: you can sort the datetime objects chronologically, then groupby weekday to get a group of Monday data, followed by Tuesday data, etc., and then by Monday (of the next week) again, and so on.
itertools.teesimilar to unix tee, gives us multiple generators to consume the yielded values independently.which has a unique behavior: it yields multiple generators from a single input iterable, each yielding every item from the input. Those generators can be consumed independently,
reversedonly works with sequences
Iterable Reducing Functions
given an iterable, they return a single result \(\implies\) “reducing”/ “folding” / “accumulating” functions.
Naturally, they have to work with bounded iterables, won’t work with infinite iterables.
allandanyhave the ability to short-circuit!
Subgenerators with yield from
- objective is to let a generator delegate to a subgenerator
- uses
yield from
Reinventing chain
Here’s the implementation without
yield from1 2 3 4 5 6 7 8 9def chain(*iterables): for it in iterables: for i in it: yield i s = 'ABC' r = range(3) return list(chain(s, r))here’s how we can implement
itertools.chainusingyield fromA B C 0 1 2 1 2 3 4 5 6 7 8def chain(*iterables): for it in iterables: yield from it s = 'ABC' r = range(3) return list(chain(s, r))
Traversing a Tree
Step 2: using a subgenerator for the subtrees
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18def tree(cls): yield cls.__name__, 0 yield from sub_tree(cls) # <1> here's the delegation from tree to sub_tree. here, the tree generator is suspended, and sub_tree takes over yielding values def sub_tree(cls): for sub_cls in cls.__subclasses__(): yield sub_cls.__name__, 1 # <2> def display(cls): for cls_name, level in tree(cls): # <3> indent = ' ' * 4 * level print(f'{indent}{cls_name}') if __name__ == '__main__': display(BaseException)the delegation from generator to sub-generator is interesting
here, the
treegenerator is suspended, andsub_treetakes over yielding valueswe soon observe the following pattern:
We do a for loop to get the subclasses of level
N. Each time around the loop, we yield a subclass of levelN, then start another for loop to visit levelN+1.
Step 5
we use the pattern seen before and call the same generator function again as a subgenerator:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19def tree(cls): yield cls.__name__, 0 yield from sub_tree(cls, 1) def sub_tree(cls, level): for sub_cls in cls.__subclasses__(): yield sub_cls.__name__, level yield from sub_tree(sub_cls, level+1) def display(cls): for cls_name, level in tree(cls): indent = ' ' * 4 * level print(f'{indent}{cls_name}') if __name__ == '__main__': display(BaseException)This is limited only by Python’s recursion limit. The default limit allows 1,000 pending functions.
This also has an implicit base case:
sub_treehas no if, but there is an implicit conditional in the for loop:if cls.__subclasses__()returns an empty list, the body of the loop is not executed, therefore no recursive call happens. The base case is when the cls class has no subclasses. In that case,sub_treeyields nothing. It just returns.
Step 6: merge into a single generator
1 2 3 4 5 6 7 8 9 10 11 12 13 14def tree(cls, level=0): yield cls.__name__, level for sub_cls in cls.__subclasses__(): yield from tree(sub_cls, level+1) def display(cls): for cls_name, level in tree(cls): indent = ' ' * 4 * level print(f'{indent}{cls_name}') if __name__ == '__main__': display(BaseException)yield from connects the subgenerator directly to the client code, bypassing the delegating generator. That connection becomes really important when generators are used as coroutines and not only produce but also consume values from the client code,
Generic Iterable Types
- Mypy, reveals that the Iterator type is really a simplified special case of the Generator type.
Iterator[T]is a shortcut forGenerator[T, None, None]. Both annotations mean “a generator that yields items of typeT, but that does not consume or return values.”- Generators can consume and return values \(\implies\) they are classic coroutines
Classic Coroutines via Enhanced Generators
“generators that can consume and return values”
these are not supported by
asynciothe modern, native coroutines are just called “coroutines” now.
2 ways to typehint generators:
Underlying C implementation is the same, they are just USED differently.
as an iterator:
readings: Iterator[float]Bound to an iterator / generator object that yields
floatitemsas a coroutine:
sim_taxi: Generator[Event, float, int]The `sim_taxi` variable can be bound to a coroutine representing a taxi cab in a discrete event simulation. It yields events, receives `float` timestamps, and returns the number of trips made during the simulation
The type is named
Generator, when in fact it describes the API of a generator object intended to be used as a coroutine, while generators are more often used as simple iterators.Generator[YieldType, SendType, ReturnType]Generator type has the same type parameters as
typing.Coroutine:Coroutine[YieldType, SendType, ReturnType](deprecated in favour ofcollections.abc.Coroutine) which is to annotate only native co-routines, not classic coroutines.Some guidelines to avoid confusion:
- Generators produce data for iteration
- Coroutines are consumers of data
- To keep your brain from exploding, don’t mix the two concepts together
- Coroutines are not related to iteration
- Note: There is a use of having `yield` produce a value in a coroutine, but it’s not tied to iteration.
Example: Coroutine to Compute a Running Average
Old example of running average using closures. This is a higher order function.
1 2 3 4 5 6 7 8 9 10def make_averager(): count = 0 total = 0 def averager(new_value): nonlocal count, total count += 1 total += new_value return total / count return averageryieldstatement here suspends the coroutine, yields a result to the client, and — later — gets a value sent by the caller to the coroutine, starting another iteration of the infinite loop.The coroutine can keep internal state without needing any instance attrs or closures. They keep local state between activations \(\implies\) attractive replacement for callbacks in async programming
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43""" A coroutine to compute a running average # tag::CORO_AVERAGER_TEST[] >>> coro_avg = averager() # <1> >>> next(coro_avg) # <2> 0.0 >>> coro_avg.send(10) # <3> 10.0 >>> coro_avg.send(30) 20.0 >>> coro_avg.send(5) 15.0 # end::CORO_AVERAGER_TEST[] # tag::CORO_AVERAGER_TEST_CONT[] >>> coro_avg.send(20) # <1> 16.25 >>> coro_avg.close() # <2> >>> coro_avg.close() # <3> >>> coro_avg.send(5) # <4> Traceback (most recent call last): ... StopIteration # end::CORO_AVERAGER_TEST_CONT[] """ # tag::CORO_AVERAGER[] from collections.abc import Generator def averager() -> Generator[float, float, None]: # <1> yields float, accepts float, nothing useful returned total = 0.0 count = 0 average = 0.0 while True: # <2> will keep accepting as long as there are values sent to this coroutine term = yield average # <3> =yield= statement here suspends the coroutine, yields a result to the client, and — later — gets a value sent by the caller to the coroutine, starting another iteration of the infinite loop. total += term count += 1 average = total/count # end::CORO_AVERAGER[]Priming/Starting the Coroutine
We can do an initial
next(my_coroutine)OR, we can
send(None)to start it off. Only None works here because a coroutine can’t accept a sent value, unless it is suspended at ayieldline.
Multiple activations
After each activation, the coroutine is suspended precisely at the
yieldkeyword, waiting for a value to be sent.coro_avg.send(10): yield expression resolves to the value 10, assigning it to the term variable. The rest of the loop updates the total, count, and average variables. The next iteration in the while loop yields the average, and the coroutine is again suspended at the yield keyword.i notice that there’s 2 states to the co-routine: active and suspended.
Terminating a coroutine
can just stop referring to it and the coroutine can be garbage collected
for explicit termination, we can call
coro_avg.close().close()method raisesGeneratorExitat the suspended yield expression. If not handled in the coroutine function, the exception terminates it.GeneratorExitis caught by the generator object that wraps the coroutine—that’scalling close on a closed coroutine does nothing, but sending to a closed coroutine raises
StopIteration
Returning a Value from a Coroutine
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99""" A coroutine to compute a running average. Testing ``averager2`` by itself:: # tag::RETURNING_AVERAGER_DEMO_1[] >>> coro_avg = averager2() >>> next(coro_avg) >>> coro_avg.send(10) # <1> >>> coro_avg.send(30) >>> coro_avg.send(6.5) >>> coro_avg.close() # <2> # end::RETURNING_AVERAGER_DEMO_1[] Catching `StopIteration` to extract the value returned by the coroutine:: # tag::RETURNING_AVERAGER_DEMO_2[] >>> coro_avg = averager2() >>> next(coro_avg) >>> coro_avg.send(10) >>> coro_avg.send(30) >>> coro_avg.send(6.5) >>> try: ... coro_avg.send(STOP) # <1> ... except StopIteration as exc: ... result = exc.value # <2> ... >>> result # <3> Result(count=3, average=15.5) # end::RETURNING_AVERAGER_DEMO_2[] Using `yield from`: # tag::RETURNING_AVERAGER_DEMO_3[] NOTE: this uses a delegating generator >>> def compute(): ... res = yield from averager2(True) # <1> ... print('computed:', res) # <2> ... return res # <3> ... >>> comp = compute() # <4> >>> for v in [None, 10, 20, 30, STOP]: # <5> ... try: ... comp.send(v) # <6> ... except StopIteration as exc: # <7> Have to capture the StopIteration, else the GeneratorExit exception is raised at the yield line in the coroutine, so the return statement is never reached. ... result = exc.value received: 10 received: 20 received: 30 received: <Sentinel> computed: Result(count=3, average=20.0) >>> result # <8> Result(count=3, average=20.0) # end::RETURNING_AVERAGER_DEMO_3[] """ # tag::RETURNING_AVERAGER_TOP[] from collections.abc import Generator from typing import Union, NamedTuple class Result(NamedTuple): # <1> count: int # type: ignore # <2> average: float class Sentinel: # <3> def __repr__(self): return f'<Sentinel>' STOP = Sentinel() # <4> SendType = Union[float, Sentinel] # <5> modern python, write it as SendType: TypeAlias = float | Sentinel, or directly use the =|= union in the generator SendType type param # end::RETURNING_AVERAGER_TOP[] # tag::RETURNING_AVERAGER[] def averager2(verbose: bool = False) -> Generator[None, SendType, Result]: # <1> None data yielded, returns Result type, which is a named tuple (subclass of tuple) total = 0.0 count = 0 average = 0.0 while True: term = yield # <2> this consumes data (when resuming, assigned to variable named "term") if verbose: print('received:', term) if isinstance(term, Sentinel): # <3> if received the Sentinel, break from infinite loop. break total += term # <4> count += 1 average = total / count return Result(count, average) # <5> reachable only if Sentinel is sent to the coroutine # end::RETURNING_AVERAGER[]coroutines can consume data, (based on the SendType type param). So that’s why it makes sense to use yield directly.
Calling
.close()in this coroutine makes it stop but does not return a result, because theGeneratorExitexception is raised at theyieldline in the coroutine, so thereturnstatement is never reached.Instead, we do:
1 2 3 4 5try: coro_avg.send(STOP) except StopIteration as exc: result = exc.value return resultSTOPsentinel makes the coroutine break from the loop and return aResultThe generator object that wraps the coroutine then raisesStopIteration.The instance of
StopIterationhas avalueattribute bound to the value of thereturnstatement that terminated the coroutine.
Generic Type Hints for Classic Coroutines
stick to my existing mental model:
producers can produce more specific types, i.e. can be narrower \(\implies\) they are covariant \(\implies\) they are output types
so this corresponds to the
YieldTypeandReturnTypefloat :> intGenerator[float, Any, float] :> Generator[int, Any, int]
Corresponds to variance rule of thumb 1:
If a formal type parameter defines a type for data that comes out of the object, it can be covariant.
consumers can accept more generic types i.e. they can accept wider \(\implies\) they are contravariant \(\implies\) they are input types
so this corresponds to
SendTypefloat :> intGenerator[Any, float, Any] <: Generator[Any, int, Any]
Corresponds to variance rule of thumb 2:
If a formal type parameter defines a type for data that goes into the object after its initial construction, it can be contravariant.
elaboration on why my mental model is correct:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137Your **mental model about generic type hints for classic coroutines in Python is fundamentally correct** and aligns well with the design principles of variance in type systems and how they apply to the parameters of the `Generator` or `Coroutine` generic types. To unpack this rigorously: *** ### Context: Generic Type Parameters for Classic Coroutines Classic (generator-based) coroutines and generators can be annotated using the generic `Generator` type hint which has three type parameters: $$ Generator[YieldType, SendType, ReturnType] $$ - **YieldType** — the type of values **produced** (yielded) by the generator/coroutine. - **SendType** — the type of values the generator/coroutine **accepts** via `.send()` (like parameters you can pass in). - **ReturnType** — the type of the value returned upon completion (from the `return` statement inside the generator). *** ### Your mental model restated - **Producers produce more specific types (narrower types).** This corresponds to output types, and hence these are **covariant types**. This includes `YieldType` (values yielded) and `ReturnType` (final returned value). - **Consumers accept more generic types (wider types).** These correspond to input types, hence they are **contravariant types**. This corresponds to `SendType` — the values you send **into** the coroutine, which can be more general. *** ### What does this mean in terms of type variance? - **Covariance** means that if $$A$$ is a subtype of $$B$$, then a producer of $$A$$ is also a producer of $$B$$ (safe to substitute). For example, if you expect `YieldType` to be a `Animal`, then yielding `Dog` (subclass of Animal) is safe. - **Contravariance** means that consumers are the opposite — if you can accept a `B`, then you can accept an `A` if $$A$$ is a subtype of $$B$$ (i.e., input types vary contravariantly). The coroutine can accept wider types for sending. **Consequently:** - `YieldType` and `ReturnType` are **covariant** (output positions). - `SendType` is **contravariant** (input position). *** ### Supporting evidence from Python typing docs and references: From the official `typing` module documentation and the typing system used in Python: - The `Generator` and `Coroutine` generic types define variance as follows: ```python from typing import Generator # Generator[YieldType, SendType, ReturnType] # YieldType is covariant # SendType is contravariant # ReturnType is covariant ``` This is also explicitly mentioned in the Python 3.12 typing docs [typing — Support for type hints](https://docs.python.org/3/library/typing.html): > "Note that unlike many other generic classes in the standard library, the `SendType` of `Generator` behaves contravariantly, not covariantly or invariantly." *** ### Mental model mapping for classic coroutines: | Role | Type Parameter | Type Variance | Reason / Interpretation | |--------------------------|--------------------|---------------------|------------------------------------------------| | Values *output* (yielded) | `YieldType` | Covariant (produced) | Coroutine produces values of this type | | Value passed *in* to `.send()` | `SendType` | Contravariant (consumed) | Coroutine consumes values of this type from caller | | Value *returned* upon completion | `ReturnType` | Covariant (produced) | Coroutine returns this type after finishing | *** ### Intuition: - When you **consume** a coroutine, you can **send** values that are more general (superclasses, supertypes) than what the coroutine internally expects — because the coroutine must handle all these general cases safely. - When a coroutine **yields** or **returns** values, it provides more specific types (subclasses or narrower types) back to the caller. *** ### Example to make it concrete Suppose you have: ```python from typing import Generator def coro() -> Generator[int, str, float]: # Yield ints val = yield 1 # Accept strings sent via send ... return 3.14 ``` - `YieldType` = `int`: you produce integers. - `SendType` = `str`: you accept strings sent to the coroutine. - `ReturnType` = `float`: coroutine returns a float on completion. This fits the mental model that: - You produce (yield) integers (specific concrete type). - You consume (accept via `.send()`) strings (input). - You return a float (specific type). *** ### Summary Your mental model: - **Producers = covariant = YieldType, ReturnType** - **Consumers = contravariant = SendType** is **correct and aligns perfectly with the Python typing system** for classic coroutines and generators. *** ### Supporting references for further deep-dive: - [Python typing module documentation - Annotating generators and coroutines](https://docs.python.org/3/library/typing.html#annotating-generators-and-coroutines) (2025-08-08) - Fluent Python by Luciano Ramalho, "Classic Coroutines" chapter, which discusses these typing details around classic coroutines and variance. - Python typing source and PEP 484 (Type Hints) discussing variance in generic types. - Stack Overflow [The right way to type hint a Coroutine function?](https://stackoverflow.com/questions/73240620/the-right-way-to-type-hint-a-coroutine-function) detailing coroutine generic parameters and variance. *** Please let me know if you want me to expand on how this mental model impacts safe API design, variance variance violations, or practical examples of generic coroutine typing! [1] https://stackoverflow.com/questions/73240620/the-right-way-to-type-hint-a-coroutine-function [2] https://docs.python.org/3/library/typing.html [3] https://www.r-bloggers.com/2023/06/leveraging-generic-type-hints-of-classes-in-python/ [4] https://www.fluentpython.com/extra/classic-coroutines/ [5] https://www.reddit.com/r/Python/comments/10zdidm/why_type_hinting_sucks/ [6] https://www.linkedin.com/pulse/python-generators-elegant-efficient-often-underused-peter-eldritch-a7faf [7] https://docs.python.org/3/reference/datamodel.html
Chapter Summary
- kiv native coroutines will come soon, the
yield fromis now justawaitin the native coroutine syntax.
Further Reading
Chapter 18. with, match, and else Blocks
this chapter is about control flow structures that are especially powerful in python
magic of
withstatements and how the context manager gives safetythe magic of
matchstatements and how that is expressive for languages (including custom DSLs)
What’s New in This Chapter
Context Managers and with Blocks
context managers exist to control a
withstatementanalogous to
forstatements controlled by iteratorsMISCONCEPTIONS:
this is correct: a
finallyblock is always guaranteed to run, even if the try block has areturn,sys.exit()or an exception raised.I just never paid attention to this.
That’s why it’s good for cleanup: resource release / reverting or undoing temporary state changes
withblocks don’t define a new scope like how functions do, that’s why the names are accessible outside of the blocksyntax:
in
with open('mirror.py') as fp:,evaluating the expression after the
withgives the context manager object, i.e.open('mirror.py')the context manager object here is an instance of
TextIOWrapper, this is what theopen()function returns.the
__enter__method ofTextIOWrapperreturnsselfthe target variable is within the
asclause is bound to somethingthe
asclause is optionalthat something is the result returned by the
__enter__method of the context manager object (TextIOWrapper), which we determined wasself(i.e. the context manager instance)
for any reason, when the control flow exists the
withblock, then__exit__is called on the context manager object.This is NOT called on whatever that was returned by
__enter__and stored by the target variable.
example code Custom Context Manager for mirror
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90""" A "mirroring" ``stdout`` context. While active, the context manager reverses text output to ``stdout``:: # tag::MIRROR_DEMO_1[] >>> from mirror import LookingGlass >>> with LookingGlass() as what: # <1> ... print('Alice, Kitty and Snowdrop') # <2> ... print(what) ... pordwonS dna yttiK ,ecilA YKCOWREBBAJ >>> what # <3> 'JABBERWOCKY' >>> print('Back to normal.') # <4> Back to normal. # end::MIRROR_DEMO_1[] This exposes the context manager operation:: # tag::MIRROR_DEMO_2[] >>> from mirror import LookingGlass >>> manager = LookingGlass() # <1> >>> manager # doctest: +ELLIPSIS <mirror.LookingGlass object at 0x...> >>> monster = manager.__enter__() # <2> >>> monster == 'JABBERWOCKY' # <3> eurT >>> monster 'YKCOWREBBAJ' >>> manager # doctest: +ELLIPSIS >... ta tcejbo ssalGgnikooL.rorrim< >>> manager.__exit__(None, None, None) # <4> >>> monster 'JABBERWOCKY' # end::MIRROR_DEMO_2[] The context manager can handle and "swallow" exceptions. # tag::MIRROR_DEMO_3[] >>> from mirror import LookingGlass >>> with LookingGlass(): ... print('Humpty Dumpty') ... x = 1/0 # <1> ... print('END') # <2> ... ytpmuD ytpmuH Please DO NOT divide by zero! >>> with LookingGlass(): ... print('Humpty Dumpty') ... x = no_such_name # <1> ... print('END') # <2> ... Traceback (most recent call last): ... NameError: name 'no_such_name' is not defined # end::MIRROR_DEMO_3[] """ # tag::MIRROR_EX[] import sys class LookingGlass: def __enter__(self): # <1> self.original_write = sys.stdout.write # <2> sys.stdout.write = self.reverse_write # <3> return 'JABBERWOCKY' # <4> def reverse_write(self, text): # <5> self.original_write(text[::-1]) def __exit__(self, exc_type, exc_value, traceback): # <6> sys.stdout.write = self.original_write # <7> if exc_type is ZeroDivisionError: # <8> print('Please DO NOT divide by zero!') return True # <9> # <10> NOTE: if exit returns None or any falsy value, any exception raised in the =with= block will be propagated. # end::MIRROR_EX[]enter and exit:
__enter__is called without any arguments other than the implicitself(which is the context manager instance)__exit__is called with 3 arguments:exc_typeexc_valuethe actual exception instancetraceback
these 3 args received by
selfare the same as what happens if we callsys.exc_info()in thefinallyblock of atry/finally. in the past, calling that was necessary to determine how to do the cleanup.
we can now do parenthesized context managers:
1 2 3 4 5 6with ( CtxManager1() as example1, CtxManager2() as example2, CtxManager3() as example3, ): ...thanks to a new parser from python 3.10 onwards
The contextlib Utilities
- first-reach before writing custom context managers
- things that look useful:
using
@contextmanagerto build a context manager from a generator functionContextDecoratorto define class-based context managersthe async versions of all of them
Using @contextmanager
just implement a generator with a single
yieldstatement that should produce whatever you want the__enter__method to returnthe
yieldsplits the function body into two parts:before
yield: gets executed at the beginning of thewithblock when interpreter calls__enter__after
yield: gets executed when__exit__is called at the end of the block
correct example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98""" A "mirroring" ``stdout`` context manager. While active, the context manager reverses text output to ``stdout``:: # tag::MIRROR_GEN_DEMO_1[] >>> from mirror_gen import looking_glass >>> with looking_glass() as what: # <1> ... print('Alice, Kitty and Snowdrop') ... print(what) ... pordwonS dna yttiK ,ecilA YKCOWREBBAJ >>> what 'JABBERWOCKY' # end::MIRROR_GEN_DEMO_1[] This exposes the context manager operation:: # tag::MIRROR_GEN_DEMO_2[] >>> from mirror_gen import looking_glass >>> manager = looking_glass() # <1> >>> manager # doctest: +ELLIPSIS <contextlib._GeneratorContextManager object at 0x...> >>> monster = manager.__enter__() # <2> >>> monster == 'JABBERWOCKY' # <3> eurT >>> monster 'YKCOWREBBAJ' >>> manager # doctest: +ELLIPSIS >...x0 ta tcejbo reganaMtxetnoCrotareneG_.biltxetnoc< >>> manager.__exit__(None, None, None) # <4> False >>> monster 'JABBERWOCKY' # end::MIRROR_GEN_DEMO_2[] The context manager can handle and "swallow" exceptions. The following test does not pass under doctest (a ZeroDivisionError is reported by doctest) but passes if executed by hand in the Python 3 console (the exception is handled by the context manager): # tag::MIRROR_GEN_DEMO_3[] >>> from mirror_gen_exc import looking_glass >>> with looking_glass(): ... print('Humpty Dumpty') ... x = 1/0 # <1> ... print('END') # <2> ... ytpmuD ytpmuH Please DO NOT divide by zero! # end::MIRROR_GEN_DEMO_3[] >>> with looking_glass(): ... print('Humpty Dumpty') ... x = no_such_name # <1> ... print('END') # <2> ... Traceback (most recent call last): ... NameError: name 'no_such_name' is not defined """ # tag::MIRROR_GEN_EXC[] import contextlib import sys @contextlib.contextmanager def looking_glass(): original_write = sys.stdout.write def reverse_write(text): original_write(text[::-1]) sys.stdout.write = reverse_write msg = '' # <1> try: yield 'JABBERWOCKY' except ZeroDivisionError: # <2> msg = 'Please DO NOT divide by zero!' finally: sys.stdout.write = original_write # <3> if msg: print(msg) # <4> # end::MIRROR_GEN_EXC[]it’s unavoiadable to use the
try/exceptwhen using theyieldwhen using@contextmanagersince we never know what the users of the context managers will do.GOTCHA:
Generally,
if
__exit__returns truthy even if there’s an exception, then the exception is suppressed. If it’s not truthy, then the exception is propagated outHOWEVER, with
@contextmanager, the default behaviour is inverted. the__exit__method provided by the decorator assumes any exception sent into the generator is handled and should be suppressed.
- (flawed) example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79""" A "mirroring" ``stdout`` context manager. While active, the context manager reverses text output to ``stdout``:: # tag::MIRROR_GEN_DEMO_1[] >>> from mirror_gen import looking_glass >>> with looking_glass() as what: # <1> ... print('Alice, Kitty and Snowdrop') ... print(what) ... pordwonS dna yttiK ,ecilA YKCOWREBBAJ >>> what 'JABBERWOCKY' >>> print('back to normal') back to normal # end::MIRROR_GEN_DEMO_1[] This exposes the context manager operation:: # tag::MIRROR_GEN_DEMO_2[] >>> from mirror_gen import looking_glass >>> manager = looking_glass() # <1> >>> manager # doctest: +ELLIPSIS <contextlib._GeneratorContextManager object at 0x...> >>> monster = manager.__enter__() # <2> >>> monster == 'JABBERWOCKY' # <3> eurT >>> monster 'YKCOWREBBAJ' >>> manager # doctest: +ELLIPSIS >...x0 ta tcejbo reganaMtxetnoCrotareneG_.biltxetnoc< >>> manager.__exit__(None, None, None) # <4> False >>> monster 'JABBERWOCKY' # end::MIRROR_GEN_DEMO_2[] The decorated generator also works as a decorator: # tag::MIRROR_GEN_DECO[] >>> @looking_glass() ... def verse(): ... print('The time has come') ... >>> verse() # <1> emoc sah emit ehT >>> print('back to normal') # <2> back to normal # end::MIRROR_GEN_DECO[] """ # tag::MIRROR_GEN_EX[] import contextlib import sys @contextlib.contextmanager # <1> def looking_glass(): original_write = sys.stdout.write # <2> def reverse_write(text): # <3> original_write(text[::-1]) sys.stdout.write = reverse_write # <4> yield 'JABBERWOCKY' # <5> sys.stdout.write = original_write # <6> # end::MIRROR_GEN_EX[]
this is flawed because if an exception is raised in the body of the
withblock, the Python interpreter will catch it and raise it again in theyieldexpression insidelooking_glass. But there is no error handling there, so the looking_glass generator will terminate without ever restoring the originalsys.stdout.writemethod, leaving the system in an invalid state.Cleanup not done if there’s an exception raised within the
withblock.TRICK: generators decorated with it can also be used as decorators themselves.
happens because
@contextmanageris implemented with thecontextlib.ContextDecoratorclass.1 2 3 4 5@looking_glass() def verse(): print("the time has come") verse() # returns in reverseHere,
looking_glassdoes its job before and after the body of verse runs.
Pattern Matching in lis.py: A Case Study
- Scheme Syntax
- Imports and Types
- The Parser
- The Environment
- The REPL
- The Evaluator
- Procedure: A Class Implementing a Closure
- Using OR-patterns
Do This, Then That: else Blocks Beyond if
use cases: avoids the need to setup extra control flags or coding extra
ifstatementsraising pattern:
1 2 3 4 5for item in my_list: if item.flavor == 'banana': break else: raise ValueError('No banana flavor found!')keep the try blocks lean in
try/exceptThe body of the
tryblock should only have the statements that generate the expected exceptions.Instead of doing this:
1 2 3 4 5try: dangerous_call() after_call() except OSError: log('OSError...')We should do:
1 2 3 4 5 6try: dangerous_call() except OSError: log('OSError...') else: after_call()
This gives clarity.
tryblock is guarding against possible errors indangerous_call()and not inafter_call(). It’s also explicit thatafter_call()will only execute if no exceptions are raised in thetryblock.IDIOM:
try/exceptis NOT only for error handling, it can be used for control flow as well. E.g. duck typing type checks.Follows EAFP
EAFP
Easier to ask for forgiveness than permission. This common Python coding style assumes the existence of valid keys or attributes and catches exceptions if the assumption proves false. This clean and fast style is characterized by the presence of many try and except statements. The technique contrasts with the LBYL style common to many other languages such as C.
this contrasts LBYL:
LBYL
Look before you leap. This coding style explicitly tests for pre-conditions before making calls or lookups. This style contrasts with the EAFP approach and is characterized by the presence of many if statements. In a multi-threaded environment, the LBYL approach can risk introducing a race condition between “the looking” and “the leaping.” For example, the code, if key in mapping: return mapping[key] can fail if another thread removes key from mapping after the test, but before the lookup. This issue can be solved with locks or by using the EAFP approach.
elseblocks apply to most control flow constructs, they are closely related to each other but very different fromif/elseLANGUAGE_LIMITIATION: GOTCHA: the
elsekeyword is more of more of a “run this loop, then do that” instead of “Run this loop, otherwise do that”for:elseblock will run only if and when theforloop runs to completion (i.e.,notif the for is aborted with abreak).while:elseblock will run only if and when thewhileloop exits because the condition became falsy (i.e., not if thewhileis aborted with a break).try: Theelseblock will run only if no exception is raised in thetryblock.NOTE: “Exceptions in the else clause are not handled by the preceding except clauses.”
the
elseclause is also skipped if an exception or areturn,break, orcontinuestatement causes control to jump out of the main block of the compound statement.
Chapter Summary
an insight:
subroutines are the most important invention in the history of computer languages. If you have sequences of operations like A;B;C and P;B;Q, you can factor out B in a subroutine. It’s like factoring out the filling in a sandwich: using tuna with different breads. But what if you want to factor out the bread, to make sandwiches with wheat bread, using a different filling each time? That’s what the with statement offers. It’s the complement of the subroutine.
Further Reading
Chapter 19. Concurrency Models in Python
concurrency vs parallelism; informally speaking
concurrency: dealing with multiple things done at once \(\implies\) it’s about structure of a solution
the structure provided by concurrent solutions may help solve a problem (though not necessarily) in a parallelized fashion.
parallelism: doing lots of things at once \(\implies\) execution of the solution
in this informal view, it’s a special case of concurrency, so parallel \(\implies\) concurrent
Python’s three approaches to concurrency: threads, processes, and native coroutine.
python’s fitness for concurrent and parallel computing is not limited to what the std lib provides. Python can scale.
What’s New in This Chapter
The Big Picture
factor of difficulty when writing concurrent programs: starting threads or processes is easy enough, but how do you keep track of them?
non concurrent programs, function call is blocking so useful for us
concurrent programs, non blocking, need to rely on some form of communication to get back results or errors
starting a thread is not cheap \(\implies\) amortize costs by using “worker” threads/procs \(\implies\) coordinating them is tough e.g. how to terminate?
resolved using messages and queues still
coroutines are useful:
- cheap to start
- returns values
- can be safely cancelled
- specific area to catch exceptions
But they have problems:
they’re handled by the async framework \(\implies\) hard to monitor as threads / procs
not good for CPU-intensive tasks
A Bit of Jargon
Concurrency: ability to handle multiple pending tasks (each eventually succeeding or failing) \(\implies\) can multitask
Parallelism: ability to compute multiple computations at the same time \(\implies\) multicore CPU, multiple CPU, GPU, multiple computers in a cluster
Execution Unit: objects executing concurrent code. Each has independent state and call stack
Python execution units:
processes
definition:
instance of computer program while it’s running, using memory and CPU time-slices, all of which has its own private memory space
communication:
objects communicated as raw bytes (so must be serialised) to pass from one proc to another. Communicated via pipes, sockets or memory-mapped files
spawning:
can spawn child procs which are all isolated from the parent
scheduling:
can be pre-emptively scheduled, supposed to be that a frozen proc won’t freeze the whole system
threads
definition:
execution unit within a single process
consumes less resources than a process (if they both did the same job)
lifecycle:
@ start of process, there’s a single thread. Procs can create more threads by calling OS APIs
Shared Memory management:
Threads within a process share the same memory space \(\implies\) holds live Python object. Shared memory may be corrupted via read/write race conditions
Supervision:
Also supervised by OS Scheduler, threads can enable pre-emptive multitasking
coroutines
Definition:
A function that can suspend itself and resume later.
Classic Coroutines: built from generator functions
Native Coroutines: defined using
async defSupervising coroutines:
Typically, coroutines run within a single thread, supervised by an event loop that is in the same thread.
Async frameworks provide an event loop and supporting libs that support nonblocking, coroutine-based I/)
Scheduling & Cooperative Multitasking:
each coroutine must explicitly cede control with the
yieldorawaitkeyword, so that another may proceed concurrently (but not in parallel).so if there’s any blocking code in a coroutine block, it would block the execution of the event loop and hence all other coroutines
this contrasts preemptive multitasking supported by procs and threads.
nevertheless, coroutine consumes less resources than a thread or proc doing the same job
Mechanisms useful to us:
Queue:
purpose:
allow separate execution units to exchange application data and control messages, such as error codes and signals to terminate.
implementation:
depends on concurrency model:
python stdlib
queuegives queue classes to support threadsthis also provides non-FIFO queues like
LifoQueueandPriorityQueuemultiprocessing,asynciopackages have their own queue classesasyncioalso provides non-FIFO queues likeLifoQueueandPriorityQueue
Lock:
purpose:
Sync mechanism object for execution units to sync actions and avoid data corruption
While updating a shared data structure, the running code should hold an associated lock.
implementation:
depends on the concurrency model
simplest form of a lock is just a mutex
Contention: dispute over a limited asset
Resource Contention
When multiple exeuction units try to access a shared resoruce (e.g. a lock / storage)
CPU Contention
Compute-intensive procs / threads must wait for the OS scheduler to give them a share of CPU time
Processes, Threads, and Python’s Infamous GIL
Here’s 10 points that consolidate info about python’s concurrency support:
Instance of python interpreter \(\implies\) a process
We can create additional Python processes \(\leftarrow\) use
multiprocessing/concurrent.futureslibrariesWe can also start sub-processes that run any other external programs. \(\leftarrow\) using
subprocesslibraryInterpreter runs user program and the GC in a single thread. We can start additional threads using
threading/concurrent.futureslibraries.GIL (Global Interpreter Lock) controls internal interpreter state (process state shared across threads) and access to object ref counts.
Only one python thread can hold the GIL at any time \(\implies\) only one thread can execute Python code at any time, regardless the number of CPU cores.
GIL is NOT part of the python language definition, it’s a CPython Implementation detail. This is critical for portability reasons.
Default release of the GIL @ an interval:
Prevents any particular thread from holding the GIL indefinitely.
It’s the bytecode interpreter that pauses the current thread every 5ms default (can be changed) and the OS Scheduler picks who (which thread) gets access to the GIL next (could be the same thread that just released the GIL also).
Python source code can’t control the GIL but extension / builtin written in C (or lang that interfaces at the Python/C API level) can release the GIL when it’s running time-consuming tasks.
Every python stdlib that does a syscall (for kernel services) will release the GIL. This avoids contention of resources (mem as well as CPU)
functions that perform I/O operations (disk, network, sleep)
functions that are CPU-intensive (e.g.
NumPy/SciPy), compressing/decompressing functions (e.g.zlib,bz2)
GIL-free threads:
can only be launched by extensions that integrate at the Python/C API level
can’t change python objects generally, but can R/W to memory objects that support buffer protocols (
bytearray,array.array,NumPyarrays)GIL-free python is under experimentation at the moment (but not mainstream)
Network I/O is GIL-insensitive
GIL minimally affects network programming because Network I/O is higher latency than memory I/O.
Each individual thread would have spent long time waiting anyway so interleaving their execution doesn’t majory impact the overall throughput.
Compute-intensive python threads \(\implies\) will be slowed down by GIL contention.
Better to use sequential, single-threaded code here. Faster and simpler.
CPU-intensive python code to be ran on multiple cores requires multiple python processes.
Extra Notes:
Coroutines are not affected by the GIL
by default they share the same Python thread among themselves and with the supervising event loop provided by an asynchronous framework, therefore the GIL does not affect them.
We technically can use multiple therads in an async program. This is not best practice.
Typically, we have one coordinating thread running the event loops, which delegates to additional threads that carry out specific tasks.
KIV “delegating tasks to executors”
A Concurrent Hello World
- a demo of how python can “walk and chew gum”, using multiple approaches:
multiprocessing,threading,asyncio
Spinner with Threads
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44# spinner_thread.py # credits: Adapted from Michele Simionato's # multiprocessing example in the python-list: # https://mail.python.org/pipermail/python-list/2009-February/675659.html # tag::SPINNER_THREAD_TOP[] import itertools import time from threading import Thread, Event def spin(msg: str, done: Event) -> None: # <1> this fn runs in a separate thread, Event instance is for syncing of threads for char in itertools.cycle(r'\|/-'): # <2> infinite loop because infinite iterator status = f'\r{char} {msg}' # <3> the carriage return TRICK print(status, end='', flush=True) if done.wait(.1): # <4> ??? the timeout value sets the "framerate" of the animation (0.1s => 10FPS) break # <5> break inf loop blanks = ' ' * len(status) print(f'\r{blanks}\r', end='') # <6> clears the status line def slow() -> int: # called by the main thread time.sleep(3) # <7> this is a blocking syscall, so GIL is released, which will allow other threads to be executed return 42 # end::SPINNER_THREAD_TOP[] # tag::SPINNER_THREAD_REST[] def supervisor() -> int: # <1> eventually returns the result of =slow= done = Event() # <2> to coordinate =main= and =spinner= thread spinner = Thread(target=spin, args=('thinking!', done)) # <3> spawn thread print(f'spinner object: {spinner}') # <4> displays as <Thread(Thread-1, initial)> ; initial means the thread not started yet spinner.start() # <5> result = slow() # <6> call slow, blocks the =main= thread, while the secondary =spinner= thread still runs the animation done.set() # <7> signals spin function to exit, terminates the fot loop inside the spin function spinner.join() # <8> wait until spinner finishes (fork-join!) return result def main() -> None: result = supervisor() # <9> just a didatic purpose, to make it similar to the asyncio version print(f'Answer: {result}') if __name__ == '__main__': main() # end::SPINNER_THREAD_REST[]Notes:
within
slow(),time.sleepblocks the calling thread but releases the GIL, so other Python threads (in this case our secondary thread for spinner) can run.spinandslowexecuted concurrently, the supervisor coordinates the threads using an instance ofthreading.Eventcreating threads:
create a new
Thread, provide a function as the target keyword argument, and positional arguments to the target as a tuple passed via argsspinner = Thread(target=spin, args=('thinking!', done)) # <3> spawn threadwe can also pass in kwargs using
kwargsnamed parameter toThreadconstructor
threading.Event:Python’s simplest signalling mechanism to coordinate threads.
Event instance has an internal boolean flag that starts as
False. CallingEvent.set()sets the flag toTrue.- when flag is
False(unset):if a thread calls
Event.wait(), the thread is blocked until another thread callsEvent.set(). When this happens,Event.wait()returnsTrueIf timeout is provided
Event.wait(s), the call returnsFalsewhen timeout elapses.As soon as another thread calls
Event.set()then the wait function will returnTrue.
- when flag is
TRICK: for text-mode animation: move the cursor back to the start of the line with the carriage return ASCII control character (
'\r').
Spinner with Processes
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46# spinner_proc.py # credits: Adapted from Michele Simionato's # multiprocessing example in the python-list: # https://mail.python.org/pipermail/python-list/2009-February/675659.html # tag::SPINNER_PROC_IMPORTS[] import itertools import time from multiprocessing import Process, Event # <1> from multiprocessing import synchronize # <2> this import supports the type hinting for the Event def spin(msg: str, done: synchronize.Event) -> None: # <3> attention to the typehint # end::SPINNER_PROC_IMPORTS[] for char in itertools.cycle(r'\|/-'): status = f'\r{char} {msg}' print(status, end='', flush=True) if done.wait(.1): break blanks = ' ' * len(status) print(f'\r{blanks}\r', end='') def slow() -> int: time.sleep(3) return 42 # tag::SPINNER_PROC_SUPER[] def supervisor() -> int: done = Event() spinner = Process(target=spin, # <4> args=('thinking!', done)) print(f'spinner object: {spinner}') # <5> displays <Process name='Process-1' parent=14868 initial> so it tells you the PID and the initial state. spinner.start() result = slow() done.set() spinner.join() return result # end::SPINNER_PROC_SUPER[] def main() -> None: result = supervisor() print(f'Answer: {result}') if __name__ == '__main__': main()multiprocessingpackage supports running concurrent tasks in separate Python processes instead of threads.each instance has its own python interpreter, procs will be working in the background.
Each proc has its own GIL \(\implies\) we can exploit our multicore CPU well because of this (depends on the OS scheduler though)
multiprocessingAPI emulates thethreadingAPI \(\implies\) can easily convert between them.Comparing
multiprocessingandtheradingAPIssimilarities
Event objects are similar in how they function with the bit setting / unsetting
Event objects can wait on timeouts
differences:
Event is of different type between them
multiprocessing.Eventis a function (not a class likethreading.Event)multiprocessinghas a larger API because it’s more complexe.g. python objects that would need to be communicated across process need to be serialized/deserialized because it’s an OS-level isolation (of processes). This adds overhead.
the
Eventstate is the only cross-proccess state being shared, it’s implemented via an OS semaphorememory sharing can be done via
multiprocessing.shared_memory. Only raw bytes, can use aShareableList(mutable sequence) with a fixed number of items of some primitives up to 10MB per item.
Spinner with Coroutines
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41# spinner_async.py # credits: Example by Luciano Ramalho inspired by # Michele Simionato's multiprocessing example in the python-list: # https://mail.python.org/pipermail/python-list/2009-February/675659.html # tag::SPINNER_ASYNC_TOP[] import asyncio import itertools async def spin(msg: str) -> None: # <1> no need Event as a coordinating mechanism for char in itertools.cycle(r'\|/-'): status = f'\r{char} {msg}' print(status, flush=True, end='') try: await asyncio.sleep(.1) # <2> this is a non-blocking pause except asyncio.CancelledError: # <3> when the cancelled method is called on the task that is controlling this coroutine break blanks = ' ' * len(status) print(f'\r{blanks}\r', end='') async def slow() -> int: await asyncio.sleep(3) # <4> also uses the non blocking sleep return 42 # end::SPINNER_ASYNC_TOP[] # tag::SPINNER_ASYNC_START[] def main() -> None: # <1> only regular function here, rest are coroutines result = asyncio.run(supervisor()) # <2> supervisor coroutine will block the main function print(f'Answer: {result}') async def supervisor() -> int: # <3> native coroutine definition spinner = asyncio.create_task(spin('thinking!')) # <4> returns a Task, schedules the eventual execution of spin print(f'spinner object: {spinner}') # <5> <Task pending name='Task-2' coro=<spin() running at /path/to/spinner_async.py:11>> result = await slow() # <6> =await= calls slow, blocks =supervisor= until =slow= returns spinner.cancel() # <7> Task.cancel() raises =CancelledError= inside the coro task return result if __name__ == '__main__': main() # end::SPINNER_ASYNC_START[]who manages the event loop?
for threads and processes, it’s the OS Scheduler
for coroutines, it’s app-level event loop
drives coroutines one by one, manages queue of pending coroutines, passes control back to corresponding coroutine when each event happens
all of these execute in a single thread: event loop, library coroutines, user coroutines
that’s why coroutines logic is blocking
Concurrency is achieved by control passing from one coroutine to another.
Python code using
asynciohas only one flow of execution, unless you’ve explicitly started additional threads or processes.means only one coroutine executes at any point in time.
Concurrency is achieved by control passing from one coroutine to another. This happens when we use the
awaitkeyword.Remember when using
asynciocoroutines, if we ever need some time for NOOPs, to use non-blocking sleep (asyncio.sleep(DELAY)) instead of blocking sleep (time.sleep())explaining the example
asyncio.runstarts the event loop, drives the coroutine (supervisor) that sets other coroutines in motion.supervisorwill block themainfunction until it’s doneasyncio.runreturns whatsupervisorreturnsawaitcallsslow, blockssupervisoruntilslowreturnsI think it’s easier to see it as a control flow handover to slow. That’s why it’s blocking and that’s why when the control flow returns, we carry on with the assignment operator.
Task.cancel()raisesCancelledErrorinside the coro task
NOTE: if we directly invoke a coro like
coro()it immediately returns (because it’s async) but doesn’t return the body of thecorofunctionthe
coroneeds to be driven by an event loop.We see 3 ways to run a coro (driven by an event loop):
asyncio.run(coro())a regular function will call this
usually the first coro is the entry point, that supervisor
return value of
runis whatever the body ofcororeturns
asyncio.create_task(coro())called from a coroutine, returns a
Taskinstance.Taskwraps the coro and provides methods to control and query its state.schedules another coroutine to be eventually run
does not suspend current coroutine
await coro()- transfers control from current coro to coro returned by
coro() - suspends the current coro until the other coro returns
- value of
awaitexpression is whatever the body of thecororeturns
- transfers control from current coro to coro returned by
Supervisors Side-by-Side
asyncio.Taskvsthreading.Thread(roughly equivalent)Tasktrives a coroutine object,Threadinvokes a callableyielding control: coroutine yields explicitly with
awaitwe don’t instantiate
Taskobjects ourselves , we get them by usingasyncio.create_task()explicit scheduling:
create_taskgives aTaskobject that is already waiting to run,Threadinstance must be explicitly told to run viastart
Termination:
threads can’t be terminated from the outside, we can only pass in a signal (eg. setting
doneinEvent)tasks
Task.cancel()can be cancelled from the outside, raisesCancelledErrorat the await expression where the coro body is currently suspendedthis can happen because coros are always in-sync because only one of them is running at any time, that’s why the outside can come and cancel it vs outside suggesting to terminate via a signal.
Instead of holding locks to synchronize the operations of multiple threads, coroutines are “synchronized” by definition: only one of them is running at any time.
coroutines, code is protected against interruption by default because we’re in charge of driving the event loop
The Real Impact of the GIL
Quick Quiz
the main question here is that are the mechanisms interruptable by the entity that coordinates the control flow.
processes are controlled by OS scheduler so this is interruptable \(\implies\) the
multiprocessingversion will still carry on as usualthreads are controlled by the OS scheduler as well and the GIL lock can be released at a default interval, so this is useful to us \(\implies\) the threading approach will not have a noticeable difference.
this has negligible effect only because the number of threads were minimal (2). If any more, it may be visible.
the asyncio coroutine version will be blocked by this compute-intensive call.
we can try doing this hack though: make the
is_primea coroutine andawait asyncio.sleep(0)to yield control flow.This is slow though
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59# spinner_prime_async_nap.py # credits: Example by Luciano Ramalho inspired by # Michele Simionato's multiprocessing example in the python-list: # https://mail.python.org/pipermail/python-list/2009-February/675659.html import asyncio import itertools import math import functools # tag::PRIME_NAP[] async def is_prime(n): if n < 2: return False if n == 2: return True if n % 2 == 0: return False root = math.isqrt(n) for i in range(3, root + 1, 2): if n % i == 0: return False if i % 100_000 == 1: await asyncio.sleep(0) # <1> return True # end::PRIME_NAP[] async def spin(msg: str) -> None: for char in itertools.cycle(r'\|/-'): status = f'\r{char} {msg}' print(status, flush=True, end='') try: await asyncio.sleep(.1) except asyncio.CancelledError: break blanks = ' ' * len(status) print(f'\r{blanks}\r', end='') async def check(n: int) -> int: return await is_prime(n) async def supervisor(n: int) -> int: spinner = asyncio.create_task(spin('thinking!')) print('spinner object:', spinner) result = await check(n) spinner.cancel() return result def main() -> None: n = 5_000_111_000_222_021 result = asyncio.run(supervisor(n)) msg = 'is' if result else 'is not' print(f'{n:,} {msg} prime') if __name__ == '__main__': main()Using await
asyncio.sleep(0)should be considered a stopgap measure before you refactor your asynchronous code to delegate CPU-intensive computations to another process.
A Homegrown Process Pool
Process-Based Solution
- starts a number of worker processes equal to the number of CPU cores, as determined by
multiprocessing.cpu_count() - some overhead in spinning up processes and in inter-process communication
- starts a number of worker processes equal to the number of CPU cores, as determined by
- Understanding the Elapsed Times
Code for the Multicore Prime Checker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78#!/usr/bin/env python3 """ procs.py: shows that multiprocessing on a multicore machine can be faster than sequential code for CPU-intensive work. """ # tag::PRIMES_PROC_TOP[] import sys from time import perf_counter from typing import NamedTuple from multiprocessing import Process, SimpleQueue, cpu_count # <1> use the SimpleQueue to build a queue from multiprocessing import queues # <2> use queues.SimpleQueue for typing from primes import is_prime, NUMBERS class PrimeResult(NamedTuple): # <3> n: int prime: bool elapsed: float JobQueue = queues.SimpleQueue[int] # <4> TypeAlias for a simple queue to send numbers to the procs that will do the job ResultQueue = queues.SimpleQueue[PrimeResult] # <5> TypeAlias for simple queue for building the results def check(n: int) -> PrimeResult: # <6> t0 = perf_counter() res = is_prime(n) return PrimeResult(n, res, perf_counter() - t0) def worker(jobs: JobQueue, results: ResultQueue) -> None: # <7> gets a queue to read from (jobs) and a queue to write to (results) while n := jobs.get(): # <8> uses n = 0 as the poison pill results.put(check(n)) # <9> primality check then enqueue the result results.put(PrimeResult(0, False, 0.0)) # <10> signals that the worker is done def start_jobs( procs: int, jobs: JobQueue, results: ResultQueue # <11> procs: number of parallel prime checks ) -> None: for n in NUMBERS: jobs.put(n) # <12> enqueue number to be checked for _ in range(procs): proc = Process(target=worker, args=(jobs, results)) # <13> Fork a child proc for each worker, runs until it fetches a 0 from jobs queue proc.start() # <14> starting the child proc jobs.put(0) # <15> poision pill it after starting, will be read after all the actual jobs get read # end::PRIMES_PROC_TOP[] # tag::PRIMES_PROC_MAIN[] def main() -> None: if len(sys.argv) < 2: # <1> procs = cpu_count() else: procs = int(sys.argv[1]) print(f'Checking {len(NUMBERS)} numbers with {procs} processes:') t0 = perf_counter() jobs: JobQueue = SimpleQueue() # <2> results: ResultQueue = SimpleQueue() start_jobs(procs, jobs, results) # <3> starts the workers checked = report(procs, results) # <4> elapsed = perf_counter() - t0 print(f'{checked} checks in {elapsed:.2f}s') # <5> def report(procs: int, results: ResultQueue) -> int: # <6> checked = 0 procs_done = 0 while procs_done < procs: # <7> n, prime, elapsed = results.get() # <8> if n == 0: # <9> procs_done += 1 else: checked += 1 # <10> label = 'P' if prime else ' ' print(f'{n:16} {label} {elapsed:9.6f}s') return checked if __name__ == '__main__': main() # end::PRIMES_PROC_MAIN[]when delegating computing to threads / procs, code doesn’t call the worker function directly
the worker is driven by the thread or proc library
the worker eventually produces a result that is stored somewhere
worker coordination & result collection are common uses of queues in concurrent programming
IDIOM: loops, sentinels and poison pills:
workerfunction useful for showing common concurrent programming pattern:we loop indefinitely while taking items from a queue and processing each with a fn that does the actual work (
check)we end the loop when the queue produces a sentinel value
the sentinel value that shuts down a worker is often called a poison pill
TRICK/IDIOM: poison pilling to signal the worker to finish
notice the use of the poison-pill in point 8 of the code above
common sentinels: (here’s a comment thread on sentinels)
None, but may not work if the data stream legitimately may produceNoneobject()is a common sentinel but Python objects must be serialised for IPC, so when we pickle.dump and pickle.load and object, the unpickled instance is distinct from the original and doesn’t compare equal.⭐️
...Ellipsisbuiltin is a good option, it will survive serialisation without losing its identity.
Debugging concurrent code is always hard, and debugging multiprocessing is even harder because of all the complexity behind the thread-like façade.
Experimenting with More or Fewer Processes
- typically after the number of cores available to us, we should expect runtime to increase because of CPU Contention
Thread-Based Nonsolution
Due to the GIL and the compute-intensive nature of is_prime, the threaded version is slower than the sequential code
it gets slower as the number of threads increase, because of CPU contention and the cost of context switching.
OS contention: all the stack frame changes required is what causes the extra overhead
KIV managing threads and processes using
concurrent.futures(chapter 20) and doing async programming usingasyncio(chapter 21)
Python in the Multicore World
GIL makes the interpreter faster when running on a single core, and its implementation simpler. It was a no-brainer when CPU performance didn’t hinge on concurrency.
Despite the GIL, Python is thriving in applications that require concurrent or parallel execution, thanks to libraries and software architectures that work around the limitations of CPython.
System Administration
use cases: manage hardware like NAS, use it for SDN (software defined networking), hacking
python scripts help with these tasks, commanding remote machines \(\implies\) aren’t really CPU bound operations \(\implies\) Threads & Coroutines are Good for this
we can use the concurrent futures to perform the same operation on multiple remote machines at the same time without much complexity
Data Science
- compute-intensive applications, supported by an ecosystem of libs that can leverage multicore machines, GPUs / distribued parallel computing in heterogeneous clusters
- some libs:
- project jupyter
- tensorflow (Google) and pytorch (Facebook)
- dask: parallel computing lib to cordinate work on clusters
Server-Side Web/Mobile Development
- both for app caches and HTTP caches (CDNs)
WSGI Application Servers
WSGI a standard API for a Python framework or application to receive requests from an HTTP server and send responses to it.
WSGI apps manage one or more procs running your application, maximising the use of available CPUs
main point: all of these application servers can potentially use all CPU cores on the server by forking multiple Python processes to run traditional web apps written in good old sequential code in Django, Flask, Pyramid, etc. This explains why it’s been possible to earn a living as a Python web developer without ever studying the threading, multiprocessing, or asyncio modules: the application server handles concurrency transparently.
Distributed Task Queues
Distributed Task Queues wrap a message queue and offer a high-level API for delegating tasks to workers, possibly running on different machines.
use cases:
run background jobs
trigger jobs after responding to the web request
async retries to ensure something is done
scheduled jobs
e.g. Django view handler produces job requests which are put in the queue to be consumed by one or more PDF rendering processes
Supports horizontal scalability
producers and consumers are decoupled
I’ve used Celery before!!
Chapter Summary
the demo on the effect of the GIL
demonstrated graphically that CPU-intensive functions must be avoided in asyncio, as they block the event loop.
the prime demo highlighted the difference between multiprocessing and threading, proving that only processes allow Python to benefit from multicore CPUs.
GIL makes threads worse than sequential code for heavy computations.
Further Reading
Concurrency with Threads and Processes
this was the introduction of the
multiprocessinglibrary via a PEP, one of the longer PEPs writtendivide-and-conquer approaches for splitting jobs on clusters vs server-sider ssystems where it’s simpler and efficient to let each process work on one computation from start to finish and reducing the overhead from IPC
this will likely be a useful read for high performance python
- The GIL
Concurrency Beyond the Standard Library
- Concurrency and Scalability Beyond Python
Chapter 20. Concurrent Executors
concurrent.futures.Executorclasses that encapsulate the pattern of “spawning a bunch of independent threads and collecting the results in a queue,” described by Michele Simionato.can be used with threads as well as processes
introduces
futures, similar to JS promises. futures are the low level objects herethis chapter is more demo, less theoretical
What’s New in This Chapter
Concurrent Web Downloads
the concurrent scripts are about 5x faster
typically when well done, concurrent scripts can outpace sequential ones by a factor of 20x or more
TRICK: I didn’t know that the
HTTPXlibrary is more modern and the go-to vsrequestslib. HTTPX gives both async and sync functions but requests will only give sync versions.for server-side, servers that may be hit by many clients, there is a difference between what concurrency primitive we use (threading vs coroutines):
coroutines scale better because they use much less memory than threads, and also reduce the cost of context switching
A Sequential Download Script
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58#!/usr/bin/env python3 """Download flags of top 20 countries by population Sequential version Sample runs (first with new domain, so no caching ever):: $ ./flags.py BD BR CD CN DE EG ET FR ID IN IR JP MX NG PH PK RU TR US VN 20 downloads in 26.21s $ ./flags.py BD BR CD CN DE EG ET FR ID IN IR JP MX NG PH PK RU TR US VN 20 downloads in 14.57s """ # tag::FLAGS_PY[] import time from pathlib import Path from typing import Callable import httpx # <1> non stdlib import, conventionally comes after stdlib imports POP20_CC = ('CN IN US ID BR PK NG BD RU JP ' 'MX PH VN ET EG DE IR TR CD FR').split() # <2> BASE_URL = 'https://www.fluentpython.com/data/flags' # <3> DEST_DIR = Path('downloaded') # <4> def save_flag(img: bytes, filename: str) -> None: # <5> saving bytes to file (DEST_DIR / filename).write_bytes(img) def get_flag(cc: str) -> bytes: # <6> downloads the thing, returns byte contents of the response url = f'{BASE_URL}/{cc}/{cc}.gif'.lower() resp = httpx.get(url, timeout=6.1, # <7> good to have timeouts if we are making blocking calls like in this demo follow_redirects=True) # <8> resp.raise_for_status() # <9> prevents silent failures because of non 2XX responses return resp.content def download_many(cc_list: list[str]) -> int: # <10> sequential version, to be compared across the other examples for cc in sorted(cc_list): # <11> to observe that the order will be preserved image = get_flag(cc) save_flag(image, f'{cc}.gif') print(cc, end=' ', flush=True) # <12> the flush is to flush the print buffer return len(cc_list) def main(downloader: Callable[[list[str]], int]) -> None: # <13> allows the downloader to be injectable, to be used for the other examples DEST_DIR.mkdir(exist_ok=True) # <14> create dir if necessary t0 = time.perf_counter() # <15> count = downloader(POP20_CC) elapsed = time.perf_counter() - t0 print(f'\n{count} downloads in {elapsed:.2f}s') if __name__ == '__main__': main(download_many) # <16> # end::FLAGS_PY[]
Downloading with concurrent.futures
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34#!/usr/bin/env python3 """Download flags of top 20 countries by population ThreadPoolExecutor version Sample run:: $ python3 flags_threadpool.py DE FR BD CN EG RU IN TR VN ID JP BR NG MX PK ET PH CD US IR 20 downloads in 0.35s """ # tag::FLAGS_THREADPOOL[] from concurrent import futures from flags import save_flag, get_flag, main # <1> reusing things def download_one(cc: str): # <2> single downloader, this is what each worker will execute image = get_flag(cc) save_flag(image, f'{cc}.gif') print(cc, end=' ', flush=True) return cc def download_many(cc_list: list[str]) -> int: with futures.ThreadPoolExecutor() as executor: # <3> ThreadPoolExecutor is the context manager here, exit method will be blocking until all threads are done res = executor.map(download_one, sorted(cc_list)) # <4> map is similar in style as map builtin, returns a generator that we have to iterate to get the value from each function call return len(list(res)) # <5> if __name__ == '__main__': main(download_many) # <6> # end::FLAGS_THREADPOOL[]The context manager is
ThreadPoolExecutor, theexecutor.__exit__method will callexecutor.shutdown(wait=True)and this is blocking until all the threads are done.executor.map()similar tomapbuiltin,the function is called concurrently from multiple threads
it returns a generator that we need to iterate to retrieve the value returned by each function call
any exceptions from a particular call will also be within this.
concurrent.futuresmakes it easy for us to add concurrent execution atop legacy sequential codeOther useful args to
ThreadPoolExecutor:max_workersthe default is
max_workers = min(32, os.cpu_count() + 4)the extra ones are for I/O-BOUND tasksAlso it will try to reuse idle workers instead of using new workers. (lmao meeting rooms II leetcode question be like)
Where Are the Futures?
purpose: an instance of either Future class represents a deferred computation that may or may not have completed.
like Promise in JS
both async frameworks give us futures:
concurrent.futures.Futureandasyncio.Futureallows us to put them in queues and check if they’re done
HOWEVER, it is the job of the concurrency framework to handle futures, WE DON’T create them directly. This is because a future represents something that will eventually run, so it must be scheduled to run and that’s the role of the framework
e.g.
Executor.submit(<callable>)does the scheduling and returns aFutureWho can change the state of a future?
Only the concurrency framework, never the application code.
We are NOT in control of the state of a future.
push/pull method to determine completion:
pull:
Future.done()where the applogic keeps pollingpush:
Future.add_done_callback()to register a callback that will be invoked when the future is done. NOTE: the callback callable will run in the same worker thread or process that ran the function wrapped in the future.futures have a
result()when done, it works the same for both libs
when not done, it works differently for the two libs:
=concurrency.futures.Future: callingf.result()will block the caller’s thread until the result is ready (we can pass a timeout to avoid infinite blocking)
- demo:In this example, because we’re getting the futures from
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31#!/usr/bin/env python3 """Download flags of top 20 countries by population ThreadPoolExecutor example with ``as_completed``. """ from concurrent import futures from flags import main from flags_threadpool import download_one # tag::FLAGS_THREADPOOL_AS_COMPLETED[] def download_many(cc_list: list[str]) -> int: cc_list = cc_list[:5] # <1> smaller sample with futures.ThreadPoolExecutor(max_workers=3) as executor: # <2> attempt to see pending futures in the output to_do: list[futures.Future] = [] for cc in sorted(cc_list): # <3> future = executor.submit(download_one, cc) # <4> schedules the callable to be executed, returns a future representing this pending operation to_do.append(future) # <5> just storing it for inspection print(f'Scheduled for {cc}: {future}') # <6> we'll see something like this: Scheduled for BR: <Future at 0x100791518 state=running> for count, future in enumerate(futures.as_completed(to_do), 1): # <7> yields futures as they are completed res: str = future.result() # <8> retrieving the result print(f'{future} result: {res!r}') # <9> will look something like this: IN <Future at 0x101807080 state=finished returned str> result: 'IN' return count # end::FLAGS_THREADPOOL_AS_COMPLETED[] if __name__ == '__main__': main(download_many)as_completed, when we callfuture.result(), it will never be blocking.
Launching Processes with concurrent.futures
Both
ProcessPoolExecutorandThreadPoolExecutorimplement theExecutorinterfacethis allows us to switch from thread-based to process-based concurrency using
concurrent.futuresso we can use process-based primitives just like we can use thread-based primitives, we just have to call a different pool executor
main usecase for process-based is for CPU-intensive jobs
Using process-based allows us to go around the GIL and use multiple CPU cores to simplify
Remember processes use more memory and take longer to start than threads
Main usecase for thread-based is I/O intensive applications.
Multicore Prime Checker Redux
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50#!/usr/bin/env python3 """ proc_pool.py: a version of the proc.py example from chapter 20, but using `concurrent.futures.ProcessPoolExecutor`. """ # tag::PRIMES_POOL[] import sys from concurrent import futures # <1> no need to import the lower level abstractions (multiprocessing, SimpleQueue) from time import perf_counter from typing import NamedTuple from primes import is_prime, NUMBERS class PrimeResult(NamedTuple): # <2> we don't need the queues or the worker function anymore n: int flag: bool elapsed: float def check(n: int) -> PrimeResult: t0 = perf_counter() res = is_prime(n) return PrimeResult(n, res, perf_counter() - t0) def main() -> None: if len(sys.argv) < 2: workers = None # <3> setting to None allows the ProcessPoolExecutor decide for us else: workers = int(sys.argv[1]) executor = futures.ProcessPoolExecutor(workers) # <4> built executor so that we have access the acutal workers selected actual_workers = executor._max_workers # type: ignore # <5> print(f'Checking {len(NUMBERS)} numbers with {actual_workers} processes:') t0 = perf_counter() numbers = sorted(NUMBERS, reverse=True) # <6> with executor: # <7> we use the executor as the context manager for n, prime, elapsed in executor.map(check, numbers): # <8> returns PrimeResult instances that =check= returns in the same order as the numbers argument label = 'P' if prime else ' ' print(f'{n:16} {label} {elapsed:9.6f}s') time = perf_counter() - t0 print(f'Total time: {time:.2f}s') if __name__ == '__main__': main() # end::PRIMES_POOL[]the use of
executor.map()will block until all child processes are done. It preserves the order in which they were spawned.blocking overall but not individually, that’s why the rest return almost instantly
Experimenting with Executor.map
| |
the display will be seen to get updated incrementally.
enumerate call in the for loop will implicitly invoke
next(results), which in turn will invoke_f.result()on the (internal)_ffuture representing the first call,loiter(0)the
_f.result()will block unti the future is doneExecutor.map()will block until all the jobs are done.Alternatively, to make it more JIT, we can use
Executor.submitandfutures.as_completedTRICK : This is more flexible than
executor.mapbecause you can submit different callables and arguments, while executor.map is designed to run the same callable on the different arguments.TRICK: we can pass futures to
futures.as_completedsuch that the futures come from different pool executors (including different type of pool executors)
Downloads with Progress Display and Error Handling
- common functions
just a reference on the support code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155"""Utilities for second set of flag examples. """ import argparse import string import sys import time from collections import Counter from enum import Enum from pathlib import Path DownloadStatus = Enum('DownloadStatus', 'OK NOT_FOUND ERROR') POP20_CC = ('CN IN US ID BR PK NG BD RU JP ' 'MX PH VN ET EG DE IR TR CD FR').split() DEFAULT_CONCUR_REQ = 1 MAX_CONCUR_REQ = 1 SERVERS = { 'REMOTE': 'https://www.fluentpython.com/data/flags', 'LOCAL': 'http://localhost:8000/flags', 'DELAY': 'http://localhost:8001/flags', 'ERROR': 'http://localhost:8002/flags', } DEFAULT_SERVER = 'LOCAL' DEST_DIR = Path('downloaded') COUNTRY_CODES_FILE = Path('country_codes.txt') def save_flag(img: bytes, filename: str) -> None: (DEST_DIR / filename).write_bytes(img) def initial_report(cc_list: list[str], actual_req: int, server_label: str) -> None: if len(cc_list) <= 10: cc_msg = ', '.join(cc_list) else: cc_msg = f'from {cc_list[0]} to {cc_list[-1]}' print(f'{server_label} site: {SERVERS[server_label]}') plural = 's' if len(cc_list) != 1 else '' print(f'Searching for {len(cc_list)} flag{plural}: {cc_msg}') if actual_req == 1: print('1 connection will be used.') else: print(f'{actual_req} concurrent connections will be used.') def final_report(cc_list: list[str], counter: Counter[DownloadStatus], start_time: float) -> None: elapsed = time.perf_counter() - start_time print('-' * 20) plural = 's' if counter[DownloadStatus.OK] != 1 else '' print(f'{counter[DownloadStatus.OK]:3} flag{plural} downloaded.') if counter[DownloadStatus.NOT_FOUND]: print(f'{counter[DownloadStatus.NOT_FOUND]:3} not found.') if counter[DownloadStatus.ERROR]: plural = 's' if counter[DownloadStatus.ERROR] != 1 else '' print(f'{counter[DownloadStatus.ERROR]:3} error{plural}.') print(f'Elapsed time: {elapsed:.2f}s') def expand_cc_args(every_cc: bool, all_cc: bool, cc_args: list[str], limit: int) -> list[str]: codes: set[str] = set() A_Z = string.ascii_uppercase if every_cc: codes.update(a+b for a in A_Z for b in A_Z) elif all_cc: text = COUNTRY_CODES_FILE.read_text() codes.update(text.split()) else: for cc in (c.upper() for c in cc_args): if len(cc) == 1 and cc in A_Z: codes.update(cc + c for c in A_Z) elif len(cc) == 2 and all(c in A_Z for c in cc): codes.add(cc) else: raise ValueError('*** Usage error: each CC argument ' 'must be A to Z or AA to ZZ.') return sorted(codes)[:limit] def process_args(default_concur_req): server_options = ', '.join(sorted(SERVERS)) parser = argparse.ArgumentParser( description='Download flags for country codes. ' 'Default: top 20 countries by population.') parser.add_argument( 'cc', metavar='CC', nargs='*', help='country code or 1st letter (eg. B for BA...BZ)') parser.add_argument( '-a', '--all', action='store_true', help='get all available flags (AD to ZW)') parser.add_argument( '-e', '--every', action='store_true', help='get flags for every possible code (AA...ZZ)') parser.add_argument( '-l', '--limit', metavar='N', type=int, help='limit to N first codes', default=sys.maxsize) parser.add_argument( '-m', '--max_req', metavar='CONCURRENT', type=int, default=default_concur_req, help=f'maximum concurrent requests (default={default_concur_req})') parser.add_argument( '-s', '--server', metavar='LABEL', default=DEFAULT_SERVER, help=f'Server to hit; one of {server_options} ' f'(default={DEFAULT_SERVER})') parser.add_argument( '-v', '--verbose', action='store_true', help='output detailed progress info') args = parser.parse_args() if args.max_req < 1: print('*** Usage error: --max_req CONCURRENT must be >= 1') parser.print_usage() # "standard" exit status codes: # https://stackoverflow.com/questions/1101957/are-there-any-standard-exit-status-codes-in-linux/40484670#40484670 sys.exit(2) # command line usage error if args.limit < 1: print('*** Usage error: --limit N must be >= 1') parser.print_usage() sys.exit(2) # command line usage error args.server = args.server.upper() if args.server not in SERVERS: print(f'*** Usage error: --server LABEL ' f'must be one of {server_options}') parser.print_usage() sys.exit(2) # command line usage error try: cc_list = expand_cc_args(args.every, args.all, args.cc, args.limit) except ValueError as exc: print(exc.args[0]) parser.print_usage() sys.exit(2) # command line usage error if not cc_list: cc_list = sorted(POP20_CC)[:args.limit] return args, cc_list def main(download_many, default_concur_req, max_concur_req): args, cc_list = process_args(default_concur_req) actual_req = min(args.max_req, max_concur_req, len(cc_list)) initial_report(cc_list, actual_req, args.server) base_url = SERVERS[args.server] DEST_DIR.mkdir(exist_ok=True) t0 = time.perf_counter() counter = download_many(cc_list, base_url, args.verbose, actual_req) final_report(cc_list, counter, t0)
Error Handling in the flags2 Examples
- sequential version
Uses a sequential HTTPX client
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91#!/usr/bin/env python3 """Download flags of countries (with error handling). Sequential version Sample run:: $ python3 flags2_sequential.py -s DELAY b DELAY site: http://localhost:8002/flags Searching for 26 flags: from BA to BZ 1 concurrent connection will be used. -------------------- 17 flags downloaded. 9 not found. Elapsed time: 13.36s """ # tag::FLAGS2_BASIC_HTTP_FUNCTIONS[] from collections import Counter from http import HTTPStatus import httpx import tqdm # type: ignore # <1> from flags2_common import main, save_flag, DownloadStatus # <2> get the commons DEFAULT_CONCUR_REQ = 1 MAX_CONCUR_REQ = 1 def get_flag(base_url: str, cc: str) -> bytes: url = f'{base_url}/{cc}/{cc}.gif'.lower() resp = httpx.get(url, timeout=3.1, follow_redirects=True) resp.raise_for_status() # <3> raises if HTTP status code not in range(200, 300) return resp.content def download_one(cc: str, base_url: str, verbose: bool = False) -> DownloadStatus: try: image = get_flag(base_url, cc) except httpx.HTTPStatusError as exc: # <4> handles the 404 errors specifically res = exc.response if res.status_code == HTTPStatus.NOT_FOUND: status = DownloadStatus.NOT_FOUND # <5> replaces it with an internal download status msg = f'not found: {res.url}' else: raise # <6> re-propagate any other errors other than 404 else: save_flag(image, f'{cc}.gif') status = DownloadStatus.OK msg = 'OK' if verbose: # <7> verbosity flag print(cc, msg) return status # end::FLAGS2_BASIC_HTTP_FUNCTIONS[] # tag::FLAGS2_DOWNLOAD_MANY_SEQUENTIAL[] def download_many(cc_list: list[str], base_url: str, verbose: bool, _unused_concur_req: int) -> Counter[DownloadStatus]: counter: Counter[DownloadStatus] = Counter() # <1> to tally the download outcomes cc_iter = sorted(cc_list) # <2> if not verbose: cc_iter = tqdm.tqdm(cc_iter) # <3> tqdm returns an iterator yielding the items in cc_iter and also animating the progress bar for cc in cc_iter: try: status = download_one(cc, base_url, verbose) # <4> successive calls to the singular function except httpx.HTTPStatusError as exc: # <5> the non 404 errors handled here error_msg = 'HTTP error {resp.status_code} - {resp.reason_phrase}' error_msg = error_msg.format(resp=exc.response) except httpx.RequestError as exc: # <6> error_msg = f'{exc} {type(exc)}'.strip() except KeyboardInterrupt: # <7> manging keyboard interrupts break else: # <8> clear the error msg if there's no error that came down error_msg = '' if error_msg: status = DownloadStatus.ERROR # <9> local status check based on the internal enum counter[status] += 1 # <10> if verbose and error_msg: # <11> print(f'{cc} error: {error_msg}') return counter # <12> # end::FLAGS2_DOWNLOAD_MANY_SEQUENTIAL[] if __name__ == '__main__': main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ)
- sequential version
Uses a sequential HTTPX client
Using
futures.as_completedthreadpool
Uses concurrent HTTP client based on
futures.ThreadPoolExecutorto show error handling1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74#!/usr/bin/env python3 """Download flags of countries (with error handling). ThreadPool version Sample run:: $ python3 flags2_threadpool.py -s ERROR -e ERROR site: http://localhost:8003/flags Searching for 676 flags: from AA to ZZ 30 concurrent connections will be used. -------------------- 150 flags downloaded. 361 not found. 165 errors. Elapsed time: 7.46s """ # tag::FLAGS2_THREADPOOL[] from collections import Counter from concurrent.futures import ThreadPoolExecutor, as_completed import httpx import tqdm # type: ignore from flags2_common import main, DownloadStatus from flags2_sequential import download_one # <1> DEFAULT_CONCUR_REQ = 30 # <2> defaults for max num of concurrent requests, size of threadpool MAX_CONCUR_REQ = 1000 # <3> max num concurrent reqs def download_many(cc_list: list[str], base_url: str, verbose: bool, concur_req: int) -> Counter[DownloadStatus]: counter: Counter[DownloadStatus] = Counter() with ThreadPoolExecutor(max_workers=concur_req) as executor: # <4> to_do_map = {} # <5> maps each Future instance (representing one download) with the cc for error reporting for cc in sorted(cc_list): # <6> response order is more based on timing of the HTTP responses more so than anything future = executor.submit(download_one, cc, base_url, verbose) # <7> each submission does the scheduling and returns a Future to_do_map[future] = cc # <8> Future instances are hashable done_iter = as_completed(to_do_map) # <9> returns an iterator that yields futures as each task is done if not verbose: done_iter = tqdm.tqdm(done_iter, total=len(cc_list)) # <10> wrap the iterator within the progress bar for future in done_iter: # <11> iterates on futures as they are completed try: status = future.result() # <12> this could have been blocking but NOT in this case because it's handled by the as_completed() except httpx.HTTPStatusError as exc: # <13> error handling error_msg = 'HTTP error {resp.status_code} - {resp.reason_phrase}' error_msg = error_msg.format(resp=exc.response) except httpx.RequestError as exc: error_msg = f'{exc} {type(exc)}'.strip() except KeyboardInterrupt: break else: error_msg = '' if error_msg: status = DownloadStatus.ERROR counter[status] += 1 if verbose and error_msg: cc = to_do_map[future] # <14> print(f'{cc} error: {error_msg}') return counter if __name__ == '__main__': main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ) # end::FLAGS2_THREADPOOL[]NOTE:
Futureinstances are hashable, that’s why we can use it as keys within a dictionaryIDIOM: use a map to store futures to do follow up processing
building a dict to map each future to other data that may be useful when the future is completed.
asyncio
Concurrent HTTPX client
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106#!/usr/bin/env python3 """Download flags of countries (with error handling). asyncio async/await version """ # tag::FLAGS2_ASYNCIO_TOP[] import asyncio from collections import Counter from http import HTTPStatus from pathlib import Path import httpx import tqdm # type: ignore from flags2_common import main, DownloadStatus, save_flag # low concurrency default to avoid errors from remote site, # such as 503 - Service Temporarily Unavailable DEFAULT_CONCUR_REQ = 5 MAX_CONCUR_REQ = 1000 async def get_flag(client: httpx.AsyncClient, # <1> base_url: str, cc: str) -> bytes: url = f'{base_url}/{cc}/{cc}.gif'.lower() resp = await client.get(url, timeout=3.1, follow_redirects=True) # <2> resp.raise_for_status() return resp.content async def download_one(client: httpx.AsyncClient, cc: str, base_url: str, semaphore: asyncio.Semaphore, verbose: bool) -> DownloadStatus: try: async with semaphore: # <3> image = await get_flag(client, base_url, cc) except httpx.HTTPStatusError as exc: # <4> res = exc.response if res.status_code == HTTPStatus.NOT_FOUND: status = DownloadStatus.NOT_FOUND msg = f'not found: {res.url}' else: raise else: await asyncio.to_thread(save_flag, image, f'{cc}.gif') # <5> status = DownloadStatus.OK msg = 'OK' if verbose and msg: print(cc, msg) return status # end::FLAGS2_ASYNCIO_TOP[] # tag::FLAGS2_ASYNCIO_START[] async def supervisor(cc_list: list[str], base_url: str, verbose: bool, concur_req: int) -> Counter[DownloadStatus]: # <1> counter: Counter[DownloadStatus] = Counter() semaphore = asyncio.Semaphore(concur_req) # <2> async with httpx.AsyncClient() as client: to_do = [download_one(client, cc, base_url, semaphore, verbose) for cc in sorted(cc_list)] # <3> to_do_iter = asyncio.as_completed(to_do) # <4> if not verbose: to_do_iter = tqdm.tqdm(to_do_iter, total=len(cc_list)) # <5> error: httpx.HTTPError | None = None # <6> for coro in to_do_iter: # <7> try: status = await coro # <8> except httpx.HTTPStatusError as exc: error_msg = 'HTTP error {resp.status_code} - {resp.reason_phrase}' error_msg = error_msg.format(resp=exc.response) error = exc # <9> except httpx.RequestError as exc: error_msg = f'{exc} {type(exc)}'.strip() error = exc # <10> except KeyboardInterrupt: break else: error = None if error: status = DownloadStatus.ERROR # <11> if verbose: url = str(error.request.url) # <12> cc = Path(url).stem.upper() # <13> print(f'{cc} error: {error_msg}') counter[status] += 1 return counter def download_many(cc_list: list[str], base_url: str, verbose: bool, concur_req: int) -> Counter[DownloadStatus]: coro = supervisor(cc_list, base_url, verbose, concur_req) counts = asyncio.run(coro) # <14> return counts if __name__ == '__main__': main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ) # end::FLAGS2_ASYNCIO_START[]
Chapter Summary
Further Reading
Chapter 21. Asynchronous Programming
async constructs
Objects supporting async constructs
includes other constructs enables by the
async/awaitkeywords: async generator functions, async comprehensions, async genexpsthese aren’t tied to
asyncio!
async libraries like
asyncio
What’s New in This Chapter
A Few Definitions
native coroutines
only defined using
async defdelegation from coroutine to coroutine only done using
await, not necessary that it MUST delegateclassic coroutines
actually a generator function that consumes data (data that is sent to it via
my_coro.send(data)calls)can delegate to other classic coroutines using
yield from. Ref “Meaning of yield from”no longer supported by
asyncioand doesn’t supportawaitkeywordgenerator-based coroutines (decorated using
@types.coroutine)a decorated generator function (
@types.coroutine), which makes the generator compatible withawaitkeywordthis is NOT supportd by
asyncio, but used in low-level code in other frameworks likeCurioandTrioasync generator (function)
generator function defined with
async defthat usesyieldin its bodyreturns an async generator object that provides
__anext__, which is a coroutine method to retrieve the next item.
An asyncio Example: Probing Domains
- async operations are interleaved \(\implies\) the total time is practically the same as the time for the single slowest DNS response, instead of the sum of the times of all responses.
| |
loop.getaddrinfo()is the async version ofsocket.getaddrinfo()this returns a 5-part tuples of params to connect to the given address using a socket
asyncio.get_running_loopis designed to be used from within coroutines.If no running event loops, then it raises a
RuntimeError. The event loop should have already been started prior to execution reaching there.for coro in asyncio.as_completed(coros):the
asyncio.as_completed(coros)generator that yields coroutines that return the results of the coros passed to it in the order they are completed (not order of submission), similar tofutures.as_completedthe
await corois non-blocking because it’s guarded by theas_completedaboveif coro raises an exception, then it gets re-raised here
event loop:
started using
asyncio.run()IDIOM: for scripts, the common pattern is to make the
mainfunction a coroutine as well. The main coroutine is driven withasyncio.run()
Guido’s Trick to Read Asynchronous Code
- squint and pretend the async and await keywords are not there. If you do that, you’ll realize that coroutines read like plain old sequential functions.
New Concept: Awaitable
awaitexpression:uses the
yield fromimplementation with an extra step of validating its argumentonly accepts an awaitable
for\(\rightarrow\) iterables,await\(\rightarrow\) awaitablesfrom asyncio, we typically work with these awaitables:
a native coroutine object that we get by calling a native coroutine function e.g.
coro()wherecorois the coroutine functionasyncio.Taskthat we get when we create a task from a coroutine object toasyncio.create_task()remember that the
coro_obj = coro(), so the overall call is usuallyasyncio.creat_task(one_coro()), note the invocation of the native coroutine functionWhether to keep a handle to the task or not depends on whether we need to use it (e.g. to cancel the task or wait for it)
lower-level awaitables: (something we might encouter if we work with lower level abstractions)
an obj with
__await__method that returns an iterator (e.g.asyncio.Future, by the way,asyncio.Task<:asyncio.Future)objs written in other langs that use the Python/C API with a
tp_as_async.am_waitfunction, returning an iterator (similar to__await__method)soon to be deprecated: generator-based-coroutine objects
Downloading with asyncio and HTTPX
| |
asynciodirectly supports TCP and UDP, without relying on external packagesres = await asyncio.gather(*to_do):Here, we pass the awaitables so that they can be gathered after completion, so that we get a list of results. Gathers in the order of submission of the coros.
AsyncClientis the async context manager that is used here. It’s a context manager that has async setup and teardown functions KIVIn this snippet of the
get_flagscoroutine:1 2 3 4 5async def get_flag(client: AsyncClient, cc: str) -> bytes: # <4> needs the client to make the http request url = f'{BASE_URL}/{cc}/{cc}.gif'.lower() resp = await client.get(url, timeout=6.1, follow_redirects=True) # <5> get method also returns a ClientResponse that is an async context manager, the network I/O is drive async via the =asyncio= event loop return resp.read() # <6> the body is just lazily fetched from the response object. This fully consumes the response body into memory.Implicit delegation of coroutines via async context managers:
getmethod of anhttpx.AsyncClientinstance returns aClientResponseobject that is also an asynchronous context manager.this is an awaitable that returns a
Responseby the way,
Responsecan also be used as a context manager when streaming! If it was, thenresp.read()would have been an an I/O operation that may yield to the event loop again if it’s attempting to drain the response body stream from the socket
the
awaityields control flow to the event loop while the network I/O happens (DNS resolution, TCP connect, handshake, waiting for response headers). During that suspension, other tasks can run.so by the end of point 5,
respis a properResponseobject and not a coroutine. The connection is ready.LANG_LIMITATION: However, asyncio does not provide an asynchronous filesystem API at this time like Node.js does.
there’s OS-level support for it (
io_uringon Linux), but nothing that supports this for python’s stdlib/asyncio
The Secret of Native Coroutines: Humble Generators
classic vs native coroutines: the native ones don’t rely on a visible
.send()call oryieldexpressionsmechanistic model for async programs and how they drive async libraries:

Here, we see how in an async program:
a user’s function starts the event loop, scheduling an initial coroutine with
asyncio.runEach user’s coroutine drives the next with an
awaitexpression, which is when the control flow is yielded to the next coroutinethis forms a channel that enables communication between a library like HTTPX and the event loop.
awaitchain eventually reaches a low-level awaitable, which returns a generator that the event loop can drive in response to events such as timers or network I/O. The low-level awaitables and generators at the end of these await chains are implemented deep into the libraries, are not part of their APIs, and may be Python/C extensions.
awaitborrows most of its implementation fromyield from(classic coroutines), which also makes.sendcalls to drive coroutines.functions like
asyncio.gatherandasyncio.create_task, you can start multiple concurrentawaitchannels, enabling concurrent execution of multiple I/O operations driven by a single event loop, in a single thread.
The All-or-Nothing Problem
had to replace I/O functions with their async versions so that they could be activated with
awaitorasyncio.create_taskif no choice, have to delegate to separate thread/proc
If you can’t rewrite a blocking function as a coroutine, you should run it in a separate thread or process
Asynchronous Context Managers via async with
- asynchronous context managers: objects implementing the
__aenter__and__aexit__methods as coroutines.
Enhancing the asyncio Downloader
- caution:
asynciovsthreadingasyncio can send requests faster, so more likely to get suspected of ddos by the HTTP server.
Using
asyncio.as_completedand a Thread1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106#!/usr/bin/env python3 """Download flags of countries (with error handling). asyncio async/await version """ # tag::FLAGS2_ASYNCIO_TOP[] import asyncio from collections import Counter from http import HTTPStatus from pathlib import Path import httpx import tqdm # type: ignore from flags2_common import main, DownloadStatus, save_flag # low concurrency default to avoid errors from remote site, # such as 503 - Service Temporarily Unavailable DEFAULT_CONCUR_REQ = 5 MAX_CONCUR_REQ = 1000 async def get_flag(client: httpx.AsyncClient, # <1> similar to the sequential version, just that here it requires a client param base_url: str, cc: str) -> bytes: url = f'{base_url}/{cc}/{cc}.gif'.lower() resp = await client.get(url, timeout=3.1, follow_redirects=True) # <2> we await the coroutine from client.get() resp.raise_for_status() return resp.content async def download_one(client: httpx.AsyncClient, cc: str, base_url: str, semaphore: asyncio.Semaphore, verbose: bool) -> DownloadStatus: try: async with semaphore: # <3> semaphore as an asynchronous context manager so that the program as a whole is not blocked; only this coroutine is suspended when the semaphore counter is zero. image = await get_flag(client, base_url, cc) except httpx.HTTPStatusError as exc: # <4> familiar error handling logic res = exc.response if res.status_code == HTTPStatus.NOT_FOUND: status = DownloadStatus.NOT_FOUND msg = f'not found: {res.url}' else: raise else: await asyncio.to_thread(save_flag, image, f'{cc}.gif') # <5> FileSystem I/O, don't let it block us by running it in a thread status = DownloadStatus.OK msg = 'OK' if verbose and msg: print(cc, msg) return status # end::FLAGS2_ASYNCIO_TOP[] # tag::FLAGS2_ASYNCIO_START[] async def supervisor(cc_list: list[str], base_url: str, verbose: bool, concur_req: int) -> Counter[DownloadStatus]: # <1> since it's a coroutine, it can't be invoked directly from main. counter: Counter[DownloadStatus] = Counter() semaphore = asyncio.Semaphore(concur_req) # <2> creates the semaphore to be shared across the coros we will have async with httpx.AsyncClient() as client: to_do = [download_one(client, cc, base_url, semaphore, verbose) for cc in sorted(cc_list)] # <3> list of coro objs, one per call to download_one coro fn to_do_iter = asyncio.as_completed(to_do) # <4> get an iter, receives in the order of completion, allows the iter to be wrapped by tqdm if not verbose: to_do_iter = tqdm.tqdm(to_do_iter, total=len(cc_list)) # <5> wrap iter w tqdm error: httpx.HTTPError | None = None # <6> init error for coro in to_do_iter: # <7> iter over completed coro objs try: status = await coro # <8> this is a nonblocking await because implicitly guarded by the =as_completed= except httpx.HTTPStatusError as exc: error_msg = 'HTTP error {resp.status_code} - {resp.reason_phrase}' error_msg = error_msg.format(resp=exc.response) error = exc # <9> to preserve the exc except httpx.RequestError as exc: error_msg = f'{exc} {type(exc)}'.strip() error = exc # <10> preserve the exc except KeyboardInterrupt: break else: error = None if error: status = DownloadStatus.ERROR # <11> user internal error enum if verbose: url = str(error.request.url) # <12> cc = Path(url).stem.upper() # <13> print(f'{cc} error: {error_msg}') counter[status] += 1 return counter def download_many(cc_list: list[str], base_url: str, verbose: bool, concur_req: int) -> Counter[DownloadStatus]: coro = supervisor(cc_list, base_url, verbose, concur_req) counts = asyncio.run(coro) # <14> drives the event loop, passes coro to event loop and returns when the event loop ends. return counts if __name__ == '__main__': main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ) # end::FLAGS2_ASYNCIO_START[]- the
asyncio.semaphoreis being used as an asynchronous context manager so that the program as a whole is not blocked; only this coroutine is suspended when thesemaphorecounter is zero. - notice how we delegate the File I/O in point 5 to a threadpool provided by
asynciousingasyncio.to_thread, we justawaitit and yield the control flow to allow other threads to carry on
- the
Throttling Requests with a Semaphore
throwback to OS mods in school, semaphore numbered “mutex” \(\implies\) more flexibilty than just a binary mutex lock.
we can share the semaphore between multiple coroutines with a configured max number in order to throttle our Network I/O
why? because we should avoid spamming a server with too many concurrent requests \(\implies\) we need to throttle the Network I/O
previously, we did the throttling in a coarse manner by setting the
max_workersfor thedownload_manyin the demo code
Python’s Semaphores
all the 3 different concurrency structures (
threading,multiprocessing,asyncio) have their own semaphore classesinitial value set @ point of creating the semaphore, semaphore is passed to every coroutine that needs to rely on it to synchronize
semaphore = asyncio.Semaphore(concur_req)semaphore decrements when we
awaiton.acquire()coroutine, increments when we callrelease()method (non blocking, not a coroutine)if not ready (count
= 0), =.acquire()suspends the awaiting coroutine until some other coroutine calls.release()on the same Semaphore, thus incrementing the counter.asyncio.Semaphoreused as an async context manager:instead of using
semaphore.acquire()andsemaphore.release()directly, we can rely on the async context manager to acquire (Semaphore.__aenter__coroutine method await for.acquire()) and release the semaphore (Semaphore.__aexit__calls.release())this guarantees that no more than
concur_reqinstances ofget_flagscoroutines will be active at any time
Making Multiple Requests for Each Download
our objective now is to make 2 callbacks per country. In a sequential pattern, it would have been to just call one after the other. The async version isn’t directly the same.
We can drive the asynchronous requests one after the other, sharing the local scope of the driving coroutine.
here’s the v3 using asyncio
some changes:
new coroutine
get_countryis a new coroutine for the .json fetchdownload_onewe now useawaitto delegate toget_flagand the newget_country
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119#!/usr/bin/env python3 """Download flags of countries (with error handling). asyncio async/await version """ # tag::FLAGS2_ASYNCIO_TOP[] import asyncio from collections import Counter from http import HTTPStatus from pathlib import Path import httpx import tqdm # type: ignore from flags2_common import main, DownloadStatus, save_flag # low concurrency default to avoid errors from remote site, # such as 503 - Service Temporarily Unavailable DEFAULT_CONCUR_REQ = 5 MAX_CONCUR_REQ = 1000 async def get_flag(client: httpx.AsyncClient, # <1> base_url: str, cc: str) -> bytes: url = f'{base_url}/{cc}/{cc}.gif'.lower() resp = await client.get(url, timeout=3.1, follow_redirects=True) # <2> resp.raise_for_status() return resp.content # tag::FLAGS3_ASYNCIO_GET_COUNTRY[] async def get_country(client: httpx.AsyncClient, base_url: str, cc: str) -> str: # <1> returns string with country name url = f'{base_url}/{cc}/metadata.json'.lower() resp = await client.get(url, timeout=3.1, follow_redirects=True) resp.raise_for_status() metadata = resp.json() # <2> is a python dict return metadata['country'] # <3> erturns the country name # end::FLAGS3_ASYNCIO_GET_COUNTRY[] # tag::FLAGS3_ASYNCIO_DOWNLOAD_ONE[] async def download_one(client: httpx.AsyncClient, cc: str, base_url: str, semaphore: asyncio.Semaphore, verbose: bool) -> DownloadStatus: try: async with semaphore: # <1> hold the semaphore to =await= (delegate) to =get_flag= image = await get_flag(client, base_url, cc) async with semaphore: # <2> hold the semaphore again to delegate to the next step country = await get_country(client, base_url, cc) except httpx.HTTPStatusError as exc: res = exc.response if res.status_code == HTTPStatus.NOT_FOUND: status = DownloadStatus.NOT_FOUND msg = f'not found: {res.url}' else: raise else: filename = country.replace(' ', '_') # <3> await asyncio.to_thread(save_flag, image, f'{filename}.gif') status = DownloadStatus.OK msg = 'OK' if verbose and msg: print(cc, msg) return status # end::FLAGS3_ASYNCIO_DOWNLOAD_ONE[] # tag::FLAGS2_ASYNCIO_START[] async def supervisor(cc_list: list[str], base_url: str, verbose: bool, concur_req: int) -> Counter[DownloadStatus]: # <1> counter: Counter[DownloadStatus] = Counter() semaphore = asyncio.Semaphore(concur_req) # <2> async with httpx.AsyncClient() as client: to_do = [download_one(client, cc, base_url, semaphore, verbose) for cc in sorted(cc_list)] # <3> to_do_iter = asyncio.as_completed(to_do) # <4> if not verbose: to_do_iter = tqdm.tqdm(to_do_iter, total=len(cc_list)) # <5> error: httpx.HTTPError | None = None # <6> for coro in to_do_iter: # <7> try: status = await coro # <8> except httpx.HTTPStatusError as exc: error_msg = 'HTTP error {resp.status_code} - {resp.reason_phrase}' error_msg = error_msg.format(resp=exc.response) error = exc # <9> except httpx.RequestError as exc: error_msg = f'{exc} {type(exc)}'.strip() error = exc # <10> except KeyboardInterrupt: break if error: status = DownloadStatus.ERROR # <11> if verbose: url = str(error.request.url) # <12> cc = Path(url).stem.upper() # <13> print(f'{cc} error: {error_msg}') counter[status] += 1 return counter def download_many(cc_list: list[str], base_url: str, verbose: bool, concur_req: int) -> Counter[DownloadStatus]: coro = supervisor(cc_list, base_url, verbose, concur_req) counts = asyncio.run(coro) # <14> return counts if __name__ == '__main__': main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ) # end::FLAGS2_ASYNCIO_START[]- NOTE: point 1 & 2 in
download_one: it’s good practice to hold semaphores and locks for the shortest possible time.
One challenge is to know when you have to use
awaitand when you can’t use it.The answer in principle is easy: you await coroutines and other awaitables, such as
asyncio.Taskinstances.Reality is that the APIs can be confusingly named e.g.
StreamWriter
Delegating Tasks to Executors
problem: unlike NodeJS where ALL I/O has async APIs, python doesn’t have async APIs for all I/O. Notably, File I/O is NOT async.
This means that in our async code, file I/O can severly bottleneck performance if the main thread is blocked.
delegating to an executor is a good idea then
we can use
asyncio.to_threade.g.await asyncio.to_thread(save_flag, image, f'{cc}.gif')under the hood, it uses
loop.run_in_executor, so the equivalent to the above statement would be:1 2 3loop = asyncio.get_running_loop() # gets a reference to the event loop loop.run_in_executor(None, save_flag, image, f'{cc}.gif') # 1st Arg: Executor to use. None => default => ThreadPoolExecutor (always available in asyncio event loop)when using
run_in_executor, the 1st Arg is the Executor to use.None\(\implies\) default \(\implies\)ThreadPoolExecutor(always available in asyncio event loop)CAUTION: this accepts positional args, have to use
functool.partialif we wish to use kwargs. Or just use the newerasyncio.to_threadwhich will accept kwargs.IDIOM: this is a common pattern in async APIs:
wrap blocking calls that are implementation details in coroutines using run_in_executor internally. That way, you provide a consistent interface of coroutines to be driven with await, and hide the threads you need to use for pragmatic reasons.
loop.run_in_executor’s explicitExecutorallows us to use process-based approach for CPU-intensive tasks so that it’s a different python process and we avoid the GIL contention.TRICK / IDIOM: prime the
ProcessPoolExecutorin thesupervisorand then pass it to the coroutines that need it to reduce the effect of the high startup costs
WARNING / LANG_LIMITATION: Coroutines that use executors give the pretense of cancellation because the underlying thread/proc has no cancellation mechanism.
Using
run_in_executorcan produce hard-to-debug problems since cancellation doesn’t work the way one might expect. Coroutines that use executors give merely the pretense of cancellation: the underlying thread (if it’s aThreadPoolExecutor) has no cancellation mechanism.For example, a long-lived thread that is created inside a run_in_executor call may prevent your asyncio program from shutting down cleanly:
asyncio.runwill wait for the executor to fully shut down before returning, and it will wait forever if the executor jobs don’t stop somehow on their own.My greybeard inclination is to want that function to be
namedrun_in_executor_uncancellable.
Writing asyncio Servers
A FastAPI Web Service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36from pathlib import Path from unicodedata import name from fastapi import FastAPI from fastapi.responses import HTMLResponse from pydantic import BaseModel from charindex import InvertedIndex STATIC_PATH = Path(__file__).parent.absolute() / 'static' # <1> beautiful overloading of =/= for pathlib app = FastAPI( # <2> defines the ASGI app, params are for autogen docs title='Mojifinder Web', description='Search for Unicode characters by name.', ) class CharName(BaseModel): # <3> pydantic schema for runtime type checking char: str name: str def init(app): # <4> attach to app state for later use app.state.index = InvertedIndex() app.state.form = (STATIC_PATH / 'form.html').read_text() init(app) # <5> @app.get('/search', response_model=list[CharName]) # <6> search endpoint, response_model uses the CharName pydantic model to describe the response format async def search(q: str): # <7> non-path params within the coro signature chars = sorted(app.state.index.search(q)) return ({'char': c, 'name': name(c)} for c in chars) # <8> an iterable of dicts compatible with response_model schema => FastAPI can build the json response accoding to the response model that we supplied in the @app.get decorator @app.get('/', response_class=HTMLResponse, include_in_schema=False) def form(): # <9> can use regular functions to handle endpoints as well, not just coros return app.state.form # no main funcion # <10>endpoint handlers can be coros or plain functions like we see here.
there’s no
mainfunction, it’s loaded and driven by the ASGI server (uvicorn).we don’t have return type hints here because we allow the pydantic schema to do the job
this is like schema casting when defining changesets in elixir
model is declared in this parameter instead of as a function return type annotation, because the path function may not actually return that response model but rather return a dict, database object or some other model, and then use the response_model to perform the field limiting and serialization.
response_model in FastAPI + Pydantic plays the role of both serialization and field-whitelisting — taking arbitrary Python objects/dicts and producing clean, predictable outputs according to the model definition
by the way the inverted index was implemened like so:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88#!/usr/bin/env python """ Class ``InvertedIndex`` builds an inverted index mapping each word to the set of Unicode characters which contain that word in their names. Optional arguments to the constructor are ``first`` and ``last+1`` character codes to index, to make testing easier. In the examples below, only the ASCII range was indexed. The `entries` attribute is a `defaultdict` with uppercased single words as keys:: >>> idx = InvertedIndex(32, 128) >>> idx.entries['DOLLAR'] {'$'} >>> sorted(idx.entries['SIGN']) ['#', '$', '%', '+', '<', '=', '>'] >>> idx.entries['A'] & idx.entries['SMALL'] {'a'} >>> idx.entries['BRILLIG'] set() The `.search()` method takes a string, uppercases it, splits it into words, and returns the intersection of the entries for each word:: >>> idx.search('capital a') {'A'} """ import sys import unicodedata from collections import defaultdict from collections.abc import Iterator STOP_CODE: int = sys.maxunicode + 1 Char = str Index = defaultdict[str, set[Char]] def tokenize(text: str) -> Iterator[str]: """return iterator of uppercased words""" for word in text.upper().replace('-', ' ').split(): yield word class InvertedIndex: entries: Index def __init__(self, start: int = 32, stop: int = STOP_CODE): entries: Index = defaultdict(set) for char in (chr(i) for i in range(start, stop)): name = unicodedata.name(char, '') if name: for word in tokenize(name): entries[word].add(char) self.entries = entries def search(self, query: str) -> set[Char]: if words := list(tokenize(query)): found = self.entries[words[0]] return found.intersection(*(self.entries[w] for w in words[1:])) else: return set() def format_results(chars: set[Char]) -> Iterator[str]: for char in sorted(chars): name = unicodedata.name(char) code = ord(char) yield f'U+{code:04X}\t{char}\t{name}' def main(words: list[str]) -> None: if not words: print('Please give one or more words to search.') sys.exit(2) # command line usage error index = InvertedIndex() chars = index.search(' '.join(words)) for line in format_results(chars): print(line) print('─' * 66, f'{len(chars)} found') if __name__ == '__main__': main(sys.argv[1:])
An asyncio TCP Server (no deps, just
asynciostreams)- this demo is one where we use plain TCP to comms with a telnet/netcat client and using
asynciodirectly without any external dependencies!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78#!/usr/bin/env python3 # tag::TCP_MOJIFINDER_TOP[] import asyncio import functools import sys from asyncio.trsock import TransportSocket from typing import cast from charindex import InvertedIndex, format_results # <1> formatting useful for TUI via CLI telnet session CRLF = b'\r\n' PROMPT = b'?> ' async def finder(index: InvertedIndex, # <2> server expects a coro / function that only takes in teh reader and writer args. That's why we need to wrap it up in a partial reader: asyncio.StreamReader, writer: asyncio.StreamWriter) -> None: client = writer.get_extra_info('peername') # <3> remote client addr while True: # <4> handles a dialog until we get a control char (see break stmt below) writer.write(PROMPT) # can't await! # <5> this is not a CORO, just a plain function await writer.drain() # must await! # <6> flushes writer buffer, it's a coro that's why needs to be driven with =await= data = await reader.readline() # <7> coro that returns bytes if not data: # <8> no bytes => client closed the connection ==> break the loop break try: query = data.decode().strip() # <9> byte to string decoding except UnicodeDecodeError: # <10> replace with null char for simplicity (e.g. when keyboard interrupt then we get control bytes that can't be decoded into str) query = '\x00' print(f' From {client}: {query!r}') # <11> log stmt if query: if ord(query[:1]) < 32: # <12> kill loop if control or nullchar break results = await search(query, index, writer) # <13> delegate to searching coro print(f' To {client}: {results} results.') # <14> writer.close() # <15> close the writer steram await writer.wait_closed() # <16> wait for closing of stream print(f'Close {client}.') # <17>log # end::TCP_MOJIFINDER_TOP[] # tag::TCP_MOJIFINDER_SEARCH[] async def search(query: str, # <1> has to be a coro because we have to write to a StreamWriter and use its =.drain()= coro method index: InvertedIndex, writer: asyncio.StreamWriter) -> int: chars = index.search(query) # <2> query inverted index lines = (line.encode() + CRLF for line # <3> genexp gives char, name and CRLF in format_results(chars)) writer.writelines(lines) # <4> SURPRISE! this is NOT a coro await writer.drain() # <5> SURPRISE! this is a coro status_line = f'{"─" * 66} {len(chars)} found' # <6> status line to be written writer.write(status_line.encode() + CRLF) await writer.drain() return len(chars) # end::TCP_MOJIFINDER_SEARCH[] # tag::TCP_MOJIFINDER_MAIN[] async def supervisor(index: InvertedIndex, host: str, port: int) -> None: server = await asyncio.start_server( # <1> gets an instance of the server, creates and starts it so that it's ready to receive conns functools.partial(finder, index), # <2> =client_connected_cb=, a cb that is either a fn/coro needs to be supplied a stream reader and stream writer host, port) # <3> socket_list = cast(tuple[TransportSocket, ...], server.sockets) # <4> because typeshed type is outdated addr = socket_list[0].getsockname() print(f'Serving on {addr}. Hit CTRL-C to stop.') # <5> await server.serve_forever() # <6> suspends the supervisor. without this supervisor returns immediately def main(host: str = '127.0.0.1', port_arg: str = '2323'): port = int(port_arg) print('Building index.') index = InvertedIndex() # <7> index gets built try: asyncio.run(supervisor(index, host, port)) # <8> starts the event loop that will drive the supervisor coro except KeyboardInterrupt: # <9> catch CTRL-C print('\nServer shut down.') if __name__ == '__main__': main(*sys.argv[1:]) # end::TCP_MOJIFINDER_MAIN[]IDIOM @
finderpoint number 2;Use
functools.partialto bind that parameter and obtain a callable that takes the reader and writer. Adapting user functions to callback APIs is the most common use case forfunctools.partialhow multiple clients can be served at once:
While the event loop is alive, a new instance of the finder coroutine will be started for each client that connects to the server.
how the keyboard interrupt works
the interrupt signal will cause the raising of
KeyboardInterruptexception from within thesupervisor::server.serve_forever.event loop dies also.
This propagates out into the
mainfunction that had been driving the event loop.GOTCHA:
StreamWriter.writeis not a coro,StreamWriter.drainis a corosome of the I/O methods are coroutines and must be driven with await, while others are simple functions. For example,
StreamWriter.writeis a plain function, because it writes to a buffer. On the other hand,StreamWriter.drain— which flushes the buffer and performs the network I/O — is a coroutine, as isStreamReader.readline—but notStreamWriter.writelines!
- this demo is one where we use plain TCP to comms with a telnet/netcat client and using
Asynchronous Iteration and Asynchronous Iterables and using async for
async with\(\implies\) works with Async Context Managersasync for\(\implies\) asynchronous iterables:__aiter__that returns an async iterator BUT__aiter__is NOT as coro method, it’s a regular method
async iterator provides
__anext__coro method that returns an awaitable, usually a coro object. Just like the sync counterparts, expected to implement__aiter__which trivially returnsselfRemember same point about NOT mixing iterables and iterators
example:
aiopgasync postgres driver :1 2 3 4 5 6 7 8 9 10async def go(): pool = await aiopg.create_pool(dsn) async with pool.acquire() as conn: async with conn.cursor() as cur: # the cursor is the async iterator here await cur.execute("SELECT 1") ret = [] async for row in cur: # important to NOT block the event loop while cursor may be waiting for additional rows ret.append(row) assert ret == [(1,)]- By implementing the cursor as an asynchronous iterator,
aiopgmay yield to the event loop at each__anext__call, and resume later when more rows arrive from PostgreSQL.
- By implementing the cursor as an asynchronous iterator,
Asynchronous Generator Functions
Implementing and Using an async generator
Implementing an Async Iterator
class-implementation for async iterator: implement a class with
__anext__and__aiter__simpler way to implement an async iterator: as a generator function that is async \(\implies\) async generator
write a function declared with
async defand useyieldin its body. This parallels how generator functions simplify the classicIteratorpattern.
Usage of async generators:
Async generators can be used with
async for\(\Leftarrow\) driven byasync for:- as a block statement
- as async comprehensions
We can’t use typical for loops because async generators implement
__aiter__and NOT__iter__
Demo example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30import asyncio import socket from collections.abc import Iterable, AsyncIterator from typing import NamedTuple, Optional class Result(NamedTuple): # <1> convenience: easier to read and debug domain: str found: bool OptionalLoop = Optional[asyncio.AbstractEventLoop] # <2> typealias to clean up the hinting below async def probe(domain: str, loop: OptionalLoop = None) -> Result: # <3> if loop is None: # no current event loop handle in scope loop = asyncio.get_running_loop() try: await loop.getaddrinfo(domain, None) except socket.gaierror: return Result(domain, False) return Result(domain, True) async def multi_probe(domains: Iterable[str]) -> AsyncIterator[Result]: # <4> Async Generator function returns an async generator object, that's why it's typed like that loop = asyncio.get_running_loop() coros = [probe(domain, loop) for domain in domains] # <5> list of proble coros for coro in asyncio.as_completed(coros): # <6> this is a classic generator, that's why we can drive it using =for= and not =async for= result = await coro # <7> guarded by the =as_completed= not to worry that it will be actually blocking. yield result # <8> this is what makes multiproble an async generator
The result is yielded by
multi_probe, which is what makesmulti_probean async generatorShortcut to the for loop:
1 2for coro in asyncio.as_completed(coros): yield await coroTRICK: The
.invalidtop-level domain is reserved for testing.see elaboration here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43Yes, the statement is **true**. The **`.invalid` top-level domain (TLD) is reserved specifically for testing and use in examples or scenarios where a guaranteed invalid domain is needed**. It is defined as a special-use domain name by the Internet Engineering Task Force (IETF) in [RFC 2606 (1999)](https://www.rfc-editor.org/rfc/rfc2606.html) and officially reserved by the Internet Assigned Numbers Authority (IANA). ### Key points on `.invalid` TLD reservation: - The `.invalid` TLD **cannot appear in the global DNS root zone** to avoid conflicts with existing or future valid TLDs. - It is intended to be used in tests, documentation, or example scenarios where domain names must be constructed clearly as invalid or guaranteed to not resolve. - Alongside `.invalid`, other reserved TLDs for similar "safe" use are `.test`, `.example`, and `.localhost`. - Using `.invalid` in software or test settings helps catch or demonstrate domain resolution failures without accidentally affecting real domains. - Because of this reservation, any use of `.invalid` as a real domain name should not expect it to resolve on the public internet. ### Supporting authoritative references: - **RFC 2606 (Reserved Top Level DNS Names)** states: > "`.invalid` is intended for use in online construction of domain names that are sure to be invalid and which it is obvious at a glance are invalid." - [Wikipedia: .invalid](https://en.wikipedia.org/wiki/.invalid) also confirms this reservation by IETF for such use. - IANA maintains `.invalid` as one of the reserved special-use domain names unlikely to ever be delegated. ### Summary table | Domain | Purpose | Delegated in global DNS? | Use Case | |----------------|-----------------------------------|-------------------------|-------------------------------------------------| | `.invalid` | Reserved for invalid/test domains | No | Testing, documentation, avoiding domain clashes | | `.test` | Reserved for testing | No | Test environments | | `.example` | Reserved for examples | No | Documentation and examples | | `.localhost` | Reserved for loopback services | No | Localhost network reference | *** In conclusion, your quoted **TRICK** that `.invalid` is a top-level domain reserved for testing is **correct and reflects Internet standards**. If you want, I can provide more background on reserved TLDs, best practices for using them in networking or development, or how they differ from other special-use or reserved names. Just let me know! [1] https://en.wikipedia.org/wiki/.invalid [2] https://skynethosting.net/blog/what-is-invalid-tlds/ [3] https://datatracker.ietf.org/doc/rfc2606/ [4] https://www.rfc-editor.org/rfc/rfc2606.html [5] https://domaintyper.com/invalid-domain [6] https://stackoverflow.com/questions/4128351/is-there-a-valid-domain-name-guaranteed-to-be-unreachable [7] https://circleid.com/posts/20090618_most_popular_invalid_tlds_should_be_reserved [8] https://news.ycombinator.com/item?id=15268822 [9] https://en.wikipedia.org/wiki/Top-level_domainUsing the async generator:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24#!/usr/bin/env python3 import asyncio import sys from keyword import kwlist from domainlib import multi_probe async def main(tld: str) -> None: tld = tld.strip('.') names = (kw for kw in kwlist if len(kw) <= 4) # <1> domains = (f'{name}.{tld}'.lower() for name in names) # <2> print('FOUND\t\tNOT FOUND') # <3> print('=====\t\t=========') async for domain, found in multi_probe(domains): # <4> async iterate over the async generator indent = '' if found else '\t\t' # <5> print(f'{indent}{domain}') if __name__ == '__main__': if len(sys.argv) == 2: asyncio.run(main(sys.argv[1])) # <6> else: print('Please provide a TLD.', f'Example: {sys.argv[0]} COM.BR')
Async generators as context managers
Generators (sync and async versions) have one extra use unrelated to iteration: they can be made into context managers.
We can use the
@asynccontextmanagerdecorator within thecontextlibmoduleSimilar to its sync counterpart
@contextmanager1 2 3 4 5 6 7 8 9 10 11 12 13 14from contextlib import asynccontextmanager @asynccontextmanager async def web_page(url): # the function to be decorated has to be an async generator loop = asyncio.get_running_loop() data = await loop.run_in_executor( None, download_webpage, url) # we run in a separate thread in case this is a blocking function; keeps out event loop unblocked yield data # this makes it an async generator await loop.run_in_executor(None, update_stats, url) async with web_page('google.com') as data: process(data)Outcome
similar to the sync version, all lines before the
yieldbecome the entry code,__aenter__coro method of the async context manager that is built by the decorator. So, when control flow comes back to this, the value ofdatawill be bound to thedatatarget variable that is associated with the context manager below.All lines after
yieldbecome the__aexit__coro method. Another possibly blocking call is delegated to the thread executor.
Asynchronous generators versus native coroutines
Similarities
async deffor both
Differences
async generator has a
yieldin its body but not a native coroutineasync generator can ONLY have
emptyreturn statements BUT a naive coro may return a value other thanNoneAsync generators are NOT awaitable, they are iterables so are driven by
async foror async comprehensionsmeanwwhile, native coros are awaitable. Therefore:
can be driven by
awaitexpressionscan be passed to
asynciofunctions that consume awaitables (e.g.create_task)
Async Comprehensions and Async Generator Expressions
Async generator expressions
Here’s how we can define and use one:
1 2 3 4gen_found = (name async for name, found in multi_probe(names) if found) # the async genexpr builds the async generator (async iterator) obj async for name in gen_found: # driven by the async for print(name)- an asynchronous generator expression can be defined anywhere in your program, but it can only be consumed inside a native coroutine or asynchronous generator function.
Async comprehensions
we can have the usual kind of comprehensions done async! just need to make sure that it’s within an async context i.e. within an
async defor within an async REPL console.async listcomps:
result = [i async for i in aiter() if i % 2]which is actually similar toasyncio.gather()just a little less flexible. gather function allows us to do better exception handling.async dictcomps:
{name: found async for name, found in multi_probe(names)}async setcomps:
{name for name in names if (await probe(name)).found}the extra parentheses is because
__getattr__operator,.has operator precedence there
async Beyond asyncio: Curio
async/awaitconstructs are library agnosticcurio blogdom demo example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28#!/usr/bin/env python3 from curio import run, TaskGroup import curio.socket as socket from keyword import kwlist MAX_KEYWORD_LEN = 4 async def probe(domain: str) -> tuple[str, bool]: # <1> no need to receive event loop try: await socket.getaddrinfo(domain, None) # <2> getaddrinfo is top-level fn of the curio.socket, it's not a method of a loop object like it is in asyncio except socket.gaierror: return (domain, False) return (domain, True) async def main() -> None: names = (kw for kw in kwlist if len(kw) <= MAX_KEYWORD_LEN) domains = (f'{name}.dev'.lower() for name in names) async with TaskGroup() as group: # <3> core concept in curio monitors and controls a group of tasks (coros) for domain in domains: await group.spawn(probe, domain) # <4> we spawn to start a coro, managed by a particular TaskGroup instance. Coro is wrapped by a Task within the TaskGroup async for task in group: # <5> yields as it's completed, like =as_completed= domain, found = task.result mark = '+' if found else ' ' print(f'{mark} {domain}') if __name__ == '__main__': run(main()) # <6> sensible syntaxTaskGroupCurio
TaskGroupis an asynchronous context manager that replaces several ad hoc APIs and coding patterns inasyncio.above we saw how we can just drive the group and we get things in the order of completion, analogous to
asyncio.as_completedwe can also gather them all easily:
1 2 3async with TaskGroup(wait=all) as g: await g.spawn(coro1) await g.spawn(coro2)TaskGroupas a support for structured concurrency:adds a constraint to concurrent programming:
a group of async tasks should have a single entry and single exit point.
as an asynchronous context manager, a
TaskGroupensures that all tasks spawned inside are completed or cancelled, and any exceptions raised, upon exiting the enclosed block.just like how structured programming advised against the use of
GOTOstatements
seems like asyncio has some partial support for structured concurrency since 3.11, e.g. with TaskGroups…
Curio also provides a UniversalQueue that can be used to coordinate the work among threads, Curio coroutines, and asyncio coroutines.
Type Hinting Asynchronous Objects
the return type of native coroutine == the type of result it spits out when you await on it
different from annotations for classic coroutines, where it’s the 3-paramed Generator type
3 points about typing:
all the async objects are all covariant on the first type parameter, which is the type of the items yielded from these objects. Aligns with the “producer” / output types being covariant.
AsyncGeneratorandCoroutineare contravariant on the second to last parameter. That’s because they are output types and output types are contravariant.AsyncGeneratorhas no return typewhen we saw
typing.Generator, we realised how we could return values by hacking theStopIteration(value)and that’s how generator-enhanced classic coroutines were hacked out, which is why we could make generators operate as classic coroutines and supportyield fromNo such thing for
AsyncGeneratorAsyncGeneratorobjects don’t return values, and are completely separate from native coroutine objects, which are annotated withtyping.Coroutine
How Async Works and How It Doesn’t
Running Circles Around Blocking Calls
- IO is god damn slow, if we async in a disciplined manner then our servers would be high-performance
The Myth of I/O-Bound Systems
there are “I/O bound functions” but no “I/O bound systems”
any nontrivial system will have CPU-bound functions, dealing with them is the key to success in async programming
Avoiding CPU-Bound Traps
- should have performance regression tests
- important with async code, but also relevant to threaded Python code because of the GIL
- we should not OBSERVE slowdown (by that time it’s too late) because the direct performance hit bad patterns are less likely to be humanly observable (until it’s too late).
What to do if we see a CPU-hogging bottleneck:
- delegate task to a python proc pool
- delegate task to external task queue
- avoid GIL constraints, rewrite code in Cython, C, Rust – anything that interfaces with the Python/C API
- choose to do nothing
Chapter Summary
- don’t block the event loop, delegate to different processing unit (thread, proc, task queue)
Further Reading
Part V. Metaprogramming
Chapter 22. Dynamic Attributes and Properties
What’s New in This Chapter
Data Wrangling with Dynamic Attributes
- Exploring JSON-Like Data with Dynamic Attributes
- The Invalid Attribute Name Problem
- Flexible Object Creation with new
Computed Properties
- Step 1: Data-Driven Attribute Creation
- Step 2: Property to Retrieve a Linked Record
- Step 3: Property Overriding an Existing Attribute
- Step 4: Bespoke Property Cache
- Step 5: Caching Properties with functools
Using a Property for Attribute Validation
- LineItem Take #1: Class for an Item in an Order
- LineItem Take #2: A Validating Property
A Proper Look at Properties
- Properties Override Instance Attributes
- Property Documentation
Coding a Property Factory
Handling Attribute Deletion
Essential Attributes and Functions for Attribute Handling
- Special Attributes that Affect Attribute Handling
- Built-In Functions for Attribute Handling
- Special Methods for Attribute Handling
Chapter Summary
Further Reading
Chapter 23. Attribute Descriptors
What’s New in This Chapter
Descriptor Example: Attribute Validation
- LineItem Take #3: A Simple Descriptor
- LineItem Take #4: Automatic Naming of Storage Attributes
- LineItem Take #5: A New Descriptor Type
Overriding Versus Nonoverriding Descriptors
- Overriding Descriptors
- Overriding Descriptor Without get
- Nonoverriding Descriptor
- Overwriting a Descriptor in the Class
Methods Are Descriptors
Descriptor Usage Tips
Descriptor Docstring and Overriding Deletion
Chapter Summary
Further Reading
Chapter 24. Class Metaprogramming
What’s New in This Chapter
Classes as Objects
type: The Built-In Class Factory
A Class Factory Function
Introducing init_subclass
- Why init_subclass Cannot Configure slots
Enhancing Classes with a Class Decorator
What Happens When: Import Time Versus Runtime
- Evaluation Time Experiments
Metaclasses 101
- How a Metaclass Customizes a Class
- A Nice Metaclass Example
- Metaclass Evaluation Time Experiment
A Metaclass Solution for Checked
Metaclasses in the Real World
- Modern Features Simplify or Replace Metaclasses
- Metaclasses Are Stable Language Features
- A Class Can Only Have One Metaclass
- Metaclasses Should Be Implementation Details
A Metaclass Hack with prepare
Wrapping Up
Chapter Summary
Further Reading
Legend
In these notes, I add some tags once in a while:
TRICK: pythonic tricks
IDIOM: Pythonic Idioms that are great
sometimes, I also use the tag RECIPE for similar points.
TO_HABIT: for things I should add to my own habits when I’m writing python
MISCONCEPTION: some misconception that I had had.
LANG_LIMITATION: is a point that outlines a limitation in python
TODO pending tasks
TODO Skipped Parts of the Book [0/2]
[ ] ControlFlow::Chapter18::lis.py
[ ] Metaprogramming
TODO watch list:
[ ] what makes python awesome by Raymond Hettinger
[ ] “Fear adn Awaiting in Async” PyOhio 2016 by David Beazley
[ ] Advanced asyncio: Solving Real-world Production Problems using python (staff eng @ spotify)
TODO add in some recipes that will help for Leetcode [0/1]
[ ] Table slicing
Extras blog post for the book (ref)
this is where a bunch of extra material has been included that couldn’t be included in the book